







本文结合对抗网络以及深度网络生成图像来不同域之间样本生成的问题,根据源域上的样本生成目标域上对应的样本。这个思路是用生成模型encoder获取源域上低维的语义信息,然后通过decoder来生成目标域上的图像,将encoder和decoder总称为converter,从而根据源域上的样本生成目标域上的样本。为了很好的训练converter,本文结合了两个判别模型来辅助训练。具体而言,其中生成模型中,encoder首先学习一个训练数据的64维语义信息;然后通过decoder将语义向量生成对应的目标域上的样本。判别模型中,real/fake-discriminator,是为了让生成模型生成的图片尽可能的与原有样本之间没有可分性,这个和之前GAN网络中的判别模型作用类似。Domain discriminator相当于在训练的生成模型上添加了一个pair-wise的损失,保证了生成模型生成的目标域上的图片保留了源域上样本语义信息。最终整个网络的结构如下:
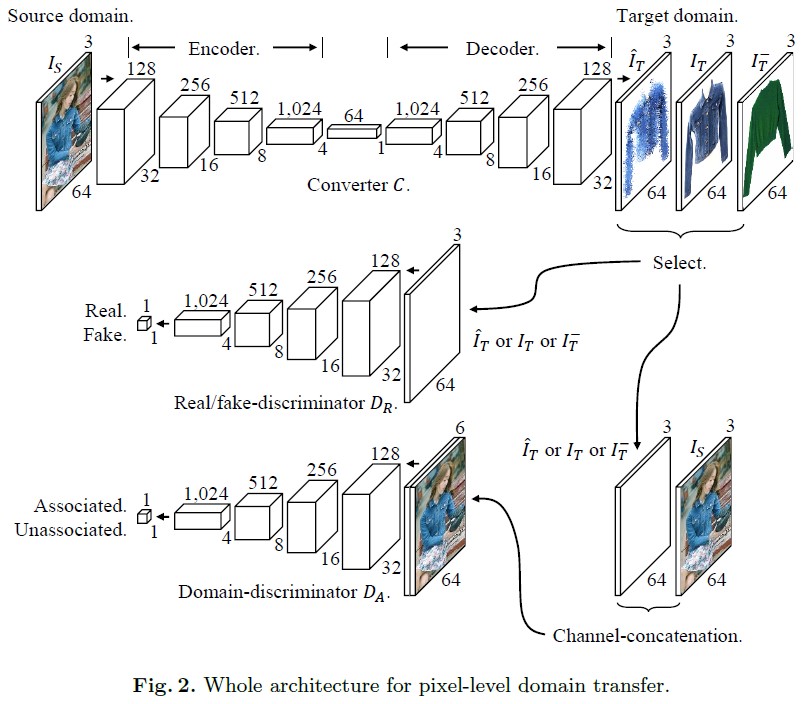
其中最上面的对应网络中的生成模型,第二层的网络结构对应real/fake classifier,第三层网络对应的domain classifier。下面从这个三层结构以及训练方法来对文章内容进行介绍。
1. convertC:由encoder 和decoder构成。Encoder提取图片的低维(64维)语义信息。Decoder根据语义信息生成目标域上的样本。这里需要注意的地方是源域和目标域的样本并不是一对一的关系,而是一对多的关系。这种关系可以用下图表示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















01-03
 648
648
648
07-28
252
252
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









