






 本文介绍了轮廓系数作为聚类效果的评估方法,包括其计算原理、Python实现示例。同时探讨了最小化惯性(WCSS)在k-means中的应用,以及完整性分数、同质性分数和调整后的兰德系数等聚类性能指标。
本文介绍了轮廓系数作为聚类效果的评估方法,包括其计算原理、Python实现示例。同时探讨了最小化惯性(WCSS)在k-means中的应用,以及完整性分数、同质性分数和调整后的兰德系数等聚类性能指标。
一、 轮廓系数(Silhouette Coefficient)
轮廓系数用于判断聚类结果的紧密度和分离度。轮廓系数综合了样本与其所属簇内的相似度以及最近的其他簇间的不相似度。
其计算方法如下:
1、计算簇中的每个样本i
1.计算a(i) :样本i到同簇内其他样本的平均距离,代表样本i的簇内相似度。a(i)的值越小,说明样本i越应该被聚类到该簇,簇内相似度越高。
2.计算b(i):样本i到其他簇内的所有样本的平均距离的最小值,代表样本i的簇间不相似度。b(i)值越大,说明样本i越不应该被聚类到其他簇。
2、计算轮廓系数
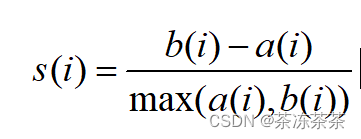
3、轮廓系数分析
轮廓系数的取值范围在[-1,1]之间,系数越大,说明聚类效果越好,簇内相似度越高,簇间差异性越大。
4、Python实现例子
import numpy as np
from scipy.spatial.distance import cdist
data = np.random.rand(1000,10)
def KMeans(X,k,max_iters=100):
indices = np.random.choice(X.shape[0],k,replace=False)
centroids = X[indices]
for _ in range(max_iters):
distance = np.linalg.norm(X[:,np.newaxis] - centroids,axis=2)
labels = np.argmin(distance,axis=1)
new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(k)])
if np.all(centroids == new_centroids):
break
centroids = new_centroids
return centroids,labels
def silhouette_score(X,label):
n_samples = X.shape[0]
silhouette_avg = 0.0
for i in range(n_samples):
label = labels[i]
a = np.mean([cdist(X[i].reshape(1,-1),X[labels == label],'euclidean')[0,1:]])
b_values = []
for j in set(labels)-{label}:
b_values.append(np.min(cdist(X[i].reshape(1,-1),X[labels==j],'euclidean')[0]))
b = np.mean(b_values)
s = (b-a)/max(a,b)
silhouette_avg += s
silhouette_avg /= n_samples
return silhouette_avg
centroids,labels = KMeans(data,10)
silhouette_score(data,labels)
二、 最小化惯性
最小化惯性(也称为WCSS,即Within-Cluster Sum of Squares)是基于质心的聚类方法(如k-means)的一个重要目标。
