







序言
1. 内容介绍
本章详细介绍了特征词转文本向量的方法、词袋模型与词集模型的计算方法、词频与逆词频的计算方法等内容。
2. 理论目标
- 了解特征词转文本向量的方法
- 了解词袋模型与词集模型的计算方法
- 了解词频与逆词频的计算方法。
3. 实践目标
- 掌握特征词转文本向量的方法,能完成目标文档词组转向量的操作;
- 掌握词袋模型与词集模型的计算方法,能完成目标文档计算词袋模型的操作;
- 掌握词频与逆词频的计算方法,能完成目标文档计算词频与逆词频的操作,能调用sklearn库计算词频与逆词频值。
4. 实践案例
无
5. 内容目录
-
1.特征词转文本向量
-
2.词集模型与词袋模型
-
3.词频与逆词频
-
4.文本特征向量化实战
第1节 特征词转文本向量
1. 文本向量概述
由于原始数据往往并不是数值型的(如字词列表),为满足数学模型的处理要求,这样就需要将文本特征词的数据进行向量化处理,即转换为数值向量格式。
假设现有如下文档需转换为数字向量形式。
- 文档1:“我来到成都,成都春熙路很开心”
- 文档2:“今天在宽窄巷子耍了一天”
假如词典集合为 [‘成都’, ‘巷子’, ‘耍’, ‘春熙路’, ‘来到’, ‘宽窄’, ‘开心’],则以上文档转换如下:
- 文档1:[2, 0, 0, 1, 1, 0, 1]
- 文档2:[0, 1, 1, 0, 0, 1, 0]
其中数字代表文档相关词组在词典集合对应位置词组出现的次数。
2. 实施步骤
- 文档中文分词,构建所有文档的不重复特征词;
- 词组数据清洗、去重停用词等;
- 文档文本词频统计,转化为向量形式。
import jieba sList = ["我来到成都,成都春熙路很开心", "今天在宽窄巷子耍了一天"] ## 1.文档中文分词,构建所有文档的不重复特征词 corpus = [] wordSet = set() for sListi in sList: docList = jieba.lcut(sListi) ## 中文分词 corpus.append(docList) ## 每个文档分词结果(列表)放到列表内 wordSet.update(docList) ## 每个文档分词结果(按列表元素)放到集合内(去重效果) print(corpus) print(wordSet) wordList = list(wordSet) print(wordList)
[['我', '来到', '成都', ',', '成都', '春熙路', '很', '开心'], ['今天', '在', '宽窄', '巷子', '耍', '了', '一天']]
{'巷子', '今天', '一天', '了', '来到', '耍', '很', ',', '春熙路', '在', '我', '宽窄', '开心', '成都'}
['巷子', '今天', '一天', '了', '来到', '耍', '很', ',', '春熙路', '在', '我', '宽窄', '开心', '成都']
## 2.词组数据清洗、去重停用词等 def clearStopword(stopwordsPath, wordList): # 1.读取停用词 with open(stopwordsPath,'r',encoding='utf-8') as f: stopwordList = f.read().split('\n') # 2.遍历待分词文本信息,去除停用词 for i in range(len(wordList))[::-1]: if wordList[i] in stopwordList: wordList.pop(i) return wordList stopwordsPath = "./NLPIR_stopwords.txt" wordList = clearStopword(stopwordsPath, wordList) print(wordList)
['巷子', '来到', '耍', '春熙路', '宽窄', '开心', '成都']
## 3.文档文本词频统计,转化为向量形式 ## 遍历每个文档词组列表,对比词典集合,统计在词典集合中出现的次数 for corpusi in corpus: wordVect = [0]*len(wordList) # 按词典集合生成元素全为 0 的列表 for corpusij in corpusi: # 若文档词组在词典列表中出现1 次就加1 if corpusij in wordList: wordVect[wordList.index(corpusij)] = wordVect[wordList.index(corpusij)] + 1 print(wordVect)
[0, 1, 0, 1, 0, 1, 2]
[1, 0, 1, 0, 1, 0, 0]
第2节 词袋模型与词集模型
1. 词袋模型介绍
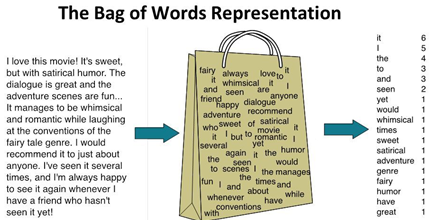
词袋模型(Bag-of-Words,简称BoW),经常用在自然语言处理和信息检索当中。
