









在并行计算中,MPI是一种常用的并行编程模型,用于在多个处理器之间进行通信和数据交换。尽管MPI为并行程序提供了强大的通信功能,但在实际应用中,由于各种因素,例如网络延迟、节点故障或编程错误,MPI程序可能会遇到各种报错。其中,报错集合是MPI程序中一个常见且重要的问题,作为MPI新人,记录一下日常报错和解决过程,避免在同一个坑上反复横跳。
ERROR-01
Project1.exe ended prematurely and may have crashed. exit code 0xc0000005
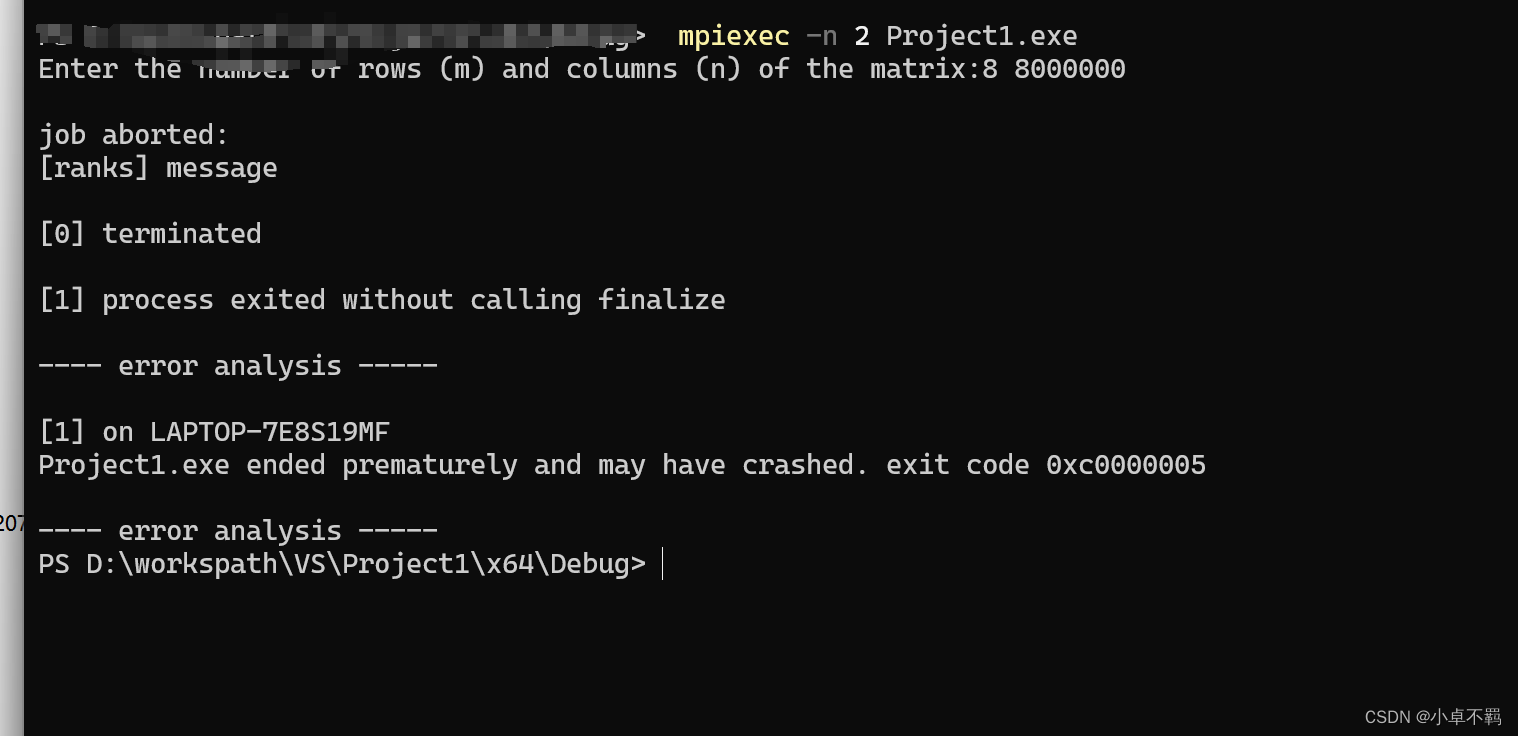
原因:Project1.exe过早结束,可能已经崩溃。退出代码 0xc0000005
分析原因:可能是发生内存冲突,可能会导致内存冲突的地方:
- 循环并行化
- 数据共享和同步
- 动态内存分配
内存冲突是指在多个线程同时访问同一块内存区域时发生的竞争条件。当多个线程试图同时读取或写入相同的内存地址时,就可能会发生内存冲突。这种情况下,程序可能会产生不可预测的结果,导致程序崩溃、数据损坏或者其他问题。为避免内存冲突,需要采用同步机制,如锁、信号量等,来控制并发访问。
解决方案:
- 在并行循环中使用原子操作或者对结果向量进行分块处理来减少竞争条件。
- 在 MPI 中使用适当的同步操作,例如 MPI_Reduce 或者 MPI_Gather 来合并结果。
- 使用静态内存分配或者并行环境下的内存池管理来避免动态内存分配带来的性能问题。
void matrixVectorMultiplication(int** matrix, int* vector, int* result, int rows, int cols) { //矩阵-向量乘法运算
#pragma omp parallel for
for (int i = 0; i < rows; ++i) {
result[i] = 0;
for (int j = 0; j < cols; ++j) {
result[i] += matrix[i][j] * vector[j];
}
}
}
修改后代码:
void matrixVectorMultiplication(int** matrix, int* vector, int* result, int rows, int cols) {
#pragma omp parallel for
for (int i = 0; i < rows; ++i) {
int partialResult = 0;
for (int j = 0; j < cols; ++j) {
partialResult += matrix[i][j] * vector[j];
}
result[i] = partialResult; // 独立写入每个结果元素,避免竞争条件
}
}
ERROR-02
Run-Time Check Failure #3 - The variable 'm' is being used withoutbeing initialized.
(Press Retry to debug the application)

原因:在代码中使用了未初始化的变量 m,导致了运行时检查失败(进程>2时出现)
解决方案:
- 初始化变量 m:在使用变量 m 之前,确保对其进行初始化赋值
- 避免悬空引用: 确保变量 m 在使用前被正确赋值。如果 m 是对象或指针,确保它指向有效的内存位置或已经被正确初始化
- 检查代码逻辑: 检查代码逻辑,确保变量 m 在使用之前没有被遗漏初始化。有时候复杂的控制流或条件分支可能导致某些情况下变量未被初始化
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
int rank, size;
int n ,m ;
double start_time, end_time, parallel_start_time, parallel_end_time;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (rank == 0) {//零号进程
printf("Enter the number of rows (m) and columns (n) of the matrix:");
fflush(stdout);
scanf_s("%d %d", &m,&n); //录入数据
}
}
修改后代码:
int main(int argc, char* argv[]) {
MPI_Init(&argc, &argv);
int rank, size;
int n = 1,m = 1; //初始化赋值
double start_time, end_time, parallel_start_time, parallel_end_time;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (rank == 0) {//零号进程
printf("Enter the number of rows (m) and columns (n) of the matrix:");
fflush(stdout);
scanf_s("%d %d", &m,&n); //录入数据
}
在MPI并行计算中,处理报错集合是保证程序正确性和性能的关键一环。通过了解MPI报错集合的原因、影响以及解决方法,可以帮助我们更好地编写健壮、高效的MPI程序,并及时解决可能出现的问题,从而提高并行计算的可靠性和性能。















 6846
6846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