这里的“惯性”指的是各个样本到其所属聚类中心的距离的平方和。这个指标衡量了聚类内部的紧密程度,即同一聚类内的样本是否足够接近其聚类中心。
在k-means聚类中,算法会迭代地更新聚类中心,以最小化所有样本到其所属聚类中心的距离的平方和,即最小化惯性。这样,每个聚类内的样本都会尽可能接近其聚类中心,从而达到较好的聚类效果。
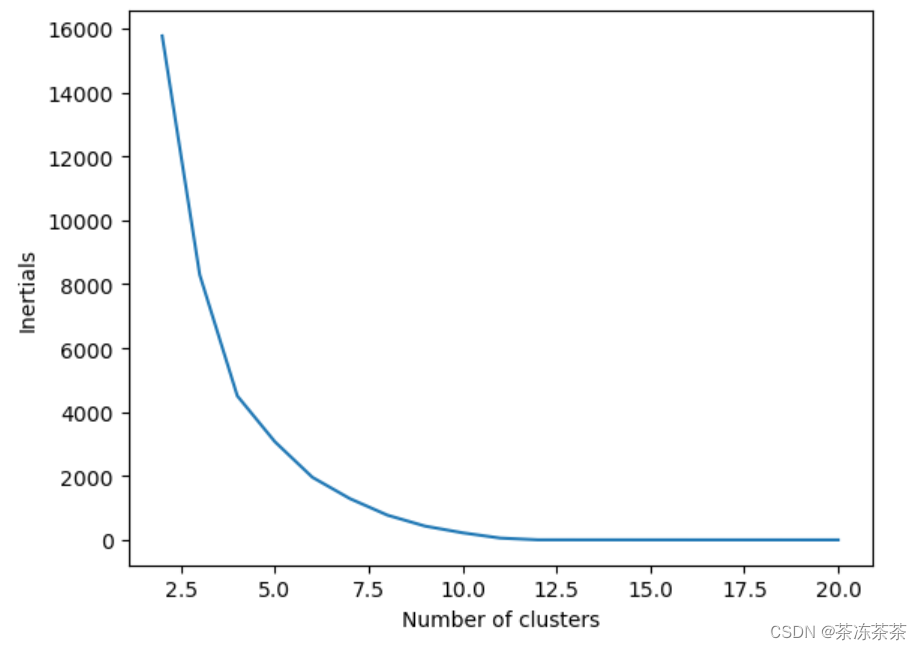
它可能会受到聚类数量k的影响。当k值较大时,即使每个聚类内部的样本都很接近其聚类中心,但总的惯性值仍然可能很高。
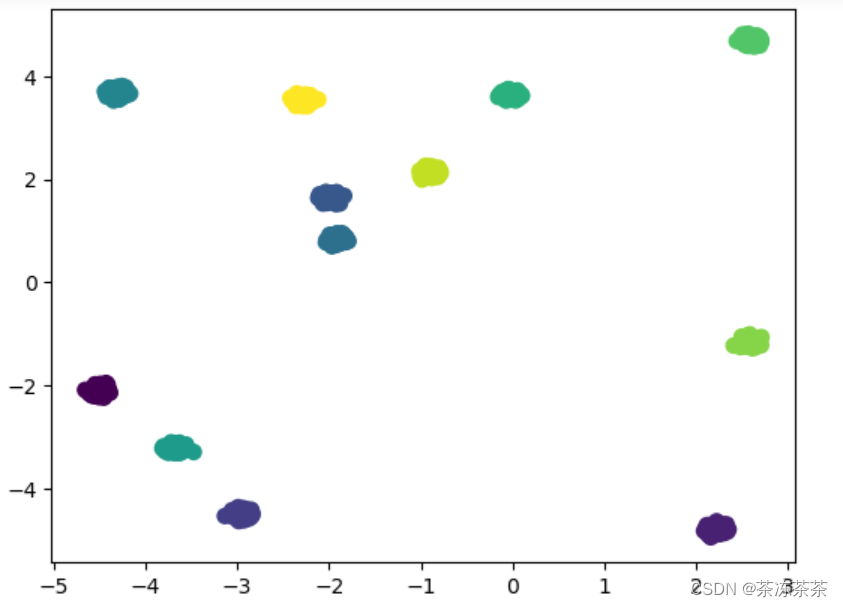
from sklearn.datasets import make_blobs
X,Y = make_blobs(n_samples=2000,n_features=2,centers=12,cluster_std=0.05,center_box=[-5,5],random_state=21)
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='viridis')
plt.show()
聚类数据
from sklearn.cluster import KMeans
inertials = []
for i in range(2,21):
model = KMeans(n_clusters=i,max_iter=1000,random_state=21)
model.fit(X)
inertials.append(model.inertia_)
plt.plot([i for i in range(2,21)],inertials)
plt.xlabel('Number of clusters')
plt.ylabel('Inertials')
plt.show()
惯性和聚类数量的关系函数
三、完整性分数
完整性分数是聚类分析中的一种外部评价指标。给出一组聚类真实标签和预测标签
| Y(true) | Y(pred) |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 2 | 2 |
| 2 | 2 |
| 3 | 3 |
| 3 | 3 |
| 3 | 3 |
如果用Y(true)表示包含真正赋值的集合,用Y(pred)表示一组预测集合,则可以估算一下概率:
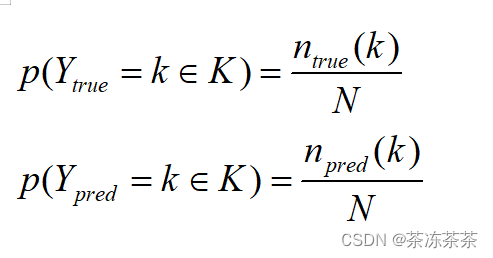
| P(Ytrue) | P(Ypred) |
|---|---|
| k=1,1/3 | k=1,2/9 |
| k=2,1/3 | k=2,4/9 |
| k=3,1/3 | k=3,1/3 |
其中 表示k属于K的真实或预测的样本数,熵用于量化一个随机变量不确定性的程度,根据我们的目的,接着可以计算Y(true)和Y(pred)的熵。
表示k属于K的真实或预测的样本数,熵用于量化一个随机变量不确定性的程度,根据我们的目的,接着可以计算Y(true)和Y(pred)的熵。
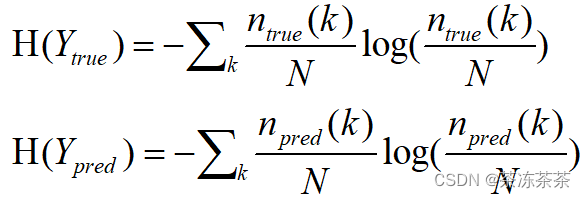
当随机变量的所有可能取值等概率出现时(即均匀分布),熵达到最大值。这是因为在这种情况下,随机变量的不确定性最高。引入条件熵表示已知另一个分布的不确定性:
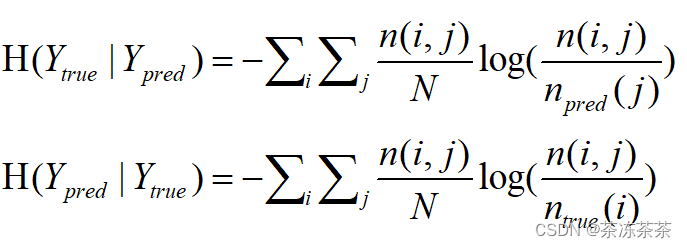
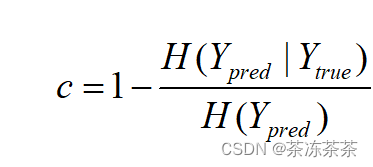
Y_true = [1,1,1,2,2,2,3,3,3]
Y_pred = [1,1,2,2,2,2,3,3,3]
from sklearn.metrics import completeness_score
print("completeness:{}".format(completeness_score(Y_true,Y_pred)))

