







python岗位数据分析报告
数据集为针对智联,boss,拉勾三个招聘网站的爬取,
爬取关键字段:语言为python,java,c;城市为 北上广深郑杭;
数据分类保存在 ‘’python招聘数据.xlsx‘’ 表格中
研究问题 :
一. python相关岗位(数据分析,数据挖掘,开发工程师)地区(北京地区内)分布
(1) 数据处理
# 导入模块
import pandas as pd
# 读取数据
full_data = pd.read_excel('python招聘数据.xlsx',sheet_name=None)
print(full_data)
# 研究问题 1:python相关岗位(数据分析,数据挖掘,开发工程师)地区(北京地区内)分布(最新数据,就业参考)
# 取出北京数据分析岗,并按职位链接去重
analysis_data = full_data['数据分析岗'][['job_link','job_area']].drop_duplicates(subset=['job_link'],keep='first')
# 取出北京数据挖掘岗,并按职位链接去重
mining_data = full_data['数据挖掘岗'][['job_link','job_area']].drop_duplicates(subset=['job_link'],keep='first')
# 取出北京python开发岗,并按职位链接去重
Python_data = full_data['python岗位'][['job_link','job_area']].drop_duplicates(subset=['job_link'],keep='first')
python_data_1 = full_data['job_zhou'].loc[full_data['job_zhou']['city']=='北京']
python_data_1 = python_data_1[['positionURL','city_area']].drop_duplicates(subset=['positionURL'],keep='first')
python_data_1['city_area'] = python_data_1['city_area'].agg(lambda i: i.split('-')[1] if '-' in i else '无')
python_data_1.rename(columns={'positionURL':'job_link','city_area':'job_area'},inplace=True)
# print(analysis_data)
# print(mining_data)
# print(Python_data)
# print(python_data_1)
total_data = pd.DataFrame()
for i in [analysis_data,mining_data,Python_data,python_data_1]:
total_data = total_data.append(i)
beijing_diagram=total_data.groupby(by='job_area')['job_link'].size()
print(beijing_diagram)
(2) 数据可视化
# 数据可视化
from pyecharts import options as opts
from pyecharts.charts import Map3D
from pyecharts.globals import ChartType
from pyecharts.commons.utils import JsCode
example_data = [
('天安门', [116.38, 39.9, int(beijing_diagram.get('天安门',0))]),
('东城区', [116.42, 39.93, int(beijing_diagram.get('东城区', 0))]),
('西城区', [116.37, 39.92, int(beijing_diagram.get('西城区', 0))]),
('崇文区', [116.43, 39.88, int(beijing_diagram.get('崇文区', 0))]),
('宣武区', [116.35, 39.87, int(beijing_diagram.get('宣武区', 0))]),
('朝阳区', [125.28, 43.83, int(beijing_diagram.get('朝阳区', 0))]),
