







根据brazilian-ecommerce-public-archive上的数据做Sales Prediction
导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
from scipy.stats import kstest
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split,KFold,cross_val_score,GridSearchCV,RandomizedSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
导入数据
customers = pd.read_csv("./olist_customers_dataset.csv")
sellers = pd.read_csv("./olist_sellers_dataset.csv")
order_reviews = pd.read_csv("./olist_order_reviews_dataset.csv")
order_items = pd.read_csv("./olist_order_items_dataset.csv")
products = pd.read_csv("./olist_products_dataset.csv")
geolocation = pd.read_csv("./olist_geolocation_dataset.csv")
product_category_name = pd.read_csv("./product_category_name_translation.csv")
orders = pd.read_csv("./olist_orders_dataset.csv")
order_payments = pd.read_csv("./olist_order_payments_dataset.csv")
合并要用到的数据集
order_items = pd.merge(order_items,sellers[['seller_id', 'seller_zip_code_prefix']],on='seller_id')
# Delete useless features
order_items= order_items.drop(['order_item_id','shipping_limit_date'], axis=1)
merge_df = pd.merge(orders,customers,on='customer_id',how='left')
merge_df = merge_df[['order_id','customer_unique_id','customer_city','order_purchase_timestamp']]
tem_df = pd.merge(order_items,products,on='product_id',how='left')
tem_df = tem_df[['order_id','product_id','price','product_length_cm', 'product_height_cm', 'product_width_cm','product_category_name']]
merge_df = pd.merge(merge_df,tem_df,on='order_id',how='left')
删除重复值
merge_df[merge_df.duplicated()]
merge_df.drop_duplicates(inplace=True)
处理数据
merge_df['order_purchase_timestamp'] = pd.to_datetime(merge_df['order_purchase_timestamp']).dt.date
dayly_sales = merge_df.groupby('order_purchase_timestamp',as_index=False)['price'].sum()
merge_df.index = merge_df['order_purchase_timestamp']
merge_df.sort_index(inplace=True)
merge_df.drop('order_purchase_timestamp',axis=1,inplace=True)
new_df = merge_df.groupby('order_purchase_timestamp')[['price','customer_unique_id','customer_city']].agg({'price':'sum','customer_unique_id':'nunique','customer_city':'nunique'})
new_df['date'] = list(new_df.index)
new_df['date'] = pd.to_datetime(new_df['date'])
new_df['year'] = new_df['date'].dt.year
new_df['month'] = new_df['date'].dt.month
new_df['day'] = new_df['date'].dt.day
# Filter data
new_df = new_df[new_df['date']>='2017']
计算特征之间的相关性
corr = new_df.corr()
new_df = new_df.rename({'price':'sales'},axis='columns')
new_df = new_df.reset_index(drop=True)
corr
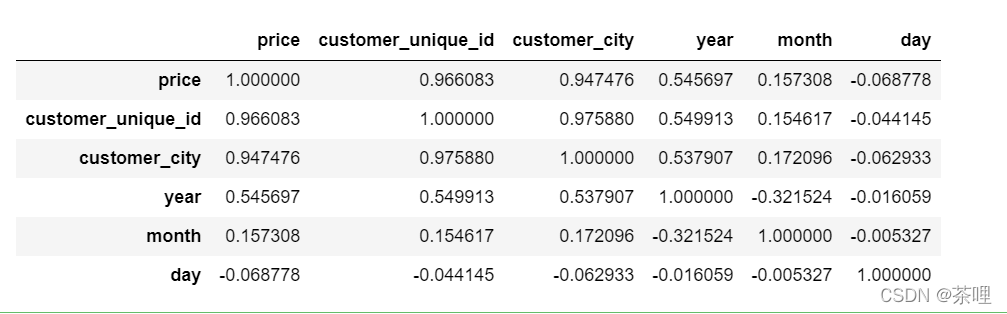
画出热力图
plt.figure(figsize=(8,6))
plt.title('Heatmap of All Features')
sns.heatmap(new_df.corr(),annot=True)
plt.show()
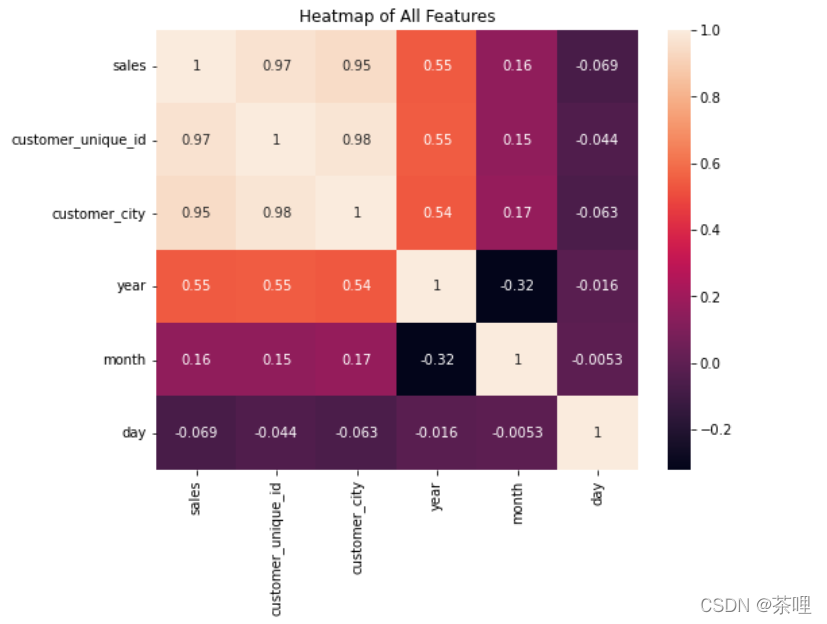
画出折线图
plt.figure(figsize=(8,6))
plt.title('Sales')
plt.plot(new_df['date'],new_df['sales'])
plt.xticks(rotation=30)
plt.show()
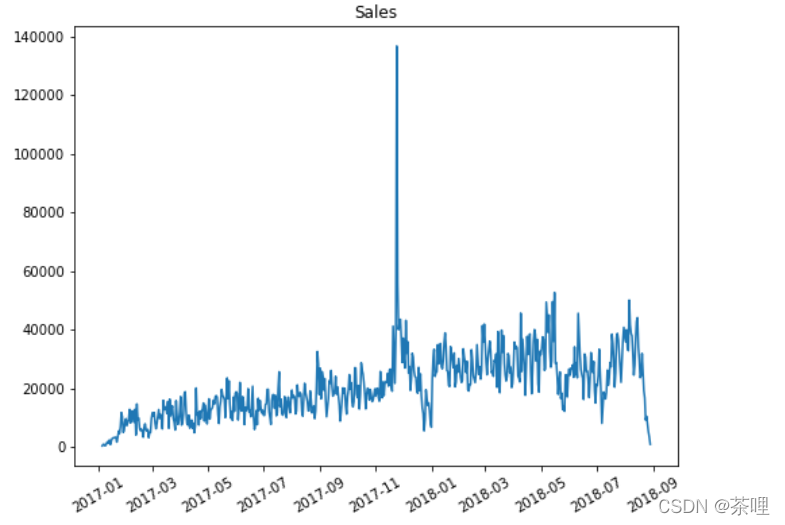
某个月数据太突出,做一下平滑
std3 = new_df['sales'].std()*3
for i in range(new_df.shape[0]):
if new_df.loc[i,'sales']>std3:
new_df.loc[i,'sales'] = std3
建立RandomForestRegressor and XGBRegressor模型
x_train,x_test,y_train,y_test = train_test_split(new_df.drop(['sales','date'],axis=1),new_df['sales'],test_size=0.2,random_state=1)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
print("x_train.shape",x_train.shape)
print("x_test.shape",x_test.shape)
rfr = RandomForestRegressor(n_estimators=500
,random_state=1
,max_depth=10
,min_samples_split=10
,min_samples_leaf=2)
rfr.fit(x_train,y_train)
predict = rfr.predict(x_test)
kfold = KFold(n_splits=5, shuffle=True)
results_=cross_val_score(rfr,new_df.drop(['sales','date'],axis=1),new_df['sales'], cv=kfold)
print("RandomForestRegressor Accuracy:",results_.mean())
print("RandomForestRegressor MAE:",mean_absolute_error(predict, y_test))

