









 本文介绍了如何使用Python的matplotlib库进行数据可视化,包括散点图、直方图、饼图和箱线图的绘制,以及如何处理numpy数据。同时展示了如何分析国民经济核算季度数据和人口数据的变化趋势。
本文介绍了如何使用Python的matplotlib库进行数据可视化,包括散点图、直方图、饼图和箱线图的绘制,以及如何处理numpy数据。同时展示了如何分析国民经济核算季度数据和人口数据的变化趋势。
一、实验目的
1、掌握pyplot常用的绘图参数调节方法;
2、掌握绘图子图的基本方法;
3、掌握绘制图形的保存和显示方法;
4、掌握散列图、折线图、直方图、饼图的作用和绘制方法。
二、实验要求
1、完成任务3.1-3.3部分代码,要求覆盖实验目的要求的散列图、折线图、直方图、饼图内容以及子图基本方法;
2、写出实验报告,内容要求有Python 代码和实验结果
3、鼓励大家给出不同的,更优的代码实现。
三、实验内容
1、完成实验要求1的任务,同时以文本文件或Excel文件展示文件国民经济核算季度数据.npz的数据;
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' #设置中文显示
plt.rcParams['axes.unicode_minus'] = False
data = np.load('D:/workspath/国民经济核算季度数据.npz',allow_pickle=True)
name = data['columns'] # 提取其中的columns数组,视为数据的标签
values = data['values'] # 提取其中的values数组,数据的存在位置
print(name)
print(values)
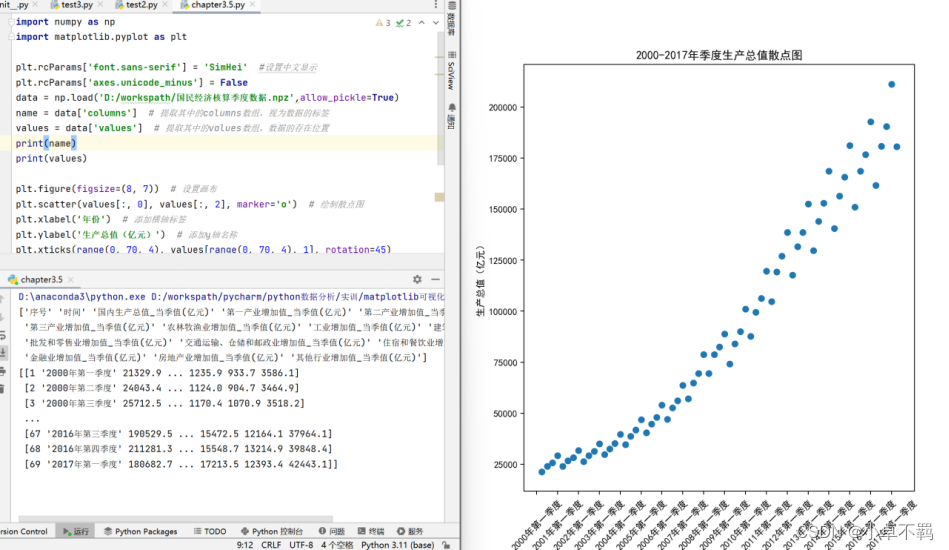
# 散点图
plt.figure(figsize=(8, 7)) # 设置画布
plt.scatter(values[:, 0], values[:, 2], marker='o') # 绘制散点图
plt.xlabel('年份') # 添加横轴标签
plt.ylabel('生产总值(亿元)') # 添加y轴名称
plt.xticks(range(0, 70, 4), values[range(0, 70, 4), 1], rotation=45)
plt.title('2000-2017年季度生产总值散点图') # 添加图表标题
plt.savefig("./2000-2017年季度生产总值散点图.png")
#直方图
label1 = ['第一产业','第二产业','第三产业']## 刻度标签1
label2 = ['农业','工业','建筑','批发','交通',
'餐饮','金融','房地产','其他']## 刻度标签2
p = plt.figure(figsize=(12,12))
ax1 = p.add_subplot(2,2,1)
plt.bar(range(3),values[0,3:6],width = 0.5)
plt.xlabel('产业')
plt.ylabel('生产总值(亿元)')
plt.xticks(range(3),label1)
plt.title('2000年第一季度国民生产总值产业构成分布直方图')
ax2 = p.add_subplot(2,2,2)
plt.bar(range(3),values[-1,3:6],width = 0.5)
plt.xlabel('产业')
plt.ylabel('生产总值(亿元)')
plt.xticks(range(3),label1)
plt.title('2017年第一季度国民生产总值产业构成分布直方图')
ax3 = p.add_subplot(2,2,3)
plt.bar(range(9),values[0,6:],width = 0.5)
plt.xlabel('行业')
plt.ylabel('生产总值(亿元)')
plt.xticks(range(9),label2)
plt.title('2000年第一季度国民生产总值行业构成分布直方图')
ax4 = p.add_subplot(2,2,4)
plt.bar(range(9),values[-1,6:],width = 0.5)
plt.xlabel('行业')
plt.ylabel('生产总值(亿元)')
plt.xticks(range(9),label2)
plt.title('2017年第一季度国民生产总值行业构成分布直方图')
plt.savefig('./国民生产总值构成分布直方图.png')
#饼图
explode1 = [0.01,0.01,0.01]
explode2 = [0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.01]
p = plt.figure(figsize=(12,12))
ax1 = p.add_subplot(2,2,1)
