







L1正则,和L2正则是一种对优化函数参数进行约束的一种手段。如果优化的目标函数产生过拟合的时候,有高次项参数大,低此项参数低的特点。加入正则项可以迫使他们趋于平均,让低此项的部分也尽力去参与拟合。
-----------------------------------------------------------------------
假设优化的目标函数W就只有两个参数,他的L1正则如图所示,其中正则化参数 λ>0 称为为 LASSO:
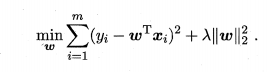
L2正则如下图所示,其中正则化参数 λ>0 称为岭回归:
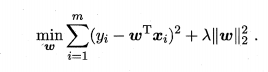
可以看到优化的误差函数是一个2次方程,图像可视化如下图:

上面目标函数解出的解都只有两个分量,即 ω1 , ω2,我们将其作为两个坐标轴,然后在图中绘制目标函数的"等值线",即在 (ω1 ,叫)空间中平方误差项取值相同的点的连线,再分别绘制出 L1 范数与 L2范数的等值线。上面两式的解要在平方误差项与正则化项之间折中,即出现在图中平方误差项等值线与正则化项等值线相交处。由上图可看出,采用L1范数时平方误差项等值线与正则化项等值线的交点常出现在坐标轴上即ω1或ω2为0, 而在采用 L2 范数时,两者的交点常出现在某个象限中 , 即ω1或 ω2均非 0; 换言之而言采用L1范数比L2范数更易于得到稀疏解。
-----------------------------------------------------------
获取稀疏解的好处有,加速矩阵运算等,最重要是压缩感知的应用。
------------------------------------------------------------
作为正则项有什么要求,是要拥有连续导数。
L2正则是凸函数,可以用梯度下降法求解导数等于0处。
L1正则可以用次导数替代导数功能。在不连续的地方次导数是解是一个集合,在最小点处不连续,那么解集合包含0来判断到了最小解,次导数用这种方法规避了L1范数没有连续导数的限制。用Bregman迭代求解次导数包含0点处。
下面进行一些问答:
问:L1正则和L2正则有什么区别?什么场景下使用?
有容|DataWhale答:正则化的使用场景是为了降低过拟合,L1范数正则化项是向量中各个元素的绝对值之和。L1范数可以实现让参数矩阵稀疏,让参数稀疏的好处,可以实现对特征的选择(权重为0表示对应的特征没有作用,被丢掉),也可以增强模型可解释性(例如研究影响疾病的因素,只有少数几个非零元素,就可以知道这些对应的因素和疾病相关),L1又称Lasso。
L2范数是指向量各个元素的平方,求和,然后再求平方根。使L2范数最小,可以使得W的每个元素都很小,都接近于0,但和L1范数不同,L2不能实现稀疏,不会让值等于0,而是接近于0。一般认为,越小的参数,模型越简单,越简单的模型就不容易产生过拟合现象。
使用场景的话:使用L1范数,可以使得参数稀疏化,方便计算,但是没有考虑到全局特性;使用L2范数,倾向于使参数稠密地接近于0,避免过拟合。优点是当你L1正则化时,没有把噪点值置为0,此时由于比较稀疏,噪点对模型影响会比较大,但是L2正则化考虑每个点,对于会将噪点影响减弱(类似的可以想一下求平均值),鲁棒性会好很多。具体使用的话可以结合优缺点和具体的场景进行选择,当然最直接就是就都试一下,选择哪个效果好就用哪个。















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