将一篇文本(文章)看做一个“装着词的袋子”,将文章看做词的组合,文中出现的每个词都是独立的,忽略文章的词序、语法和句法。简单的理解,上一节的文本向量组合成新列表或数组即为词袋模型
虽然这个事实上并不成立,但是在实际的文本分析工作中效果很好。
2. 词袋模型实施
词袋模型实施步骤
- 准备数据,对文档进行中文分词及清洗处理
- 获取词集合,剔除重复词组,返回唯一词组元素的词列表
- 文本向量化,统计各文档中字词的词频,组成向量形式
词袋模型实施代码
step1.准备数据,对文档进行中文分词及清洗处理
''' 将所有文章的字词列表合并到一个大列表/大数组 ''' def loadDataSet(): # 此处为简化过程,直接输入字词列表,具体中文分词及清洗处理见《第八章 中文分词》 tiyu = ['姚明', '我来', '承担', '连败', '巨人', '宣言', '酷似', '当年', '麦蒂', '新浪', '体育讯', '北京', '时间', '消息', '休斯敦', '纪事报', '专栏', '记者', '乔纳森', '费根', '报道', '姚明', '渴望', '一场', '胜利', '当年', '队友', '麦蒂', '惯用', '句式'] yule = ['谢婷婷', '模特', '酬劳', '仅够', '生活', '风光', '背后', '惨遭', '拖薪', '新浪', '娱乐', '金融', '海啸', 'blog', '席卷', '全球', '模特儿', '酬劳', '被迫', '打折', '全职', 'Model', '谢婷婷', '业界', '工作量', '有增无减', '收入', '仅够', '糊口', '拖薪'] jioayu = ['名师', '解读', '四六级', '阅读', '真题', '技巧', '考前', '复习', '重点', '历年', '真题', '阅读', '听力', '完形', '提升', '空间', '天中', '题为', '主导', '考过', '六级', '四级', '题为', '主导', '真题', '告诉', '方向', '会考', '题材', '包括'] shizheng = ['美国', '军舰', '抵达', '越南', '联合', '军演', '中新社', '北京', '日电', '杨刚', '美国', '海军', '第七', '舰队', '三艘', '军舰', '抵达', '越南', '岘港', '为期', '七天', '美越', '南海', '联合', '军事训练', '拉开序幕', '美国', '海军', '官方网站', '消息'] corpus =[tiyu, yule, jioayu, shizheng] # classVec:文档所属类别 classVec = ['体育','娱乐','教育','时政'] # 返回文档词组列表及类别 return corpus,classVec
import numpy as np corpus, classVec = loadDataSet() print(np.mat(corpus)) # 矩阵格式输出
[['姚明' '我来' '承担' '连败' '巨人' '宣言' '酷似' '当年' '麦蒂' '新浪' '体育讯' '北京' '时间' '消息'
'休斯敦' '纪事报' '专栏' '记者' '乔纳森' '费根' '报道' '姚明' '渴望' '一场' '胜利' '当年' '队友'
'麦蒂' '惯用' '句式']
['谢婷婷' '模特' '酬劳' '仅够' '生活' '风光' '背后' '惨遭' '拖薪' '新浪' '娱乐' '金融' '海啸'
'blog' '席卷' '全球' '模特儿' '酬劳' '被迫' '打折' '全职' 'Model' '谢婷婷' '业界' '工作量'
'有增无减' '收入' '仅够' '糊口' '拖薪']
['名师' '解读' '四六级' '阅读' '真题' '技巧' '考前' '复习' '重点' '历年' '真题' '阅读' '听力' '完形'
'提升' '空间' '天中' '题为' '主导' '考过' '六级' '四级' '题为' '主导' '真题' '告诉' '方向' '会考'
'题材' '包括']
['美国' '军舰' '抵达' '越南' '联合' '军演' '中新社' '北京' '日电' '杨刚' '美国' '海军' '第七' '舰队'
'三艘' '军舰' '抵达' '越南' '岘港' '为期' '七天' '美越' '南海' '联合' '军事训练' '拉开序幕' '美国'
'海军' '官方网站' '消息']]
step2.获取词集合,剔除重复词组,返回唯一词组元素的词列表
''' 以所有文章的字词创建不重复的字词集合,称作词汇表,以数据类型set()实现 ''' def createVocabList(dataSet): vocabSet = set() for dataSeti in dataSet: vocabSet.update(dataSeti) return list(vocabSet)
vocabList = createVocabList(corpus) print(vocabList)
