







Based on deep learning, instead of sharing weights across source and target domains, this work proposed a two-stream architecture where different streams operate on different domains, with an additional loss function to imply the relationships across domains.
与以往在不同域上共享权重的方式不同,这篇文章提出在不同域上使用不同的权重系数,一个用于源域,一个用于目标域,同时提出一种方式来保持这两个域上的网络系数的相关性。
摘要:不同域上的数据往往有不同的特点,因此它们特征提取往往需要不同的参数。本文基于这种考虑,在domain adaptation的应用上,提出一种两个分流的网络结构,一个用于源域,一个用于特征域,区别于以往在不同域上共享权重(share weights)的结构,这对应了在不同域上采用不同但相关的参数结构。整个结构在文中用下图表示:
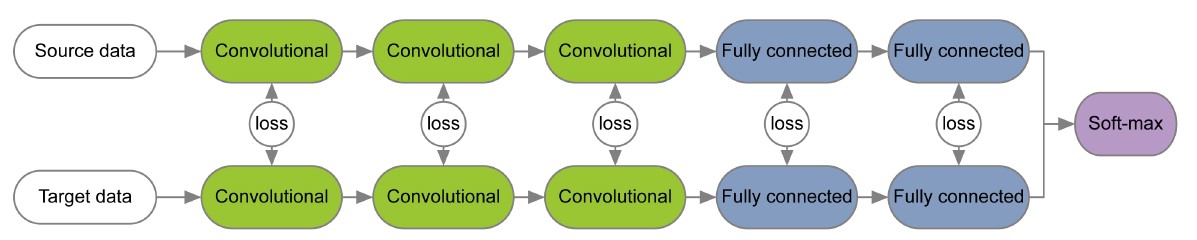
其中上面的一列对应源域上的网络,下面的列对应目标域上的网络结构。为了保证两者之间的相关性,添加了layer-to-layer的损失函数 。
在预训练阶段,首先用源域上的数据对源域的网络结构进行训练,然后用训练的结构对网络的两个分流进行初始化;在训练阶段,由于网络每条分支上有不同的损失,传回来的梯度也就不同,从而对网络每层的权重进行差异化的更新,同时目标函数中layerwise的损失保证了两个结构中
 这篇文章提出了一种在不同域上使用不同网络参数来提取特征的网络结构。为了保证两个网络的相似性,提出了一种衡量两个参数差别的损失。
这篇文章提出了一种在不同域上使用不同网络参数来提取特征的网络结构。为了保证两个网络的相似性,提出了一种衡量两个参数差别的损失。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