plt.pie(values[0,3:6],explode=explode1,labels=label1,
autopct='%1.1f%%')
plt.title('2000年第一季度国民生产总值产业构成分布饼图')
ax2 = p.add_subplot(2,2,2)
plt.pie(values[-1,3:6],explode=explode1,labels=label1,
autopct='%1.1f%%')
plt.title('2017年第一季度国民生产总值产业构成分布饼图')
ax3 = p.add_subplot(2,2,3)
plt.pie(values[0,6:],explode=explode2,labels=label2,
autopct='%1.1f%%')
plt.title('2000年第一季度国民生产总值行业构成分布饼图')
ax4 = p.add_subplot(2,2,4)
plt.pie(values[-1,6:],explode=explode2,labels=label2,
autopct='%1.1f%%')
plt.title('2017年第一季度国民生产总值行业构成分布饼图')
plt.savefig('./国民生产总值构成分布饼图.png')
#箱线图
gdp = (list(values[:,3]),list(values[:,4]),list(values[:,5]))
plt.figure(figsize=(6,4))
plt.boxplot(gdp,notch=True,labels = label1, meanline=True)
plt.title('2000-2017各产业国民生产总值箱线图')
plt.savefig('./2000-2017各产业国民生产总值箱线图.png')
plt.show()



2、分析populations.npz 中1996-2015年人口数据特征间的关系
(1)使用Numpy库读取人口数据;
(2)创建画布,并添加子图;
(3)分别绘制散点图和折线图并保存图片;
(4)分析未来人口变化趋势。
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
data = np.load('D:/workspath/populations.npz', allow_pickle=True)
def getKeys(data):
ks = []
for i in data.keys():
ks.append(i)
return ks
keys = getKeys(data)
name = data[keys[1]]
values = data[keys[0]][-3::-1, :]
print(name, '\n', values)
p1 = plt.figure(figsize=(14, 7))
ax1 = p1.add_subplot(1, 2, 1)
plt.title('1996-2015年人口数据特征间的关系散点图')
plt.xlabel('年份')
plt.ylabel('人口数(万人)')
plt.xticks(range(0, 20), values[:, 0], rotation=45)
plt.scatter(values[:, 0], values[:, 1], marker='o', c='r')
plt.scatter(values[:, 0], values[:, 2], marker='D', c='b')
plt.scatter(values[:, 0], values[:, 3], marker='h', c='g')
plt.scatter(values[:, 0], values[:, 4], marker='s', c='y')
plt.scatter(values[:, 0], values[:, 5], marker='*', c='c')
plt.legend(['年末总人口', '男性人口', '女性人口', '城镇人口', '乡村人口'])
plt.savefig('D:/workspath/1996-2015年人口数据特征间的关系散点图.png')
# 折线图
ax2 = p1.add_subplot(1, 2, 2)
plt.title('1996-2015年人口数据特征间的关系折线图')
plt.xlabel('年份')
plt.ylabel('人口数(万人)')
plt.xticks(range(0, 20), values[:, 0], rotation=45)
plt.plot(values[:, 0], values[:, 1], 'rs-', values[:, 0], values[:, 2], 'bd-.',
values[:, 0], values[:, 3], 'gh--', values[:, 0], values[:, 4], 'y*:',
values[:, 0], values[:, 5], 'cv-.')