('丰台区', [116.28, 39.85, int(beijing_diagram.get('丰台区', 0))]),
('石景山区', [116.22, 39.9, int(beijing_diagram.get('石景山区', 0))]),
('海淀区', [116.3, 39.95, int(beijing_diagram.get('海淀区', 0))]),
('门头沟区', [116.1, 39.93, int(beijing_diagram.get('门头沟区', 0))]),
('房山区', [116.13, 39.75, int(beijing_diagram.get('房山区', 0))]),
('通州区', [116.65, 39.92, int(beijing_diagram.get('通州区', 0))]),
('顺义区', [116.65, 40.13, int(beijing_diagram.get('顺义区', 0))]),
('昌平区', [116.23, 40.22, int(beijing_diagram.get('昌平区', 0))]),
('大兴区', [116.33, 39.73, int(beijing_diagram.get('大兴区', 0))]),
('怀柔区', [116.63, 40.32, int(beijing_diagram.get('怀柔区', 0))]),
('平谷区', [117.12, 40.13, int(beijing_diagram.get('平谷区', 0))]),
('密云县', [116.83, 40.37, int(beijing_diagram.get('密云县', 0))]),
('延庆县', [115.97, 40.45, int(beijing_diagram.get('延庆县', 0))]),
]
print(example_data)
#
c = (
Map3D()
.add_schema(
maptype='北京',
itemstyle_opts=opts.ItemStyleOpts(
color="rgb(5,101,123)",
opacity=1,
border_width=0.8,
border_color="rgb(62,215,213)",
),
map3d_label=opts.Map3DLabelOpts(
is_show=False,
formatter=JsCode("function(data){return data.name + " " + data.value[2];}"),
),
emphasis_label_opts=opts.LabelOpts(
is_show=False,
color="#fff",
font_size=10,
background_color="rgba(0,23,11,0)",
),
light_opts=opts.Map3DLightOpts(
main_color="#fff",
main_intensity=1.2,
main_shadow_quality="high",
is_main_shadow=False,
main_beta=10,
ambient_intensity=0.3,
),
)
.add(
series_name="招聘岗位频数",
data_pair=example_data,
type_=ChartType.BAR3D,
bar_size=1,
shading="lambert",
label_opts=opts.LabelOpts(
is_show=True,
formatter=JsCode("function(data){return data.name + ' ' + data.value[2];}"),
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="北京市各区县python招聘分布"))
.render_notebook())
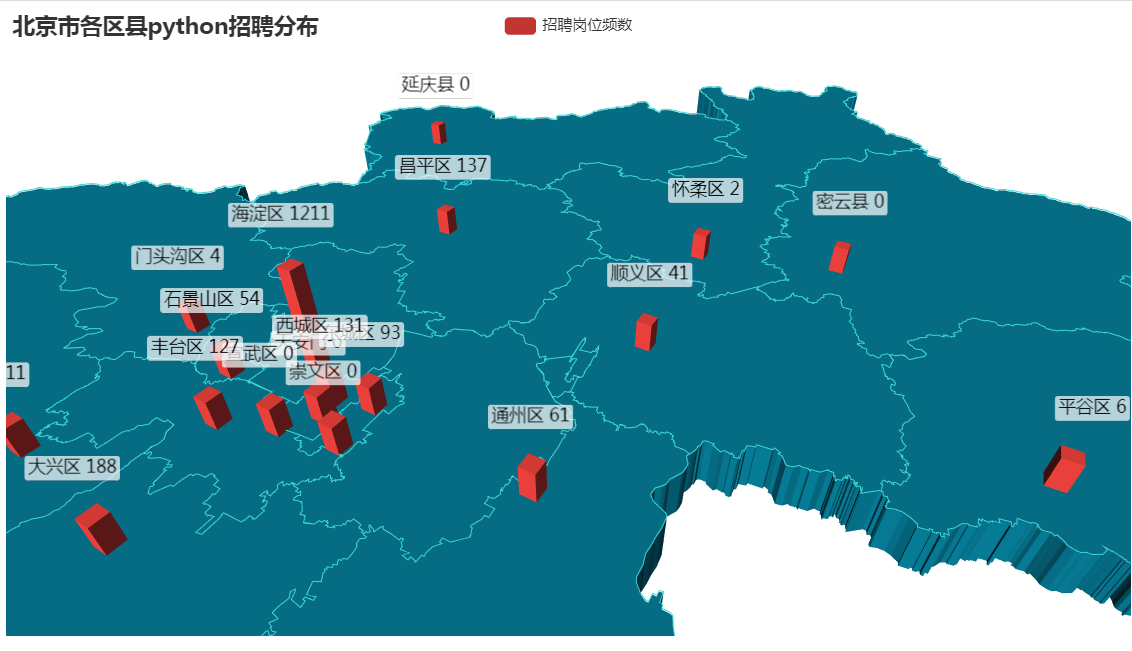
(3) 结论:
# 招聘地区主要集中2~3环内,海淀区居首位
二 . python相关岗位(数据分析,数据挖掘,开发工程师等)学历要求(北京)
(1) 数据处理
# 2.python相关岗位(数据分析,数据挖掘,开发工程师等)学历要求(北京)(饼图)
# 取出北京数据分析岗,并按职位链接去重
analysis_data = full_data['数据分析岗'][['job_link','education']].drop_duplicates(subset=['job_link'],keep='first')