['全职', '巨人', '席卷', 'Model', '拖薪', '杨刚', '解读', '天中', '考过', '完形', '抵达', '承担', '记者', '美国', '金融', '技巧', '为期', '南海', '舰队', '三艘', '岘港', '业界', '北京', '听力', '军演', '重点', '背后', '模特', '宣言', '纪事报', '拉开序幕', '糊口', '乔纳森', '惨遭', '被迫', '惯用', '句式', '空间', '工作量', '官方网站', '中新社', '军舰', '越南', '打折', '包括', '渴望', '第七', 'blog', '模特儿', '我来', '阅读', '专栏', '名师', '美越', '新浪', '酬劳', '主导', '海军', '方向', '考前', '有增无减', '消息', '麦蒂', '生活', '一场', '体育讯', '娱乐', '时间', '连败', '胜利', '七天', '历年', '日电', '收入', '谢婷婷', '休斯敦', '告诉', '当年', '真题', '报道', '复习', '军事训练', '会考', '海啸', '姚明', '提升', '四六级', '题为', '仅够', '队友', '联合', '酷似', '费根', '全球', '四级', '题材', '风光', '六级']
step3.文本向量化,统计各文档中字词的词频,组成向量形式
''' 1. 遍历每个文档中的所有词(双循环) 2. 创建词汇表等长的向量(全为 0 元素),若文档的字词在词汇表中出现,则相应位置加1 3. 将所有文章的词频向量合并到一个大列表/大数组 ''' def bagOfWords2Vec(vocabList, dataSet): VecList = [] # 创建词向量 for dataSeti in dataSet: returnVec = [0] * len(vocabList) # 创建一个和词汇表等长的向量,并将其元素都设置为0 for word in dataSeti: if word in vocabList: returnVec[vocabList.index(word)] = returnVec[vocabList.index(word)] + 1 VecList.append(returnVec) return VecList
import numpy as np ## bagOfWords 即为词袋模型结果 bagOfWords = bagOfWords2Vec(vocabList, corpus) print(np.mat(bagOfWords)) # 矩阵格式输出
[[0 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 0 0 1 0 0 1
1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 1 2 0 1 1 0 1 1 1 0 0
0 0 0 1 0 2 0 1 0 0 0 0 2 0 0 0 0 1 0 1 1 0 0 0 0 0]
[1 0 1 1 2 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 1 0 1 1 0
0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 0 0 0 1 2 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 0
0 1 2 0 0 0 0 0 0 0 0 1 0 0 0 0 2 0 0 0 0 1 0 0 1 0]
[0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0 1 0 0 0 0 0 2 0 1 0 0 0 2 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1
0 0 0 0 1 0 3 0 1 0 1 0 0 1 1 2 0 0 0 0 0 0 1 1 0 1]
[0 0 0 0 0 1 0 0 0 0 2 0 0 3 0 0 1 1 1 1 1 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0
0 0 0 1 1 2 2 0 0 0 1 0 0 0 0 0 0 1 0 0 0 2 0 0 0 1 0 0 0 0 0 0 0 0 1 0
1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0]]
3. 词集模型介绍与实施
词集模型(Set-of-Words,简称SoW),即在词袋模型基础上,以0-1代替词的数量(大于0的数量代替为1)。