plt.legend(['年末总人口', '男性人口', '女性人口', '城镇人口', '乡村人口'])
plt.savefig('D:/workspath/1996~2015年人口数据特征间关系散点图和折线图.png')
plt.show()

3、分析populations.npz 中1996-2015年人口数据各个特征的分布和分散情况。
(1)掌握直方图、饼图和箱线图绘制方法;
(2)分析发现人口结构变化情况。
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
data = np.load('D:/workspath/populations.npz', allow_pickle=True)
def getKeys(data):
ks = []
for i in data.keys():
ks.append(i)
return ks
keys = getKeys(data)
name = data[keys[1]]
values = data[keys[0]][-3::-1, :]
print(name, '\n', values)
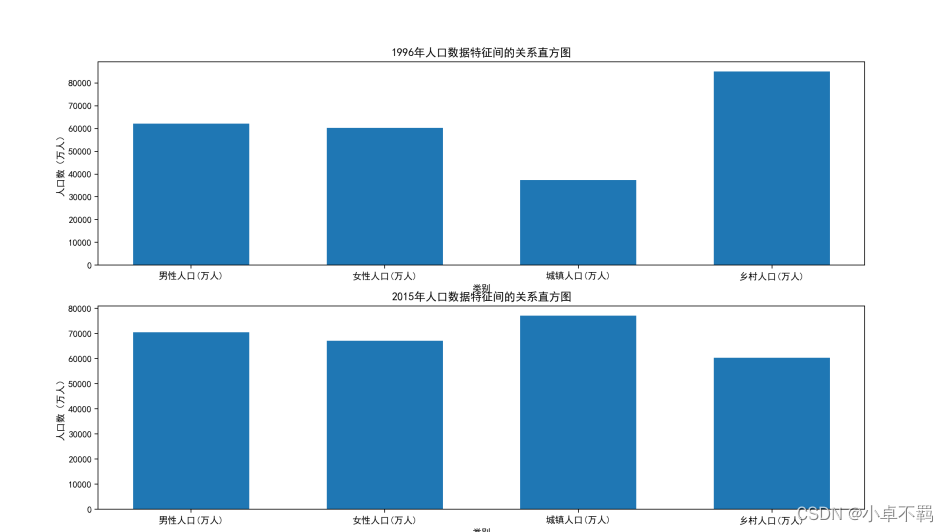
#直方图
p1 = plt.figure(figsize=(15,15)) #设置画布
p1.add_subplot(2,1,1)
plt.bar(range(4),values[0,2:6],width=0.6)
plt.xlabel('类别'),plt.ylabel('人口数(万人)')
plt.xticks(range(4),name[2:6])