# 取出北京数据挖掘岗,并按职位链接去重
mining_data = full_data['数据挖掘岗'][['job_link', 'education']].drop_duplicates(subset=['job_link'], keep='first')
# 取出python岗表和job-zhou表两表中北京python开发岗合并,并按职位链接去重
Python_data = full_data['python岗位'][['job_link', 'education']]
python_data_1 = full_data['job_zhou'].loc[full_data['job_zhou']['city'] == '北京'][['positionURL', 'eduLevel']]
python_data_1.rename(columns={'positionURL': 'job_link', 'eduLevel': 'education'}, inplace=True)
df = pd.DataFrame()
for i in [Python_data,python_data_1]:
df = df.append(i)
df.drop_duplicates(subset=['job_link'], keep='first')
print(analysis_data)
print(mining_data)
print(df)
(2) 数据可视化
# 数据可视化
analysis_edu_res = analysis_data.groupby(by='education')['job_link'].size()
mining_edu_res = mining_data.groupby(by='education')['job_link'].size()
python_edu_res = df.groupby(by='education')['job_link'].size()
from pyecharts import options as opts
from pyecharts.charts import Pie, Grid
pie_scheme =[]
for i,j in enumerate([analysis_edu_res,mining_edu_res,python_edu_res]):
pie = Pie()
pie.add(series_name='学历', data_pair=[(k,v)for k,v in zip(j.index,j.values.tolist())],
radius=['25%','50%'], label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2, }}))
title_list = ['数据分析学历占比','数据挖掘学历占比','Python开发学历占比']
pie.set_global_opts(title_opts=opts.TitleOpts(title=title_list[i]))
pie_scheme.append(pie)
for i, k in enumerate(pie_scheme):
k.render(title_list[i]+'.html')
# grid = Grid()
# grid.add(pie_scheme[0], grid_opts=opts.GridOpts(pos_left="30%"))
# grid.add(pie_scheme[1], grid_opts=opts.GridOpts(pos_right="60%"))
# grid.add(pie_scheme[2], grid_opts=opts.GridOpts(pos_right="80%"))
# grid.render("grid_horizontal.html")
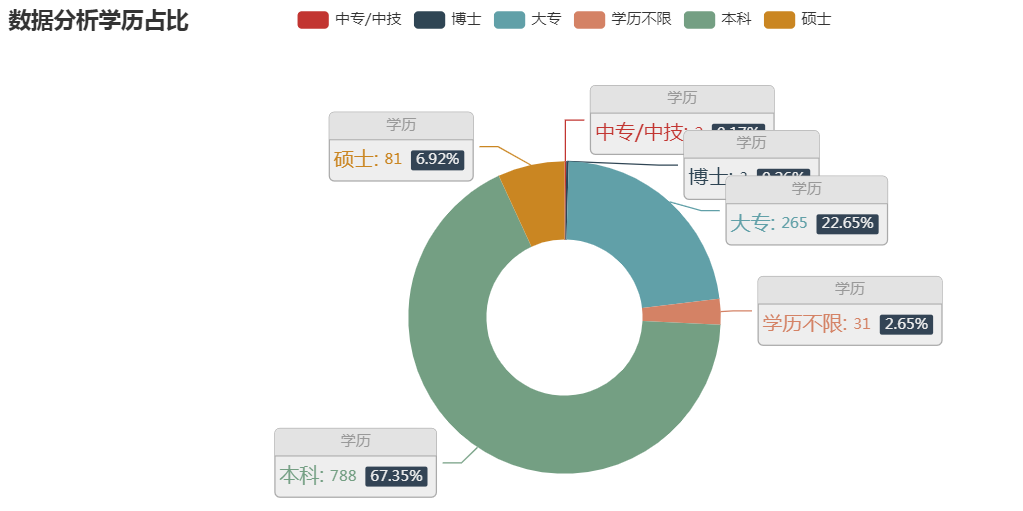
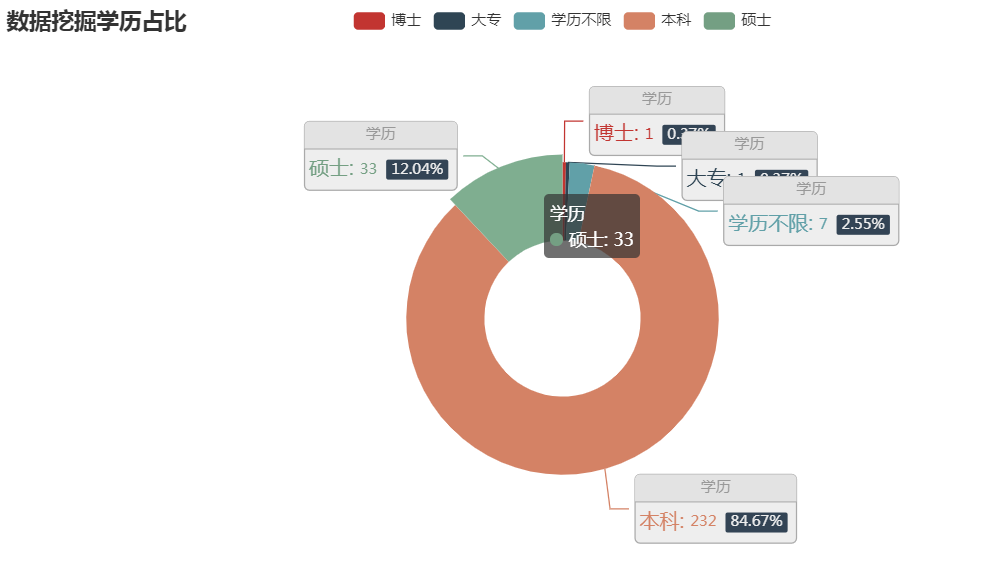
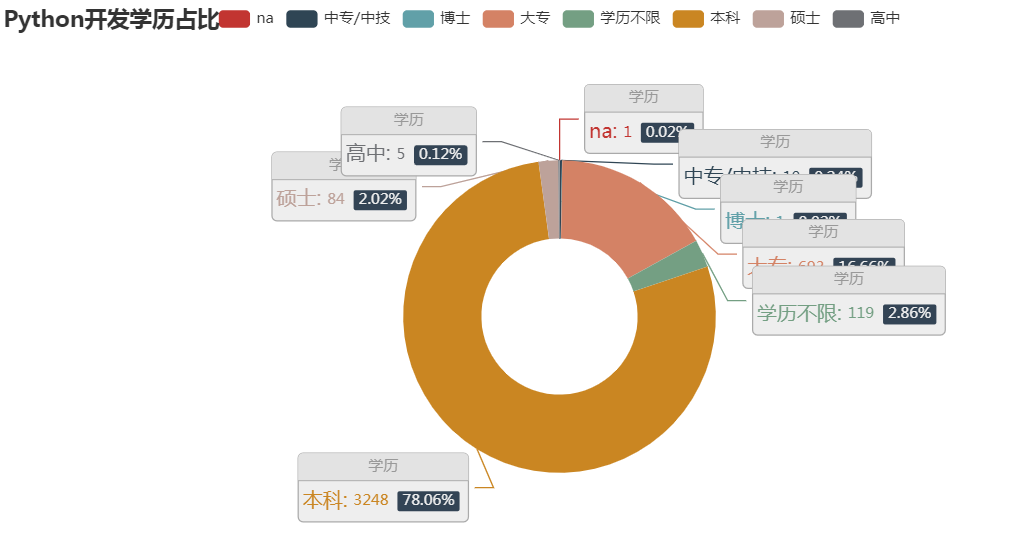
(3) 结论:
# 三种python相关岗位中,本科学历占主导地位(由于数据分析和数据挖掘数据过少,且爬取的单一招聘网站(boss直聘)分析上存在误差))
三 . python不同岗位职能(数据分析,数据挖掘,开发工程师等)侧重点(北京)