# 核心代码部分,将词袋模型修改如下: def setOfWords2Vec(vocabList, dataSet): VecList = [] # 创建词向量 for dataSeti in dataSet: returnVec = [0] * len(vocabList) # 创建一个和词汇表等长的向量,并将其元素都设置为0 for word in dataSeti: if word in vocabList: returnVec[vocabList.index(word)] = 1 ## 词集模型与词袋模型的主要差别 VecList.append(returnVec) return VecList
import numpy as np ## setOfWords 即为词集模型结果 setOfWords = setOfWords2Vec(vocabList, corpus) print(np.mat(setOfWords)) # 矩阵格式输出
[[0 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 0 0 1 0 0 1
1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 1 1 0 1 1 0 1 1 1 0 0
0 0 0 1 0 1 0 1 0 0 0 0 1 0 0 0 0 1 0 1 1 0 0 0 0 0]
[1 0 1 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 1 0 1 1 0
0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 0
0 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 1 0]
[0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1
0 0 0 0 1 0 1 0 1 0 1 0 0 1 1 1 0 0 0 0 0 0 1 1 0 1]
[0 0 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 1 1 1 1 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0
0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0
1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]]
第3节 词频与逆词频
1. 词频与逆词频基本概念
在模型训练的过程中,不能只是根据词频数判断词特征的权重。
比如,在体育类别的文章中“进球”、“比分”等特征词更具有代表性,比一般的“很棒”、“漂亮”等描述性词语的权重更高。这种情况下,单独以词频判断词特征权重就显得不合理。
为了解决这个问题,需要引入“词频-逆词频”概念,Term Frequency–Inverse Document Frequency(简称 TF-IDF):

词频-逆词频应用领域比较广泛,常见的如信息检索、提取关键字、文章相似度查重、自动文摘等方面均有应用。
2. 词频与逆词频计算实现
计算逻辑
- 词频TF计算,通过遍历每个文档的词袋模型,计算每个文档各个字词的词频
- 逆文档频率IDF计算,通过遍历每个文档的词集模型,计算每个文档各个字词的逆文档频率
- 2.1 输入的词袋模型转为词集模型,仅需将把非0的元素更新为1即可
- 2.2 计算文档总数,即词集模型的元素个数
- 2.3 计算包含该词的文档总数,即词集模型中该词的元素求和(个数统计)
- 词频-逆词频TF-IDF计算,即 TF * IDF
def TFIDF(bagVec): # 词频 = 某个词在本文档中出现的次数/本文档总词数 tf = [] for bagVeci in bagVec: tf.append(bagVeci/np.sum(bagVeci)) # 逆文档频率(IDF) = log(文档总数/(包含该词的文档数+1)) ## 1.转换为词集模型,用于计算文档数 setVec = bagVec for i in range(len(setVec)): for j in range(len(setVec[i])): if setVec[i][j] != 0: setVec[i][j] = 1 ## 2.计算文档总数 m = len(setVec) ## 3.包含该词的文档数 ndw = np.sum(setVec, axis=0) idf = np.log(m/(ndw+1)) # TF-IDF = TF * IDF tfidf = tf * np.array(idf) return tfidf tfidf = TFIDF(bagOfWords) print(tfidf)
[[0. 0.02310491 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.02310491
0.02310491 0. 0. 0. 0. 0.
