







目录
1 前言:
CNN在诞生之初主要用于CV领域,但是由于其结构的特殊性,其也可以用于NLP领域的情感分类和关系分类等。
2 特性:
CNN擅长提取局部模式和位置不变模式;那么什么是局部模式,什么又是位置不变模式呢?
2.1 局部模式:
局部模式是指图像中的小区域或局部区域中的特定特征或模式。在计算机视觉中,局部模式可以是CV中的边缘、纹理、角点等,也可以是NLP中的短语、局部的语法结构等。通过提取和分析这些局部模式,我们可以获取关于图像中不同部分的信息。
e.g. 在NLP中CNN提取局部模式的一个步骤就是计算一个句子中所有可能的n元组短语的表示:
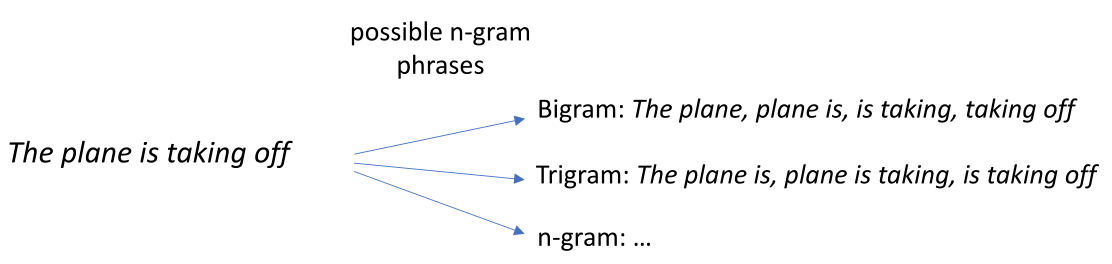
2.2 位置不变模式:
位置不变模式是指无论图像中的特征在哪个位置出现,我们都能够准确地识别和理解这些特征。换句话说,无论特征在图像中的位置如何变化,我们仍然能够正确地识别它们。这种位置不变性对于许多计算机视觉任务非常重要,例如目标识别和图像分类。
