







一、下载
V1.0
https://github.com/bbrashers/WPS-ghrsst-to-intermediate/tree/master
V1.5(使用过程报错,原因不详,能正常使用的麻烦告知一下方法)
https://github.com/dmitryale/WPS-ghrsst-to-intermediate
二、修改makefile
注意:使用什么编译器,那么NETCDF和HDF5也需要使用该编译器编译的版本。
主要修改编译器和NETCDF和HDF5路径
2.1原始文件(PGI)
原始makefile使用PGI编译器编译

2.2 Gfortran
修改如下
FC = gfortran
FFLAGS = -g -std=legacy
#FFLAGS += -tp=istanbul
FFLAGS += -mcmodel=medium
#FFLAGS += -Kieee # use exact IEEE math
#FFLAGS += -Mbounds # for bounds checking/debugging
#FFLAGS += -Ktrap=fp # trap floating point exceptions
#FFLAGS += -Bstatic_pgi # to use static PGI libraries
FFLAGS += -Bstatic # to use static netCDF libraries
#FFLAGS += -mp=nonuma -nomp # fix for "can't find libnuma.so"
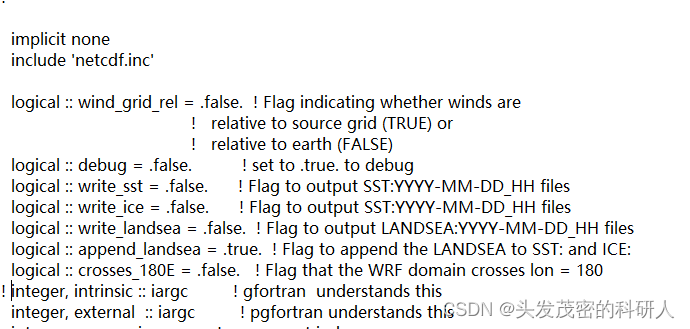
修改ghrsst-to-intermediate.f90
将第33行的注释去掉,将第43行注释
将 “integer, external” 改为 “integer, intrinsic”