0. 0. 0. 0. 0.0095894 0.
0. 0. 0. 0. 0.02310491 0.02310491
0. 0. 0.02310491 0. 0. 0.02310491
...
0. 0. ]]
3. 词频与逆词频sklearn实现
文档信息准备
文档列表中的每个元素是一个文档,需要将每个文档进行中文分词,并通过空格符号分隔开,形成字符串形式。
即将文档按中文分词后以空格分隔每个词组。
import jieba sList = ["我来到成都,成都春熙路很开心", "今天在宽窄巷子耍了一天"] corpus = [] for sListi in sList: corpus.append(" ".join(jieba.lcut(sListi))) print(corpus)
['我 来到 成都 , 成都 春熙路 很 开心', '今天 在 宽窄 巷子 耍 了 一天']
将文档信息转换为词袋向量
实施步骤:
- 声明一个向量化工具vectorizer
本文使用的是CountVectorizer,默认情况下,CountVectorizer仅统计长度超过两个字符的词.但是在短文本中任何一个字都可能十分重要,比如“去/到”等,所以要想让CountVectorizer也支持单字符的词,需要加上参数token_pattern=’\b\w+\b’。
- 将语料集转化为词袋向量(fit_transform);
- 获取词袋模型中的所有词语;
- 获取词袋模型。
from sklearn.feature_extraction.text import CountVectorizer # step 1. 声明一个向量化工具vectorizer,构建词汇表 vectorizer = CountVectorizer(min_df=1, max_df=1.0, token_pattern='\\b\\w+\\b') # step 2. 将文本转为词频矩阵 corpusVec = vectorizer.fit_transform(corpus) print(corpusVec) ## 格式 (0, 8) 1,0 代表文档位置索引,8 代表词组在词袋的位置索引,1 代表词组频次 print(type(corpusVec)) ## class 'scipy.sparse.csr.csr_matrix' # step 3. 获取词袋模型中的所有词语 word = vectorizer.get_feature_names() print(word) print(len(word)) # step 4. 获取词袋模型 bagOfWords = corpusVec.toarray() print(bagOfWords)
(0, 9) 1
(0, 11) 1
(0, 8) 2
(0, 10) 1
(0, 7) 1
(0, 6) 1
(1, 2) 1
(1, 3) 1
(1, 4) 1
(1, 5) 1
(1, 12) 1
(1, 1) 1
(1, 0) 1
<class 'scipy.sparse.csr.csr_matrix'>
['一天', '了', '今天', '在', '宽窄', '巷子', '开心', '很', '成都', '我', '春熙路', '来到', '耍']
13
[[0 0 0 0 0 0 1 1 2 1 1 1 0]
[1 1 1 1 1 1 0 0 0 0 0 0 1]]
CountVectorizer参数详解
CountVectorizer(input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.int64'>)
| 参数表 | 作用 |
|---|---|
| input | 一般使用默认即可,可以设置为"filename’或’file’ |
| encodeing | 使用默认的utf-8即可,分析器将会以utf-8解码raw document |
| decode_error | 默认为strict,遇到不能解码的字符将报UnicodeDecodeError错误,设为ignore将会忽略解码错误,还可以设为replace,作用尚不明确 |
| strip_accents | 默认为None,可设为ascii或unicode,将使用ascii或unicode编码在预处理步骤去除raw document中的重音符号 |
| analyzer | 一般使用默认,可设置为string类型,如’word’, ‘char’, ‘char_wb’,还可设置为callable类型,比如函数是一个callable类型 |
| preprocessor | 设为None或callable类型 |
| tokenizer | 设为None或callable类型 |
| ngram_range | 词组切分的长度范围,待详解 |
| stop_words | 设置停用词,设为english将使用内置的英语停用词,设为一个list可自定义停用词,设为None不使用停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库建立停用词表 |
| lowercase | 将所有字符变成小写 |
| token_pattern | 过滤规则,表示token的正则表达式,需要设置analyzer == ‘word’,默认的正则表达式选择2个及以上的字母或数字作为token,标点符号默认当作token分隔符,而不会被当作token |