plt.title('1996年人口数据特征间的关系直方图')
p1.add_subplot(2,1,2)
plt.bar(range(4),values[-1,2:6],width=0.6)
plt.xlabel('类别'),plt.ylabel('人口数(万人)')
plt.xticks(range(4),name[2:6])
plt.title('2015年人口数据特征间的关系直方图')
plt.savefig('./1996与2015年人口数据特征间关系直方图.png')
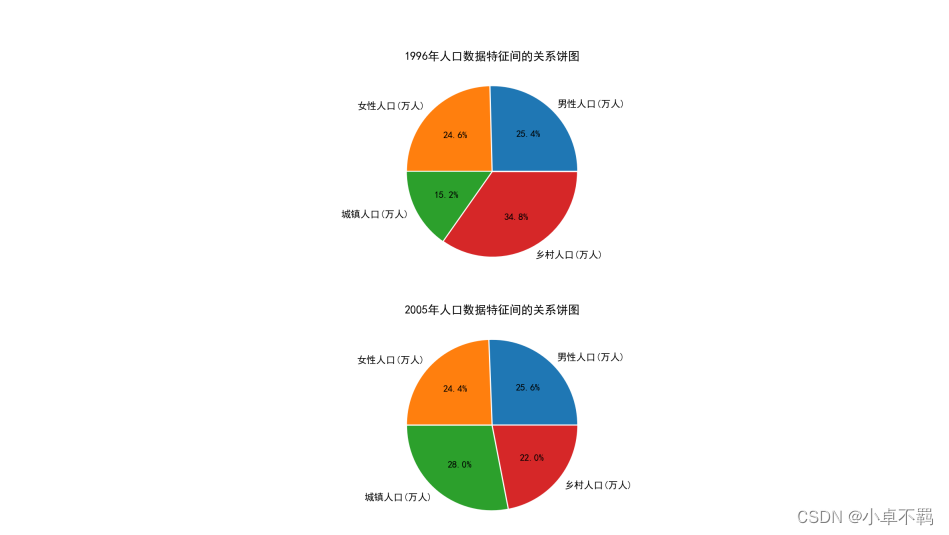
#饼状图
p2=plt.figure(figsize=(15,15)) #设置画布
explode=np.linspace(0.01,0.01,4)
p2.add_subplot(2,1,1)
plt.title('1996年人口数据特征间的关系饼图')
plt.pie(values[0,2:6],explode=explode,labels=name[2:6],autopct='%1.1f%%')
p2.add_subplot(2,1,2)
plt.title('2005年人口数据特征间的关系饼图')
plt.pie(values[-1,2:6],explode=explode,labels=name[2:6],autopct='%1.1f%%')
plt.savefig('./1996与2015年人口数据特征间关系饼状图.png')
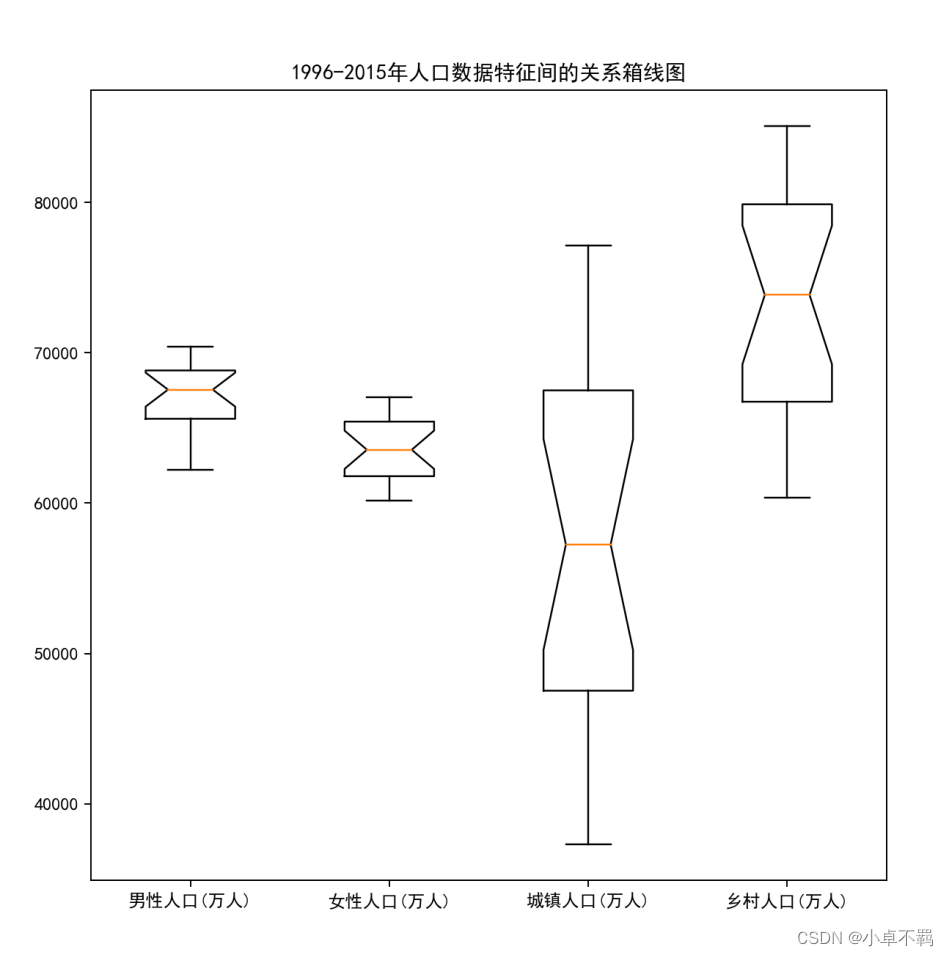
#箱线图
p2=plt.figure(figsize=(8,8)) #设置画布
