





原文地址:https://arxiv.org/html/2410.00907
简单来说该论文提出了一种方法用于替代大型神经网络中浮点张量的乘法,该方法具有更高的精确度和更低的计算量。
下文给出论文各部分的粗略理解
指数部分乘法优化
一个nbits, e位指数, m位底数的浮点运算为
Mul ( x , y ) = ( 1 + x m ) ⋅ 2 x e ⋅ ( 1 + y m ) ⋅ 2 y e = ( 1 + x m + y m + x m ⋅ y m ) ⋅ 2 x e + y e \text{Mul}(x, y) = (1 + x^m) \cdot 2^{x^e} \cdot (1 + y^m) \cdot 2^{y^e}\\= (1 + x^m + y^m + x^m \cdot y^m) \cdot 2^{x^e + y^e} Mul(x,y)=(1+xm)⋅2xe⋅(1+ym)⋅2ye=(1+xm+ym+xm⋅ym)⋅2xe+ye
在该运算中,瓶颈复杂度来源于
x
m
⋅
y
m
x^m \cdot y^m
xm⋅ym 复杂度为O(m^2)
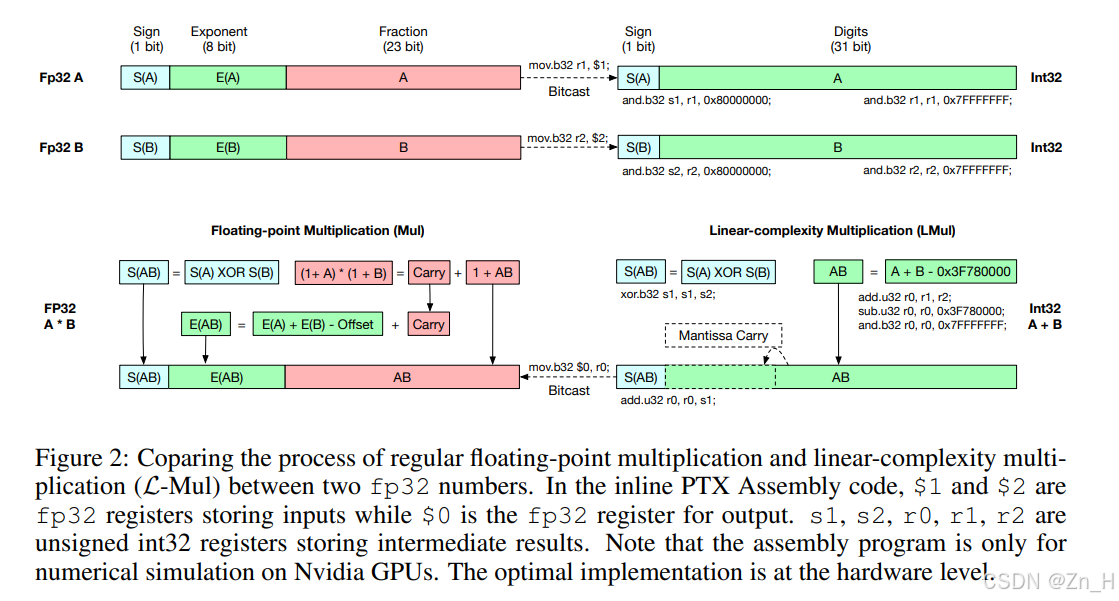
论文将该操作替换为一个新的乘法算法:
L-Mul
(
x
,
y
)
=
(
1
+
x
m
+
y
m
+
2
−
l
(
m
)
)
⋅
2
x
e
+
y
e
\text{L-Mul}(x, y) = \left(1 + x^m + y^m + 2^{-l(m)}\right) \cdot 2^{x^e + y^e}
L-Mul(x,y)=(1+xm+ym+2−l(m))⋅2xe+ye
l
(
m
)
=
{
m
if
m
≤
3
,
3
if
m
=
4
,
4
if
m
>
4.
l(m) =\begin{cases}m& \text{if } m \leq 3,\\3 & \text{if } m = 4,\\4& \text{if } m > 4.\end{cases}
l(m)=⎩
⎨
⎧m34if m≤3,if m=4,if m>4.