(1) 数据处理
# 3.python不同岗位职能(数据分析,数据挖掘,开发工程师等)侧重点(北京)(词云图)
import jieba
from wordcloud import WordCloud
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
# 采用jieba分词处理
sjfx = full_data['数据分析岗'][['job_info', 'job_link']].drop_duplicates(subset=['job_link'])
sjfx.dropna(subset=['job_info'], inplace=True, how='any')
sjfx['job_info'] = sjfx['job_info'].astype(str)
sjfx_info = ''.join(sjfx['job_info'])
text_list = [i for i in jieba.cut(sjfx_info) if i.isalpha()]
# 删除任职和要求等标题字眼
for i in ['任职', '要求']:
while text_list.count(i):
text_list.remove(i)
# 使用PLT加载图像掩码
mask = np.array(Image.open('./bianfu.jpg'))
# 使用Wordcloud配合Matplotlab生成词云图
wordcloud = WordCloud(font_path='simfang.ttf', mask=mask, background_color='white')
w = wordcloud.generate(' '.join(text_list))
plt.imshow(w)
plt.axis('off')#不显示坐标轴
plt.show()
(2) 数据可视化

(3) 结论:
# 由于时间原因只分析了数据分析岗,(数据挖掘岗,python岗同理)由图可看对于数据分析岗比较注重相关行业分析经验
四 . 研究python相关岗位工作经验与薪资的关系(北上广深郑杭)
(1) 数据处理
# 4.研究python相关岗位工作经验与薪资的关系(北上广深郑杭)(折线图)
import re
p = re.compile(r'[K-]+')
exp_salary = full_data['job_zhou'][['workingExp', 'salary']].copy()
# 去除薪资面议和,经验不限数据
mask = ~((exp_salary['workingExp'] == '不限') | (exp_salary['salary'] == '薪资面议'))
new_exp_salary = exp_salary.loc[mask].copy()
def salary_split(val):
return p.split(val)
def salary_hander(val):
try:
return float(val[1])
except:
return float(val[0])
# 切分工资范围(13K-15k),到最大值,最小值
new_exp_salary['salary'] = new_exp_salary['salary'].agg(salary_split)
new_exp_salary['salary_min'] = new_exp_salary['salary'].agg(lambda i: float(i[0]))
new_exp_salary['salary_max'] = new_exp_salary['salary'].agg(salary_hander)
exp_salary_relation = new_exp_salary.groupby(by='workingExp')[['salary_min','salary_max']].mean()
print(exp_salary_relation.sort_values(by='salary_min'))
# 数据保留2位小数,使用round()函数四舍五入返回新df
exp_salary_relation = exp_salary_relation.round(2)
print(exp_salary_relation)
(2) 数据可视化
# 数据可视化
import pyecharts.options as opts
from pyecharts.charts import Line