xgb = XGBRegressor(n_estimators=500
,random_state=1
,learning_rate=0.05
,max_depth=10)
xgb.fit(x_train, y_train)
predictions = xgb.predict(x_test)
mae = mean_absolute_error(predictions, y_test)
results=cross_val_score(xgb,new_df.drop(['sales','date'],axis=1),new_df['sales'], cv=kfold)
print("XGBRegressor Accuracy:",results.mean())
print("XGBRegressor MAE:",mae)

参数调优
n_estimators_interval=[50,100,200,300,400,500,600]
min_samples_split_interval=[2,5,10]
min_samples_leaf_interval=[2,4,8]
max_features_interval=['auto','sqrt']
max_depth_interval=[10,20,30]
max_depth_interval.append(None)
rfr_interval={'n_estimators':n_estimators_interval,
'min_samples_split':min_samples_split_interval,
'min_samples_leaf':min_samples_leaf_interval,
'max_features':max_features_interval,
'max_depth':max_depth_interval
}
random_state_interval = np.random.randint(low=1,high=20)
random_forest_model = RandomizedSearchCV(estimator=rfr,param_distributions=rfr_interval,random_state=random_state_interval)
random_forest_model.fit(x_train, y_train)
print(random_forest_model.best_params_)
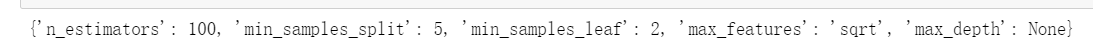
选择最优参数,再次训练
rfr_best = RandomForestRegressor(n_estimators=100
,random_state=1
,max_depth=None
,min_samples_split=5
,min_samples_leaf=2
,max_features='sqrt')
rfr_best.fit(x_train,y_train)
predict = rfr_best.predict(x_test)
results_=cross_val_score(rfr,new_df.drop(['sales','date'],axis=1),new_df['sales'], cv=kfold)
print("Best RandomForestRegressor Accuracy:",results_.mean())
print("Best RandomForestRegressor MAE:",mean_absolute_error(predict, y_test))

相比没有调优,只提升了一点。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