该算法复杂度为O(m)
此外,在传统浮点乘法器中,如果尾数和大于2,则需要手动舍位到1.x
而使用该方法时,除了尾数乘法,还跳过了手动舍位
基于L-Mul的注意力机制
K = H ⋅ W k , Q = H ⋅ W q , V = H ⋅ W V A = s o f t m a x [ L − m a t m u l ( Q , K T ) d ] , H ′ = L − m a t m u l ( A , H ) K=H\cdot W_{k},Q= H \cdot W_{q}, V=H \cdot W_{V}\\A=softmax \left[ \frac{\mathcal{L}-matmul(Q,K^{T})}{\sqrt{d}}\right],H^{'}=\mathcal{L}-matmul(A,H) K=H⋅Wk,Q=H⋅Wq,V=H⋅WVA=softmax[dL−matmul(Q,KT)],H′=L−matmul(A,H)
给出准确度和消耗分析
L − m u l \mathcal{L}-mul L−mul比 f p 8 _ e 4 m 3 fp8\_e4m3 fp8_e4m3更精确,比 f p _ e 5 m 2 fp\_e5m2 fp_e5m2计算量更低
考虑
x
=
(
1
+
x
m
)
⋅
2
x
e
x=(1 + x_m) \cdot 2^{x^e}
x=(1+xm)⋅2xe和
y
=
(
1
+
y
m
)
⋅
2
y
e
y=(1 + y_m) \cdot 2^{y^e}
y=(1+ym)⋅2ye
如果拆解为
x
=
(
1
+
x
k
+
x
r
)
⋅
2
x
e
,
x
′
=
(
1
+
x
k
)
⋅
2
x
e
x=(1 + x_k+x_r) \cdot 2^{x^e},x^{'}=(1 + x_k) \cdot 2^{x^e}
x=(1+xk+xr)⋅2xe,x′=(1+xk)⋅2xe
y
=
(
1
+
y
k
+
y
r
)
⋅
2
y
e
,
y
′
=
(
1
+
y
k
)
⋅
2
y
e
y=(1 + y_k+y_r) \cdot 2^{y^e},y^{'}=(1 + y_k) \cdot 2^{y^e}
y=(1+yk+yr)⋅2ye,y′=(1+yk)⋅2ye
其中
x
k
,
y
k
x_k,y_k
xk,yk是
x
m
,
y
m
x_m,y_m
xm,ym的前
k
k
k位,
x
r
,
y
r
x_r,y_r
xr,yr是
k
k
k位取整后被忽略的值。
考虑
x
x
x和
y
y
y具有
m
m
m位尾数的全部精度,比如Float16的尾数为10-bit,BFloat16尾数为7. 那么
M
u
l
(
x
,
y
)
Mul(x,y)
Mul(x,y)的误差和期望为
e
m
u
l
k
=
M
u
l
(
x
,
y
)
−
M
u
l
(
x
′
,
y
′
)
=
(
x
k
y
r
+
y
k
x
r
+
x
r
+
y
r
+
x
r
y
r
)
⋅
2
x
e
+
y
e
e^{k}_{mul}= Mul(x,y)-Mul(x^{'},y^{'})=(x_{k}y_{r}+y_{k}x_{r}+x_{r}+y_{r}+x_{r}y_{r})\cdot2^{x_{e}+y_{e}}
emulk=Mul(x,y)−Mul(x′,y′)=(xkyr+ykxr+xr+yr+xryr)⋅2xe+ye
E
[
e
m
u
l
k
]
=
f
1
(
m
,
k
)
⋅
E
[
2
x
e
+
y
e
]
E[e^{k}_{mul}]=f_{1}(m,k)\cdot E[2^{x_{e}+y_{e}}]
E[emulk]=f1(m,k)⋅E[2xe+ye]
则期望的误差为
E
[
e
l
m
u
l
k
]
−
E
[
e
m
u
l
k
]
=
f
2
(
k
)
⋅
E
[
2
e
x
+
e
y
]
,
E
[
e
l
m
u
l
k
]
=
[
f
1
(
m
,
k
)
+
f
2
(
k
)
]
⋅
E
[
2
e
x
+
e
y
]
E[e^{k}_{lmul}]-E[e^{k}_{mul}]=f_2(k)\cdot E[2^{e_x+e_y}], E[e^{k}_{lmul}]=[f_1(m,k)+f_2(k)]\cdot E[2^{e_x+e_y}]
E[elmulk]−E[emulk]=f2(k)⋅E[2ex+ey],E[elmulk]=[f1(m,k)+f2(k)]⋅E[2ex+ey]