那么为何CNN具备以上两种特性呢?其实这主要归功于卷积层和池化层的设计。
3 结构剖析:
3.1 整体框架:
CNN是一种人工神经网络,除了输入层和输出层以外,CNN的结构可以分为3层:
- 卷积层(Convolutional Layer) - 主要作用是提取特征。
- 池化层(Max Pooling Layer) - 主要作用是下采样(downsampling),却不会损坏识别结果。
- 全连接层(Fully Connected Layer) - 主要作用是分类。
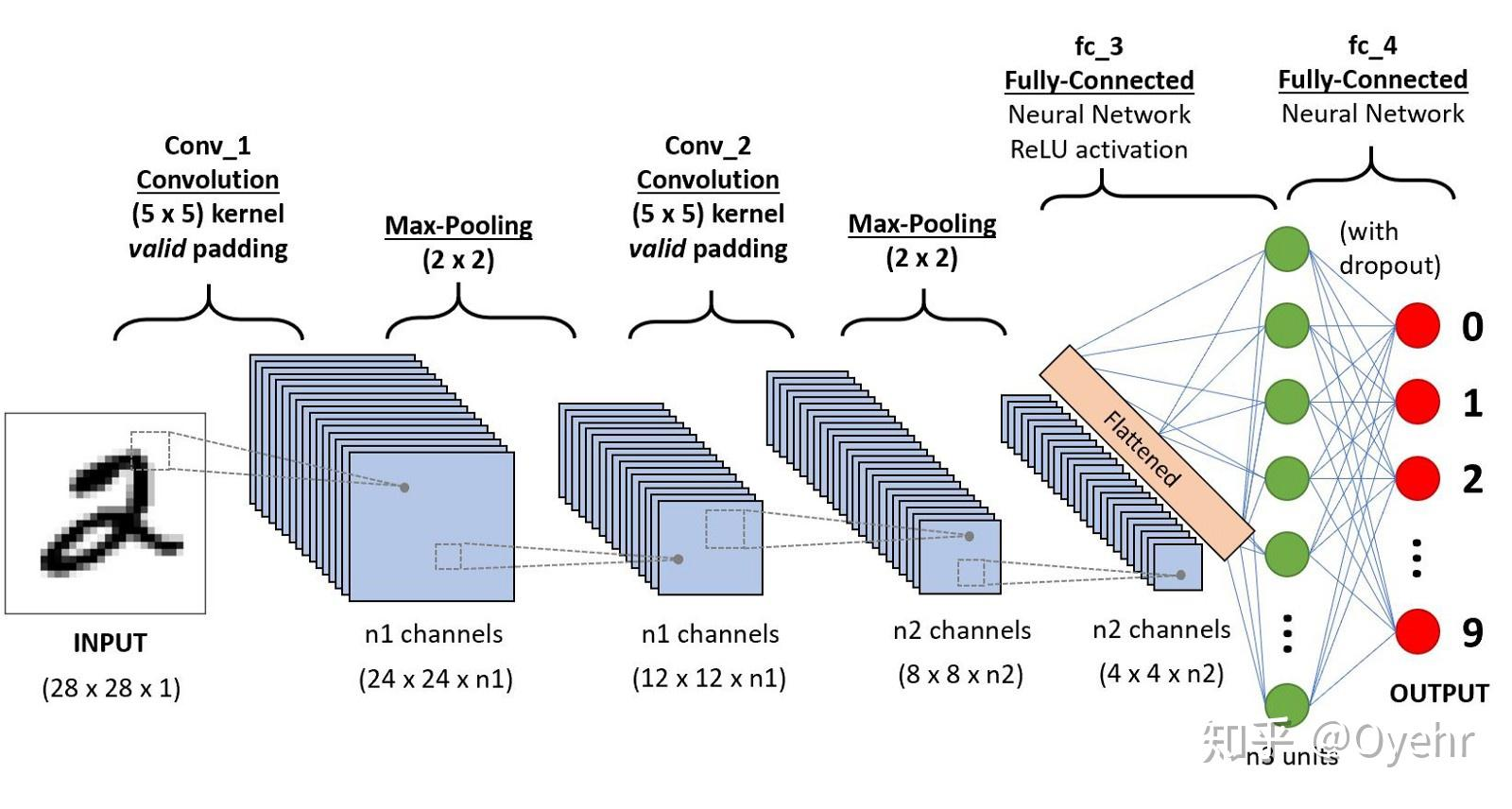
3.2 输入层:
3.2.1 拿cv举例子的话:
首先一张图片在计算机中保存的格式为一个个的像素,比如一张长度为1080,宽度为1024的图片,总共包含了1080 * 1024的像素,如果为RGB图片,因为RGB图片由3种颜色叠加而成,包含3个通道,因此我们需要用1080 * 1024 * 3的数组来表示RGB图片。