| max_df | 可以设置为范围在[0.0 1.0]的float,也可以设置为没有范围限制的int,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效 |
| min_df | 类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词 |
| max_features | 默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集 |
| vocabulary | 默认为None,自动从输入文档中构建关键词集,也可以是一个字典或可迭代对象? |
| binary | 默认为False,一个关键词在一篇文档中可能出现n次,如果binary=True,非零的n将全部置为1,这对需要布尔值输入的离散概率模型的有用的 |
| dtype | 使用CountVectorizer类的fit_transform()或transform()将得到一个文档词频矩阵,dtype可以设置这个矩阵的数值类型 |
根据词袋向量统计TF-IDF
实施步骤:
- 声明一个TF-IDF转化器(TfidfTransformer);
- 根据语料集的词袋向量计算TF-IDF(fit_transform);
- 将语料集的词袋向量表示转换为TF-IDF向量表示;
- 打印每类文本的词语tf-idf权重。
from sklearn.feature_extraction.text import TfidfTransformer # step1. 构建TF-IDF转化器,统计每个词语的tf-idf权值 transformer = TfidfTransformer() # step2. 计算tf-idf tfidf = transformer.fit_transform(corpusVec) print(tfidf) # step3. 获取tf-idf权重 weight = tfidf.toarray() print(weight) # step4. 打印每类文本的词语tf-idf权重 for i in range(len(weight)): print(u"-------这里输出第", i, u"类文本的词语tf-idf权重------") for j in range(len(word)): ## word 为 上一小节计算结果 print(word[j], weight[i][j])
(0, 11) 0.33333333333333337
(0, 10) 0.33333333333333337
(0, 9) 0.33333333333333337
(0, 8) 0.6666666666666667
(0, 7) 0.33333333333333337
(0, 6) 0.33333333333333337
(1, 12) 0.3779644730092272
(1, 5) 0.3779644730092272
(1, 4) 0.3779644730092272
(1, 3) 0.3779644730092272
(1, 2) 0.3779644730092272
(1, 1) 0.3779644730092272
(1, 0) 0.3779644730092272
[[0. 0. 0. 0. 0. 0.
0.33333333 0.33333333 0.66666667 0.33333333 0.33333333 0.33333333
0. ]
[0.37796447 0.37796447 0.37796447 0.37796447 0.37796447 0.37796447
0. 0. 0. 0. 0. 0.
0.37796447]]
-------这里输出第 0 类文本的词语tf-idf权重------
一天 0.0
了 0.0
今天 0.0
在 0.0
宽窄 0.0
巷子 0.0
开心 0.33333333333333337
很 0.33333333333333337
成都 0.6666666666666667
我 0.33333333333333337
春熙路 0.33333333333333337
来到 0.33333333333333337
耍 0.0
-------这里输出第 1 类文本的词语tf-idf权重------
一天 0.3779644730092272
了 0.3779644730092272
今天 0.3779644730092272
在 0.3779644730092272
宽窄 0.3779644730092272
巷子 0.3779644730092272
开心 0.0
很 0.0
成都 0.0
我 0.0
春熙路 0.0
来到 0.0
耍 0.3779644730092272
第4节 文本特征向量化实战
1. 需求描述
结合《第八章、中文分词》的中文分词实战,基于每篇文章的词组列表,实现文本特征向量化。

2. 实现思路
实现思路:
- 遍历文件功能以类封装,遍历指定目录路径下文档,读取文档并返回文档内容
- 中文分词及清理以类封装,包括停用词文件路径初始化、加载停用词方法、中文文本分词及字词清洗方法
- 文本特征向量化以类封装,获取词集合、文本向量化(生成词袋模型)、计算tf-idf值向量。
其中步骤1、2在《第八章、中文分词》的中文分词实战已实现,以下主要针对步骤3 展开。
3. 实现文本特征向量化功能
综合前两节内容(词袋模型、词频与逆词频),实现文本特征向量化类:
- 定义类 TFIDF
- 定义__init__方法(构造方法,实例属性)