x_data = [i for i in exp_salary_relation.index]
print(x_data)
y_data_min = exp_salary_relation['salary_min'].values.tolist()
y_data_max = exp_salary_relation['salary_max'].values.tolist()
line = Line(init_opts=opts.InitOpts(width="1000px", height="400px"))
line.add_xaxis(xaxis_data=x_data)
line.add_yaxis(series_name='平均最低薪资',y_axis=y_data_min,)
line.add_yaxis(
series_name="平均最高薪资",
y_axis=y_data_max,
)
line.set_global_opts(
title_opts=opts.TitleOpts(title="薪资随工作经验变化图"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True, orient='horizontal'),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False,name='工作经验年限'),
yaxis_opts=opts.AxisOpts(type_='value',name='平均最低和最高薪资(单位:k)')
)
line.render('工作经验与薪资关系.html')

(3) 结论:
# 随着工作经验的增加,薪资呈现明显上升趋势,工作三年基本破万(看看伪装多少工作经验)
五 . 研究不同语言(java,c,c++,c#,python)语言受欢迎度(北上广深郑杭)
(1) 数据处理
# 5.研究不同语言(java,c,c++,c#,python)语言的需求量(北上广深郑杭)(3D柱状图)
import json
different_language_needs_data = pd.read_excel('job_.xlsx')
different_language_needs_data.drop_duplicates(subset=['positionURL'], inplace=True)
def json_parse(val):
data_list = json.loads(val)
res = '|'.join(data_list)
return res
different_language_needs_data['skill'] = different_language_needs_data['skill'].agg(json_parse)
new_columns = different_language_needs_data['skill'].str.split('|', expand=True).stack().reset_index(level=1,drop=True).rename('skill_')
new_different_language_needs_data = different_language_needs_data.join(new_columns)
out = pd.crosstab(index=new_different_language_needs_data['city'],columns=new_different_language_needs_data['skill_'])
# for i in out.columns:
# print(i)
print(out)
# c类:精通C语言,熟练掌握C/C++,C,C++,熟练掌握/C+C+,游戏C++服务器,C#
# java类:精通JAVASCRIPT,前端 JAVASCRIPT,spring框架,java爬虫,SPRINGMVC,Java,JAVA
# python类: PANDAS,爬虫,爬虫工程师,requests,python爬虫,Scrapy,Scipy,PyCharm,Python,Python,PYTHON
def func_cal(type_, columns):
# 添加c语言类
out['flag'] = 0
if type_ == 'c':
for i in columns:
if 'C' in i:
out['flag'] += out[i]
return out['flag']
if type_ == 'java':