2.3 Intel
FC = ifort
FFLAGS = -g
FFLAGS += -m64 # Ensure 64-bit compilation
FFLAGS += -check bounds # Bounds checking/debugging
# FFLAGS += -fp-model precise # Use precise floating point model
# FFLAGS += -ftrapuv # Trap undefined values
FFLAGS += -static-intel # Use static Intel libraries
# FFLAGS += -Bstatic # Use static netCDF libraries
FFLAGS += -qopenmp # Enable OpenMP parallelization
三.编译
make #生成在自己的路径下
sudo make install #将生成的ghrsst-to-intermediate复制到/usr/local/bin
四、测试
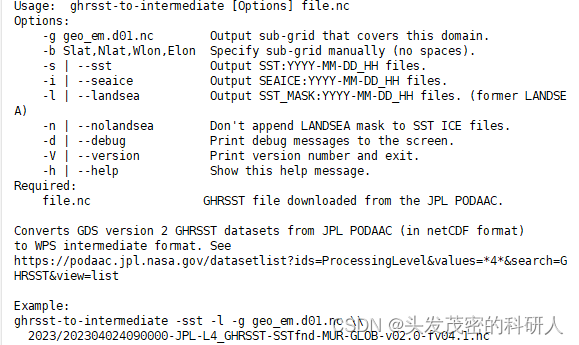
ghrsst-to-intermediate -h
五、下载GHRSST数据
使用python进行下载
import os
import requests
from datetime import datetime, timedelta
from urllib.parse import urlparse
import concurrent.futures
import logging
from tqdm import tqdm
from urllib3.util.retry import Retry
from requests.adapters import HTTPAdapter
def setup_logging():
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def download_file_for_date(custom_date, output_folder):
url_template = "https://coastwatch.pfeg.noaa.gov/erddap/files/jplMURSST41/{}090000-JPL-L4_GHRSST-SSTfnd-MUR-GLOB-v02.0-fv04.1.nc"
url = url_template.format(custom_date)
# 创建年/月文件夹
year_folder = os.path.join(output_folder, custom_date[:4])
month_folder = os.path.join(year_folder, custom_date[4:6])
os.makedirs(month_folder, exist_ok=True)
parsed_url = urlparse(url)
output_file = os.path.join(month_folder, os.path.basename(parsed_url.path))
# 检查文件是否已存在,如果存在则跳过下载
if os.path.exists(output_file):
logging.info(f"File for {custom_date} already exists. Skipping download.")
return
try:
session = requests.Session()
retry = Retry(total=5, backoff_factor=1, status_forcelist=[429, 500, 502, 503, 504])
adapter = HTTPAdapter(max_retries=retry)
session.mount('https://', adapter)
response = session.get(url, stream=True)
response.raise_for_status() # 检查请求是否成功
# 获取文件大小
file_size = int(response.headers.get('content-length', 0))
# 显示进度条
with open(output_file, 'wb') as f, tqdm(
desc=f"Downloading {custom_date}",
total=file_size,
unit="B",
unit_scale=True,
unit_divisor=1024,
dynamic_ncols=True,
leave=False
) as progress_bar:
for data in response.iter_content(chunk_size=1024):
f.write(data)
progress_bar.update(len(data))
logging.info(f"File for {custom_date} downloaded successfully as {output_file}")
except requests.exceptions.RequestException as e:
logging.error(f"Failed to download file for {custom_date}. {e}")
if __name__ == "__main__":
setup_logging()
# 设置开始和结束日期
start_date = datetime(2019, 1, 1)
end_date = datetime(2020, 1, 1)
# 设置输出文件夹
output_folder = ""
# 设置线程池大小
max_threads = 5
# 循环下载文件
with concurrent.futures.ThreadPoolExecutor(max_threads) as executor:
futures = []
current_date = start_date
while current_date <= end_date:
formatted_date = current_date.strftime("%Y%m%d")
future = executor.submit(download_file_for_date, formatted_date, output_folder)
futures.append(future)
current_date += timedelta(days=1)
# 等待所有线程完成
concurrent.futures.wait(futures)
六、将GHRSST转换为SST文件
import subprocess
from datetime import datetime, timedelta
import os
import shutil
import re
import resource
def set_stack_size_unlimited():
# Set the stack size limit to unlimited
resource.setrlimit(resource.RLIMIT_STACK, (resource.RLIM_INFINITY, resource.RLIM_INFINITY))
def process_sst_files(current_date, source_directory):
current_day = current_date.strftime("%Y%m%d")
year = current_date.strftime("%Y")
month = current_date.strftime("%m")
# Perform some action for each day
command = [
"ghrsst-to-intermediate",
"--sst",
"-g",
"geo_em.d01.nc",#geo_em.d01.nc文件路径
f"{source_directory}/{year}/{month}/{current_day}090000-JPL-L4_GHRSST-SSTfnd-MUR-GLOB-v02.0-fv04.1.nc"
]
subprocess.run(command)
def move_sst_files(source_directory, destination_directory):
for filename in os.listdir(source_directory):
if filename.startswith("SST"):
source_path = os.path.join(source_directory, filename)
# Extract year and month from the filename using regular expressions
match = re.match(r"SST:(\d{4}-\d{2}-\d{2})_(\d{2})", filename)
if match:
year, month = match.groups()
# Create the destination directory if it doesn't exist
destination_year_month_directory = os.path.join(destination_directory, year[:4], month)
os.makedirs(destination_year_month_directory, exist_ok=True)
# Construct the destination path
destination_path = os.path.join(destination_year_month_directory, filename)
# Move the file to the destination directory
shutil.copyfile(source_path, destination_path)
def organize_and_copy_files(SST_path, WPS_path):
for root, dirs, files in os.walk(SST_path):
for file in files:
if 'SST:' in file:
origin_file = os.path.join(root, file)
for hour in range(1,24,1):#时间间隔调整,跟interval_seconds相同(单位为小时)
hour_str = str(hour).rjust(2, '0')
copy_file = os.path.join(WPS_path, file.split('_')[0]+'_'+hour_str)
if not os.path.exists(copy_file):
print(copy_file)
shutil.copy(origin_file, copy_file)
def main():
set_stack_size_unlimited()
# Set the start and end dates for the loop
start_date = datetime.strptime("20191231", "%Y%m%d")
end_date = datetime.strptime("20200108", "%Y%m%d")
source_directory = ""#python代码路径,SST生成在该路径下
destination_directory = ""#另存为SST的文件路径
WPS_path=""#WPS文件路径
#逐一运行ghrsst-to-intermediate,生成当天的SST文件
for current_date in (start_date + timedelta(n) for n in range((end_date - start_date).days + 1)):
process_sst_files(current_date, source_directory)
#将生存的SST文件复制到另外的文件夹中保存
move_sst_files(source_directory, destination_directory)
#将SST文件按照需要的时间间隔复制
organize_and_copy_files(source_directory, WPS_path)
if __name__ == "__main__":
main()
















 6506
6506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











