






 本文是Spark大数据处理的学习笔记,涵盖了Executor(执行器)、Task(任务)、Job(作业)和Stage(阶段)的基本概念,以及Spark集群运行架构和运行流程,包括资源申请、Executor启动、Task调度和注销等关键步骤。
本文是Spark大数据处理的学习笔记,涵盖了Executor(执行器)、Task(任务)、Job(作业)和Stage(阶段)的基本概念,以及Spark集群运行架构和运行流程,包括资源申请、Executor启动、Task调度和注销等关键步骤。
目录
一、基本概念
(一)Executor(执行器)
- 在集群工作节点上为某个应用启动的工作进程,该进程负责运行计算任务,并为应用程序存储数据。
(二)Task(任务)
- 运行main()方法并创建SparkContext的进程
(三)Job(作业)
- 一个并行计算作业,由一组任务组成,并由Spark的行动算子(如:save、collect)触发启动。
(四)Stage(阶段)
- 每个Job可划分为更小的Task集合,每组任务被称为Stage。
二、Spark集群运行架构
- Spark运行架构主要由SparkContext、Cluster Manager和Worker组成,其中Cluster Manager负责整个集群的统一资源管理,Worker节点中的Executor是应用执行的主要进程,内部含有多个Task线程以及内存空间,通过下图深入了解Spark运行基本流程。
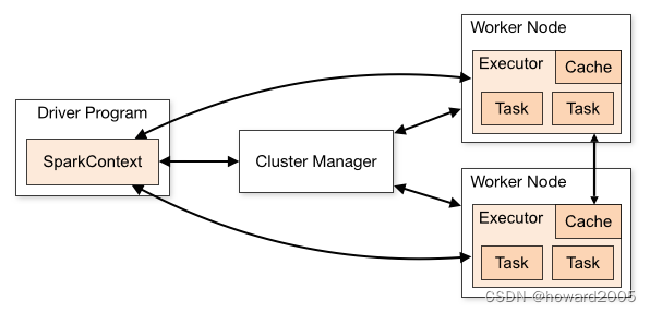
- Spark有多种运行模式,可以运行在一台机器上,称为本地(单机)模式,也可以以YARN或Mesos作为底层资源调度系统以分布式的方式在集群中运行,称为Spark On YARN模式,还可以使用Spark自带的资源调度系统,称为Spark Standalone模式。
- 本地模式通过多线程模拟分布式计算,通常用于对应用程序的简单测试。本地模式在提交应用程序后,将会在本地生成一个名为SparkSubmit的进程,该进程既负责程序的提交,又负责任务的分配、执行和监控等。
三、Spark运行基本流程
- Spark应用在集群上作为独立的进程组来运行,具体运行流程如下图所示
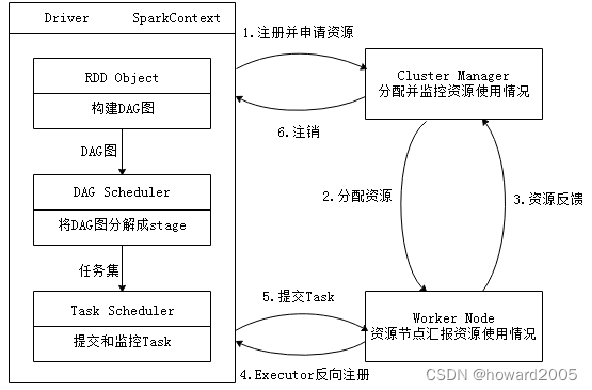
步骤1、注册并申请资源
- 当一个Spark应用被提交时,根据提交参数创建Driver进程,Driver进程初始化SparkContext对象,由SparkContext负责和Cluster Manager的通信以及资源的申请、任务的分配和监控等。
步骤2、分配资源
- Driver进程向Cluster Manager申请资源,Cluster Manager接收到Application的注册请求后,会使用自己的资源调度算法,在Spark集群的Worker节点上,通知Worker为应用启动多个Executor。
步骤3、资源反馈
- Executor创建后,会向Cluster Manager进行资源及状态的反馈,便于Cluster Manager对Executor进行状态监控,如果监控到Executor失败,则会立刻重新创建。
步骤4、Executor发现注册
- Executor会向SparkContext反向注册申请Task。
步骤5、提交Task
- Task Scheduler将Task发送给Worker进程中的Executor运行并提供应用程序代码。
步骤6、注销
- 当程序执行完毕后写入数据,Driver向Cluster Manager注销申请的资源。















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