四、同质性分数
同质性分数是基于聚类必须只包含具有相同真实标签的样本。定义如下:
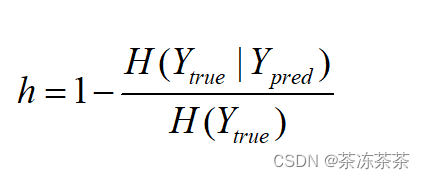
Y_true = [1,1,1,2,2,2,3,3,3]
Y_pred = [1,1,2,2,2,2,3,3,3]
from sklearn.metrics import homogeneity_score
print("homogeneity_score:{}".format(homogeneity_score(Y_true,Y_pred)))

五、调整后的互信息
六、调整后的兰德系数
调整后的兰德系数是真实标签分布和预测标签分布之间差异的度量。
假设U是外部评价标准即真实标签,而V是聚类结果。
- a:在U中为同一类且在V中也为同一类别的数据点对数
- b:在U中为同一类但在V中却隶属于不同类别的数据点对数
- c:在U中不在同一类但在V中为同一类别的数据点对数
- d:在U中不在同一类且在V中也不属于同一类别的数据点对数
在本例中:
| class\cluster | 1 | 2 | 3 | sums |
|---|---|---|---|---|
| 1 | 2 | 1 | 0 | 3 |
| 2 | 0 | 3 | 0 | 3 |
| 3 | 0 | 0 | 3 | 3 |
| sums | 2 | 4 | 3 | n=9 |
a = C(2,2)+C(2,3)+C(2,3) = 1+3+3 =7
b = C(2,3)*3 - 7 = 9-7 = 2
c = C(2,2)+C(2,4)+C(2,3) -7 = 1+6+3-7 = 3
d = C(2,9) - 7 - 2 - 3 = 36-12 = 24
| class\cluster | same cluster | different cluster | sumU |
|---|---|---|---|
| same cluster | a=7 | b=2 | a+b=9 |
| different cluster | c= 3 | d=24 | c+d=27 |
| sumV | a+c=10 | b+d=26 | 36 |
兰德系数计算公式:
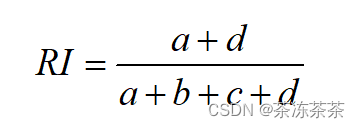
调整后的兰德系数计算公式:
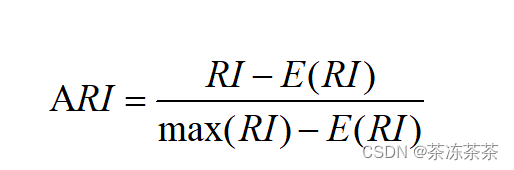
RI=(7+24)/36=0.86
ARI = (7-910/36)/(0.5(10+9)-10*9/36) = 0.64
Y_true = [1,1,1,2,2,2,3,3,3]
Y_pred = [1,1,2,2,2,2,3,3,3]
from sklearn.metrics import adjusted_rand_score
print("completeness:{}".format(adjusted_rand_score(Y_true,Y_pred)))

七、列联矩阵
列联矩阵是一个在已知真实情况时显示聚类算法性能的非常简单且强大的工具。



















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