当
x
m
,
y
m
x_m,y_m
xm,ym均匀分布时
E
[
x
k
]
=
1
2
(
1
−
2
−
k
)
,
E
[
x
r
]
=
1
2
(
2
−
k
−
2
−
m
)
E[x_k]=\frac{1}{2} (1-2^{-k}), E[x_r]=\frac{1}{2}(2^{-k}-2^{-m})
E[xk]=21(1−2−k),E[xr]=21(2−k−2−m)
通过估计
f
1
(
m
,
k
)
,
f
2
(
k
)
f_1(m,k),f_2(k)
f1(m,k),f2(k)并推断
E
[
e
k
l
m
u
l
]
,
E
[
e
k
m
u
l
]
E[e^{k}{lmul}], E[e^{k}{mul}]
E[eklmul],E[ekmul],论文发现
L
−
M
u
l
\mathcal{L}-Mul
L−Mul在均匀分布下精度超过
f
p
_
e
5
m
2
fp\_e5m2
fp_e5m2。然而在预训练的LLMs中实际权重分布往往存在偏差。基于五种常用LLMs的组合分布,论文发现
L
−
M
u
l
\mathcal{L}-Mul
L−Mul在5-bit尾数操作数下精度超过
f
p
_
e
4
m
3
fp\_e4m3
fp_e4m3。 并给出了误差估计表:

门复杂度估计:
对于两个fpn_eimj数相乘需要:
- sign prediction,符号预测
- exponent addition with offset, 整数部分加法和进位
- a j+1-bitmantissa multiplication, 尾数乘法
- exponent rounding. 整数部分取整
尾数乘法需要(j+1)^{2} ADD操作,3个半加器,和2j-2全加器。
取整需要i个半加器,
一个全加器需要2AND,2XOR,1OR,每个XOR需要4NAND,也就是最后需要11个门器件。而一个半加器需要5个门器件。
最后的统计结果约为:
N
f
p
16
×
≈
584
,
N
f
p
8
−
e
4
m
3
×
≈
325
,
N
f
p
8
−
e
5
m
2
×
≈
296
N^{\times}_{fp16}\approx 584, N^{\times}_{fp8-e4m3}\approx325, N^{\times}_{fp8-e5m2}\approx296
Nfp16×≈584,Nfp8−e4m3×≈325,Nfp8−e5m2×≈296
而
N
e
i
m
j
L
−
m
u
l
=
N
1
⊕
+
N
i
n
t
(
i
+
j
)
+
+
N
i
n
t
8
+
N^{\mathcal{L}-mul}_{eimj}=N^{\oplus}_{1}+N^{+}_{int(i+j)}+N^{+}_{int8}
NeimjL−mul=N1⊕+Nint(i+j)++Nint8+
所以
N
f
p
16
L
−
m
u
l
≈
256
,
N
f
p
8
L
−
m
u
l
≈
157
N^{\mathcal{L}-mul}_{fp16}\approx256, N^{\mathcal{L}-mul}_{fp8}\approx157
Nfp16L−mul≈256,Nfp8L−mul≈157
实验部分省略
介绍一下论文中的related works,介绍神经网络轻量化的典型思路。
1.修剪,减少层间连接数。确定重要的权重,然后重新训练以更新特定任务所选择的权重。\mathcal{L}-Mul针对一般任务设计,不需要针对特定任务再训练。
2.优化张量I/O。在SRAM和HBM(高带宽内存)间移动张量是时间和能量消耗的主要瓶颈。减少transformer中的I/O操作并充分利用HBM可以显著提高AI训练和推理的效率。\mathcal{L}-Mul与该方法正交。
3.取整和量化。标准张量格式为16bit或32bit。然而全尺寸的权重需要相当多的GPU内存。为了提高存储效率,权重存储和计算都可以在较低精度下进行,例如使用16bit、8bit、4bit FP 和Int。比如fp16,bf16,fp8-e4m3,fp8-e5m2,int8,fp4,int4张量来表达模型权重。 与这类方法相比,\mathcal{L}-Mul具有更高的精度和更低的计算量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









