







基于《机器学习》学习整理- chapter 2
@(机器学习)[模型评估与选择]
经验误差与过拟合
一般地,我们把学习器的实际预测输出和样本的真实输出之间的差异称为”误差”,学习器在训练集上的误差称为”经验误差”,在新样本上的误差称为”泛化误差”。由于在我们并不知道新样本是什么样,所以实际上能做的就是努力使得经验误差最小化,但是经验误差很小,会导致泛化性能下降。称之为过拟合(overfitting)。
模型选择与评估方法
通常为了选择适当的模型,我们需要对该模型进行评估,可以使用实验测试对模型的泛化误差进行比较,因此,需要测试集。用测试误差来近似泛化误差。
测试集:也是从样本真实分布中独立同步采样得来的,应该尽可能与训练集互斥,不在训练集中出现,未在训练过程中使用。
对于一个包含m个样例的数据集 D={(x1,y1),(x2,y2),...(xm,ym)} 需要产生训练集 S 与测试集T ,
留出法
留出法(hold-out)直接将数据集 D 划分为两个互斥的集合,其中一个集合作为训练集
S ,另一个作为测试集 T ,即有
D=S∪T,S∩T=∅
需要注意的是,训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。通常使用分层采样。
不同的划分会导致不同的训练/测试集,相应的模型评估的结果也会有差别。故单次使用留出法的估计结果往往不可靠,使用留出法一般要若干次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。
问题:
我们评估的是用 D 训练出的模型的性能,但留出法划分了数据集,使得实际上训练的数据集小了,若S 比例较大,训练的模型较为接近 D 训练的模型,但是由于T 较小,评估结果可能就不太稳定准确。若令 T 比重较大,则S 与 D 差别就更大了。
建议:
训练集/测试集:2/3~4/5
交叉验证法
交叉验证法(cross validation)先将数据集
D 划分为k个大小相似的互斥子集。即有:
D=D1∪D2∪...∪Dk,Di∩Dj=∅
每个子集 Di 都尽可能保持数据分布的一致性,即从 D 中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以获得k组训练/测试集。从而可以进行k次训练与测试,最终返回的是这k个测试结果的均值。
很显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,通常把交叉验证法称为”k折交叉验证(k-fold cross validation)”,k最常用的取值为10。如下图:
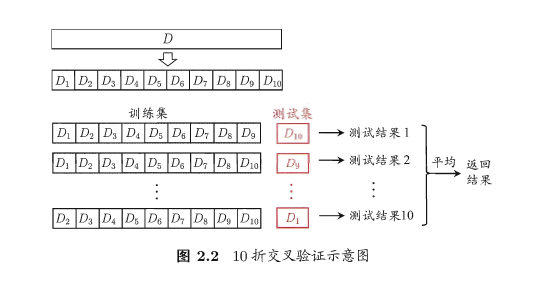
与留出法类似,为了减少因样本划分不同而引入的差别,k折交叉验证通常要随机使用不同的划分冲p次,最终的评估结果是这p次k折交叉验证结果的均值。
交叉验证法的特例:留一法(leave-one-out),m个样本划分为m个子集,每个子集包括1个样本,这样使得绝大多数情况下,留一法被实际评估的模型与期望模型评估的D训练出来的模型很相似。缺陷:数据集较大时,计算开销。同时留一法的估计结果也未必比其他评估方法准确。
自助法
简单的说,它从数据集
D 中每次随机取出一个样本,将其拷贝一份放入新的采样数据集 D′ ,样本放回原数据集中,重复这个过程m次,就得到了同样包含m个样本的数据集 D′ ,显然 D 中会有一部分数据会在D′ 中重复出现。样本在m次采样中始终不被采样到的概率是 (1−1m)m ,取极限得到:
limm→∞=1e≈0.368
即通过自助法,初始数据集中约有36.8%样本未出现在采样数据集 D′ 中。可将 D′ 作为训练集, D\D′ 作为测试集,(\表示集合的减法)。保证了实际评估的模型与期望评估的模型都是用m个训练样本,而有数据总量约1/3的、没在训练集中出过的样本用于测试,这样的测试结果,也叫做”包外估计”(out-of-bagestimate).