plt.title('1996-2015年人口数据特征间的关系箱线图')
gdp=(list(values[:,2]),list(values[:,3]),list(values[:,4]),list(values[:,5]))
plt.boxplot(gdp,notch=True,labels=name[2:6],meanline=True)
plt.savefig('./1996~2015年人口数据特征间关系箱线图.png')
plt.show()
- 针对Mushroom.csv进行初步数据分析
(1)用直方图展示每种菌盖的颜色分布、菌气味分布;
(2)用直方图展示是否有毒蘑菇的颜色分布;是否有毒蘑菇的菌气味分布;
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv('D:/workspath/mushrooms.csv')
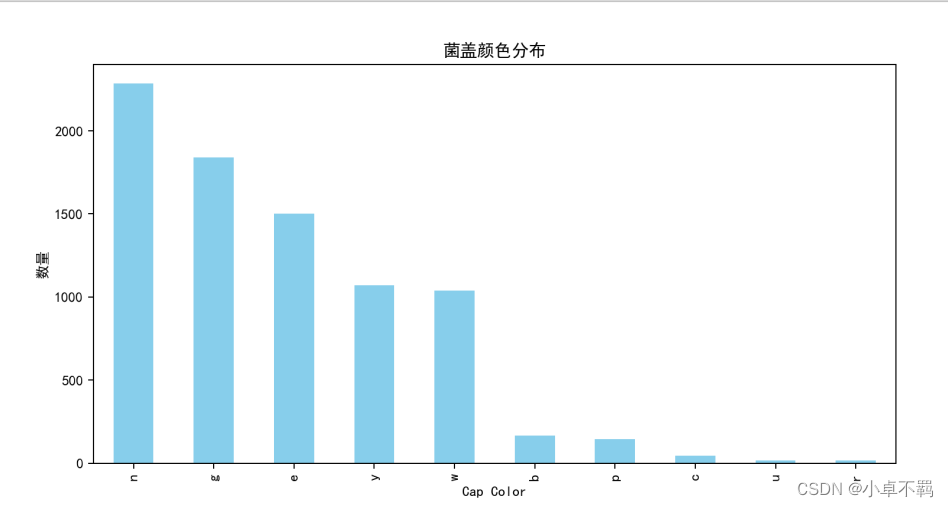
# 菌盖颜色分布
plt.figure(figsize=(10, 5)) # 设置大小
df['cap-color'].value_counts().plot(kind='bar', color='skyblue')
plt.title('菌盖颜色分布')
plt.xlabel('Cap Color')
plt.ylabel('数量')
plt.savefig('./菌盖颜色分布直方图.png')
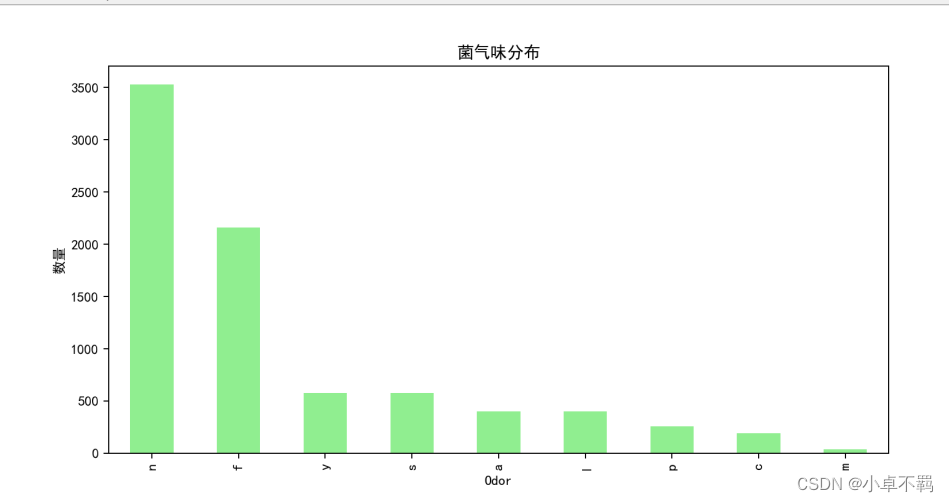
# 菌气味分布
plt.figure(figsize=(10, 5))
df['odor'].value_counts().plot(kind='bar', color='lightgreen')