- 数据集
- 词集合
- 词向量(词袋模型)
- tfidf向量
- 获取词集合方法
剔除重复词组,返回唯一词组元素的词列表
- 文本向量化方法
统计各文档中字词的词频,组成向量形式(词袋模型)
- 词频与逆词频计算方法
统计词频TF和逆词频IDF,以最终得到TF-IDF
## 实现代码 class TFIDF(): def __init__(self, dataSet): self.dataSet = dataSet # 数据集,列表形式,每个元素为一个文档的分词列表 self.vocabList = [] # 词集合,列表形式,所有文档词组集合(不重复) self.VecList = [] # 创建词向量 self.tfidf = [] # tfidf向量 ## 获取词集合方法:剔除重复词组,返回唯一词组元素的词列表 def createVocabList(self): vocabSet = set() for dataSeti in self.dataSet: vocabSet.update(dataSeti) self.vocabList = list(vocabSet) ## 文本向量化方法,统计各文档中字词的词频,组成向量形式 def bagOfWords2Vec(self): for dataSeti in self.dataSet: returnVec = [0] * len(self.vocabList) # 创建一个和词汇表等长的向量,并将其元素都设置为0 for word in dataSeti: if word in self.vocabList: returnVec[self.vocabList.index(word)] = returnVec[self.vocabList.index(word)] + 1 self.VecList.append(returnVec) ## 词频与逆词频计算方法 def TFIDF(self): # 词频 = 某个词在本文档中出现的次数/本文档总词数 tf = [] for bagVeci in self.VecList: tf.append(bagVeci / np.sum(bagVeci)) # 逆文档频率(IDF) = log(文档总数/(包含该词的文档数+1)) ## 1.转换为词集模型,用于计算文档数 setVec = self.VecList for i in range(len(setVec)): for j in range(len(setVec[i])): if setVec[i][j] != 0: setVec[i][j] = 1 ## 2.计算文档总数 m = len(setVec) ## 3.包含该词的文档数 ndw = np.sum(setVec, axis=0) idf = np.log(m / (ndw + 1)) # TF-IDF = TF * IDF self.tfidf = tf * np.array(idf)
4. 文本特征向量化实战小结
综合以上步骤,经过类和函数封装,用户通过对象实例化和函数调用,只要输入待分词文本路径、停用词文件路径,即可完成指定目录下文件文本分词、字词清理、文本特征向量化等功能。
import os import jieba from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer import numpy as np ## 1. 遍历文件功能以类封装,遍历指定目录路径下文档,读取文档并返回文档内容 class loadFiles(): ''' 输入: 1. par_path 指定待遍历文件的目录路径 输出: 1. content 文档内容 ''' def __init__(self, par_path): self.par_path = par_path def __iter__(self): for file in os.listdir(self.par_path): # 遍历路径下所有文件 file_path = os.path.join(self.par_path, file) if os.path.isfile(file_path): # 判断是否为文件,以下仅针对文件进行操作 fin = open(file_path, 'rb') # rb读取方式更快 content = fin.read().decode('utf8') yield content fin.close() ## 2. 中文分词及清理以类封装,包括停用词文件路径初始化、加载停用词方法、中文文本分词及字词清洗方法 class StrCut(): ''' 输入: 1. stopwordPath 指定停用词文件路径 输出: 1. docResult 文档字词经分词及清理后的列表 ''' # 停用词文件路径初始化 def __init__(self, stopwordPath=r""): self.stopwordPath = stopwordPath self.stopwordList = [] # 加载停用词方法 def LoadStopword(self): with open(self.stopwordPath, 'r', encoding='utf-8') as f: self.stopwordList = f.read().split('\n') # 中文文本分词及字词清洗方法:去除停用词、去除数字、去除单个字符、去除空字符 def ClearWord(self, wordStr): docList = wordStr.split('\n') docResult = [] for docListi in docList: # jieba.cut()返回可迭代的 generator,使用list() 转换为列表对象 docListiCut = list(jieba.cut(docListi, cut_all=False)) for i in range(len(docListiCut))[::-1]: if docListiCut[i] in self.stopwordList: # 去除停用词 docListiCut.pop(i) elif docListiCut[i].isdigit(): # 去除数字 docListiCut.pop(i) elif len(docListiCut[i]) == 1: # 去除单个字符 docListiCut.pop(i) elif docListiCut[i] == " ": # 去除空字符 docListiCut.pop(i) docResult.extend(docListiCut) return docResult ## 文本特征向量化类 class TFIDF(): def __init__(self, dataSet): self.dataSet = dataSet # 数据集,列表形式,每个元素为一个文档的分词列表 self.vocabList = [] # 词集合,列表形式,所有文档词组集合(不重复) self.VecList = [] # 创建词向量 self.tfidf = [] # tfidf向量 ## 获取词集合方法:剔除重复词组,返回唯一词组元素的词列表 def createVocabList(self): vocabSet = set() for dataSeti in self.dataSet: vocabSet.update(dataSeti) self.vocabList = list(vocabSet) ## 文本向量化方法,统计各文档中字词的词频,组成向量形式 def bagOfWords2Vec(self): for dataSeti in self.dataSet: returnVec = [0] * len(self.vocabList) # 创建一个和词汇表等长的向量,并将其元素都设置为0 for word in dataSeti: if word in self.vocabList: returnVec[self.vocabList.index(word)] = returnVec[self.vocabList.index(word)] + 1 self.VecList.append(returnVec) ## 词频与逆词频计算方法:统计词频TF和逆词频IDF,以最终得到TF-IDF def TFIDF(self): # 词频 = 某个词在本文档中出现的次数/本文档总词数 tf = [] for bagVeci in self.VecList: tf.append(bagVeci / np.sum(bagVeci)) # 逆文档频率(IDF) = log(文档总数/(包含该词的文档数+1)) ## 1.转换为词集模型,用于计算文档数 setVec = self.VecList for i in range(len(setVec)): for j in range(len(setVec[i])): if setVec[i][j] != 0: setVec[i][j] = 1 ## 2.计算文档总数 m = len(setVec) ## 3.包含该词的文档数 ndw = np.sum(setVec, axis=0) idf = np.log(m / (ndw + 1)) # TF-IDF = TF * IDF self.tfidf = tf * np.array(idf) # if __name__ == "__main__": # ## 遍历文件功能类实例化 # path = "./sportnews/" # fileStrs = loadFiles(path) # ## 中文分词及清理类实例化 # stopwordPath = "./NLPIR_stopwords.txt" # fileCut = StrCut(stopwordPath) # fileCut.LoadStopword() ## 加载停用词 # ## 遍历文件,将所有字词合并到一个列表 # docList = [] # for i, fileStrsi in enumerate(fileStrs): # print("正在处理第{}篇文章……".format(i)) # docListi = fileCut.ClearWord(fileStrsi) # docList.append(docListi) # ## 文本特征向量化 # TF_IDF = TFIDF(docList) ## 文本特征向量化类实例化 # TF_IDF.createVocabList() ## 创建词汇表 # TF_IDF.bagOfWords2Vec() ## 创建词袋模型 # TF_IDF.TFIDF() ## 计算tfidf值向量 # print(TF_IDF.tfidf[0]) ## 访问第一篇文章的tfidf值向量
开始实验
第5节 附录
















 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