适用场景
自助法在数据集较小、难以有效划分训练/测试集很有用;此外自助法可以从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大好处。
问题
自助法产生的数据集改变了初始数据集的分布,引入估计偏差。故在数据量足够时,留出法与交叉验证更为常用。
调参与最终模型
调参
对算法参数进行设定,参数调节。调参需要注意,常用的做法是对每个参数选定一个范围与变化步长,在计算开销与性能估计之间折中。
最终模型
对于m个样本的数据集 D ,训练出模型并选择完成后,学习算法与参数配置都已选定,还需要用数据集
D 重新训练,这个模型才是我们的最终模型。
验证集
在模型评估与选择中用于评估测试的数据集。测试集用于估计模型在使用时的泛化能力,验证集用于模型选择与调参。
性能度量
性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验评估方法,还需要有模型泛化能力的评价标准。这就是性能度量。
均方误差
回归任务中最常用的性能度量方法:
E(f;D)=1m∑i=1m(f(xi)−yi)2
更一般的,对于数据分布 D 和概率密度函数p(⋅) ,均方误差为:
E(f;D)=∫x D(f(x)−y)2p(x)dx
错误率与精度
错误率就是分类错误的样本占样本总数的比例;精度就是分类正确的样本占样本总数的比例,
对于样例 D ,分类错误率定义为:
E(f;D)=1m∑i=1mⅡ(f(xi)≠yi)
其中Ⅱ( ⋅ )指示函数表示真取1,假取0.
精度则定义为:
acc(f;D)=1m∑i=1mⅡ(f(xi)=yi)=1−E(f;D)
更一般地对于数据分布 D 和概率密度函数p(⋅) ,错误率与精度分别描述为
E(f;D)=∫x DⅡ(f(x)≠y)p(x)dx,acc(f;D)=∫x DⅡ(f(x)=y)p(x)dx=1−E(f;D)
查全率、查准率与F1
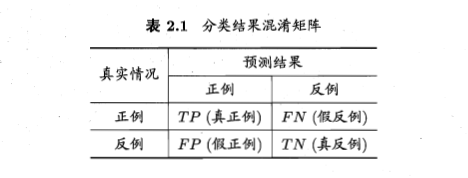
对于分类问题我们可以将样例与预测类别的组合划分为真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN),显然有 TP+FP+TN+FN=样例总数 ,混淆矩阵如下:
查准率P与查全率R:
P=TPTP+FP,R=TPTP+FN
很多情况下,我们用学习器的预测结果对样例进行排序,排在前面的学习器认为是最可能的正例的样本,排在最后的则是学习器认为最不可能正例的样本。按此逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率。以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称P-R曲线。如下:
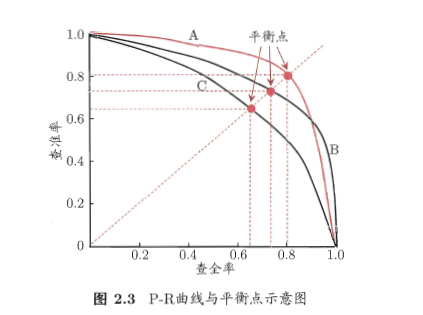
- 一般的若一个学习器的P-R曲线A包住了另一个学习器的曲线C,那么认为A学习器较优;
- 若A曲线与B曲线有交叉点,那么很难断言二者的优劣性,模糊情况下可以用面积来比较;
- 基于平衡点(break-event point)的比较,它是查全率与查准率相等的点,平衡点较高的较优。
F1度量
F1度量更为实用
F1=2×P× RP+R=2×TP样例总数+TP−TN
F1度量的一般形式- Fβ
Fβ=(1+β2)×P×R(β2×P)+R
其中 β >0度量了查全率对查准率的相对重要性。 β=1 退化成F1; β >1时查全率更大影响,相反查准率更大影响。
ROC与AUC
ROC
ROC,受试者工作特征(receiver operating characteristic),ROC曲线的纵轴为”真正例率”-TPR,横轴为”假正例率”(FPR),两者分别定义为
TPR=TPTP+FN,FPR=FPTN+FP
进行学习器的比较时,若一个学习器的ROC曲线被另一个学习器的曲线包住时,可以断言后者的性能优于前者;同理若交叉,则比较面积,即AUC(Area Under ROC Curve)
AUC=12∑i=1m−1(xi+1−xi)⋅(yi+yi+1)















 4905
4905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