for i in columns:
if ('spring' in i) or ('JAVA' in i) or ('java' in i) or ('Java' in i) or ('SPRING' in i):
out['flag'] += out[i]
return out['flag']
if type_ == 'python':
for i in columns:
if ('PANDAS' in i) or ('requests' in i) or (('爬虫' in i) and ('java' not in i)) or ('python爬虫' in i) or (
'Scrapy' in i) or ('PyCharm' in i) or ('Python' in i) or ('PYTHON' in i):
out['flag'] += out[i]
return out['flag']
# 对数据按人为规则分组,存在误差
for i in ['c', 'java', 'python']:
out[i] = func_cal(i, out.columns)
language_tyepes = out[['c', 'java', 'python']]
print(language_tyepes)
(2) 数据可视化
# 数据可视化
import random
from pyecharts import options as opts
from pyecharts.charts import Bar3D
from pyecharts.faker import Faker
data = [(i, j, language_tyepes.iloc[i,j]) for i in range(6) for j in range(3)]
print(data)
print([[d[1], d[0], d[2]] for d in data])
# print(Faker.clock)
# print(Faker.week_en)
bar = Bar3D()
bar.add(series_name='各语言招聘频数', data=[[d[0], d[1], int(d[2])] for d in data],
xaxis3d_opts=opts.Axis3DOpts(['北京', '北京', '广州', '杭州', '深圳', '郑州'], type_="category"),
yaxis3d_opts=opts.Axis3DOpts(['c', 'java', 'python'], type_="category"),
zaxis3d_opts=opts.Axis3DOpts(type_="value"), )
bar.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=True, pieces=[{"max": 300, 'label': '<300', 'color': '#BBFFFF'},
{"min": 300, "max": 600,
'label': '300-600', 'color': '#8EE5EE'},
{"min": 600, "max": 900,
'label': '600-900', 'color': '#00C5CD'},
{"min": 900, "max": 1200,
'label': '900-1200', 'color': '#FFEC8B'},
{"min": 1200, "max": 1500,
'label': '1200-1500', 'color': '#FF6A6A'},
{"min": 1500, "max": 1800,
'label': '1500-1800', 'color': '#8B1A1A'},
{"min": 1800, "max": 2000,
'label': '1800-2000', 'color': '#8B2323'}
]),
title_opts=opts.TitleOpts(title="各语言城市受欢迎度分布图"),
)
bar.render("各语言城市分布图.html")
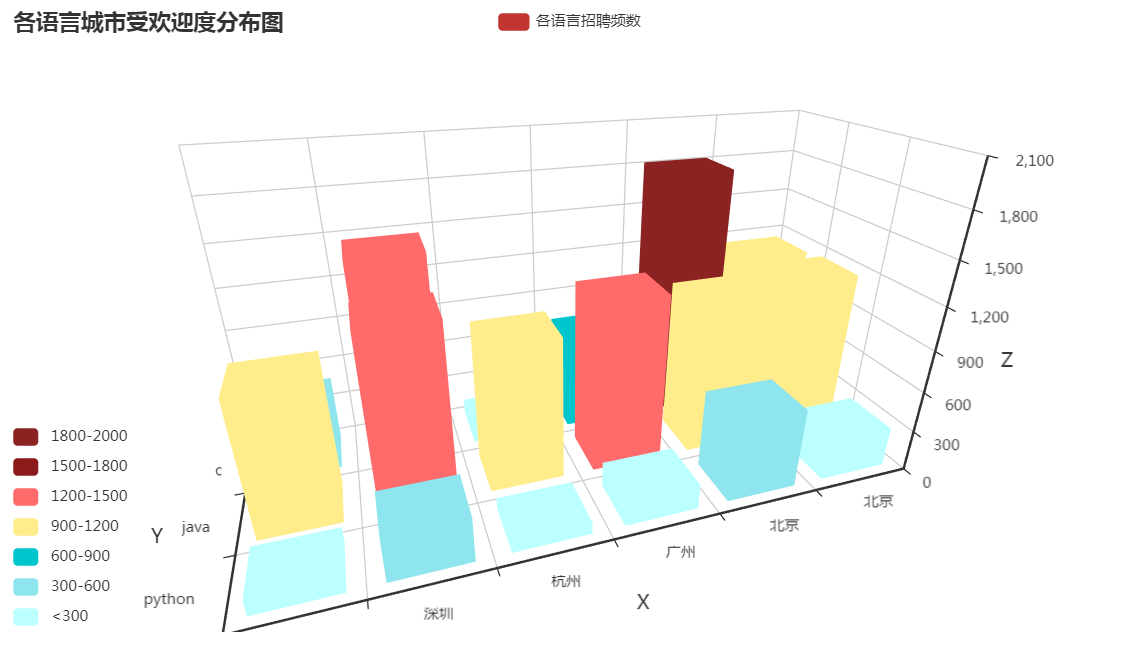
(3) 结论
# 通过图可明显看出,一线城市中,java和c语言编程依然占据主导地位(Python目前任重而道远)















 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