plt.title('菌气味分布')
plt.xlabel('Odor')
plt.ylabel('数量')
plt.savefig('./菌气味分布直方图.png')
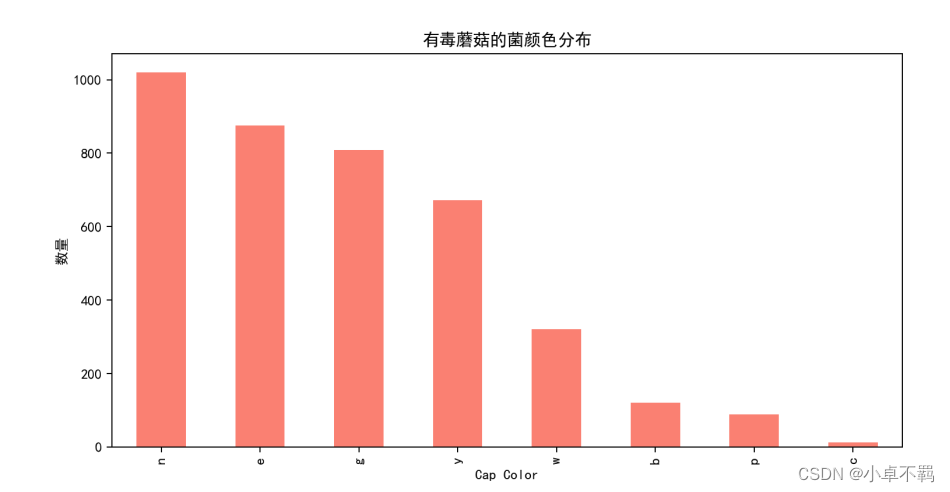
# 有毒蘑菇的颜色分布
poisonous_df = df[df['class'] == 'p']
plt.figure(figsize=(10, 5))
poisonous_df['cap-color'].value_counts().plot(kind='bar', color='salmon')
plt.title('有毒蘑菇的菌颜色分布')
plt.xlabel('Cap Color')
plt.ylabel('数量')
plt.savefig('./有毒蘑菇颜色分布直方图.png')
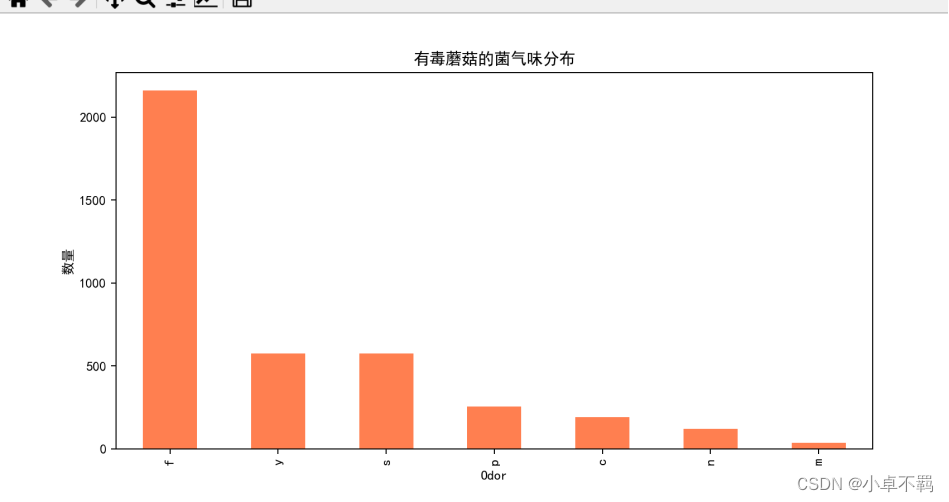
# 有毒蘑菇的菌气味分布
plt.figure(figsize=(10, 5))
poisonous_df['odor'].value_counts().plot(kind='bar', color='coral')
plt.title('有毒蘑菇的菌气味分布')
plt.xlabel('Odor')
plt.ylabel('数量')
plt.savefig('./有毒蘑菇气味分布直方图.png')
plt.show()
















 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