3.2.2 拿nlp举例子的话:
如果现在有一句话,那么首先将句子拆分为单个的单词,行数代表句子的长度(单词数),而列数则代表我们选取的词向量的维度,然后我们就可以得到一个句子向量表示矩阵。

3.3 卷积层:
3.3.1 拿nlp举例子的话:
Filter: 滑动卷积核,也可以称为过滤器。
我们先从简单的情况开始考虑,假设我们有一组灰度图片,这样图片就可以表示为一个矩阵,假设我们的图片大小为5 * 5,那么我们就可以得到一个5 * 5的矩阵,接下来,我们用一组过滤器(Filter)来对图片过滤,过滤的过程就是求卷积的过程。假设我们的Filter的大小为3 * 3,我们从图片的左上角开始移动Filter,并且把每次矩阵相乘的结果记录下来。可以通过下面的过程来演示。

每次Filter从矩阵的左上角开始移动,每次移动的步长是1,从左到右,从上到下,依次移动到矩阵末尾之后结束,每次都把Filter和矩阵对应的区域做乘法,得出一个新的矩阵。这其实就是做卷积的过程。而Filer的选择非常关键,Filter决定了过滤方式,通过不同的Filter会得到不同的特征(也就是计算和Filter之间的相似度)。举一个例子就是:
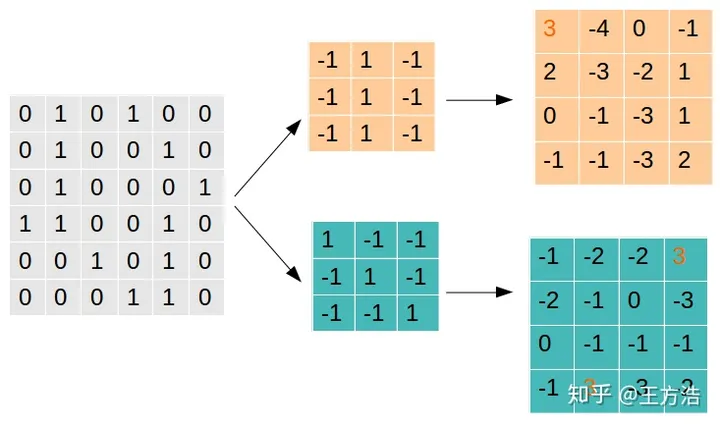
总结:
- 在卷积层中,滤波器的大小通常比输入的局部感受野要小。滤波器通过滑动窗口的方式在整个输入上移动,对每个局部感受野进行卷积操作。每次卷积操作都会生成一个特征图(也称为卷积特征或激活图),其中的每个元素对应于输入的一个位置。
- 卷积操作使用滤波器与局部感受野中的输入进行逐元素相乘,并将结果求和,形成特征图中的一个元素。通过在整个输入上滑动滤波器,可以生成完整的特征图。这样,滤波器可以在每一个输入单元上都被使用,以提取局部特征。
- 通过共享权重的方式,卷积层可以学习到在不同位置上具有相似特征的滤波器。这样,无论特征在图像的哪个位置出现,卷积层都能够捕捉到相应的特征模式,并在特征图中保持相应的响应。
我们选择了2种Filter分别对图中的矩阵做卷积,可以看到值越大的就表示找到的特征越匹配,值越小的就表示找到的特征越偏离。Filter1主要是找到为"|"形状的特征,可以看到找到1处,转换后相乘值为3的网格就表示原始的图案中有"|",而Filter2则表示找到"\"形状的特征,我们可以看到在图中可以找到2处。拿真实的图像举例子,我们经过卷积层的处理之后,得到如下的一些特征结果:

3.3.2 拿nlp举例子的话:
和上述例子一致,本质就是卷积核在输入感受野(输入层的词向量矩阵)上不断滑动,分别进行逐元素相乘求和计算得到不同的特征矩阵。
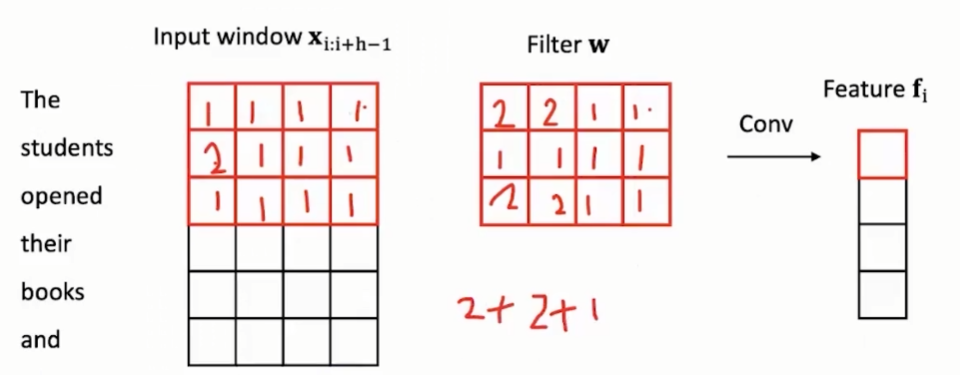
3.4 池化层:
经过卷积层处理的特征是否就可以直接用来分类了呢,答案是不能。我们假设一张图片的大小为m * m,经过p个矩阵维度为n * n的Filter的卷积层之后,得到的结果为(m-n+1) * (m-n+1) * p(画一张图就可以直观感受到),维度非常大,因此我们需要减少数据大小,而不会对识别的结果产生影响,即对卷积层的输出做下采样(downsampling),这时候就引入了池化层。
池化层的原理很简单,先看一个例子:
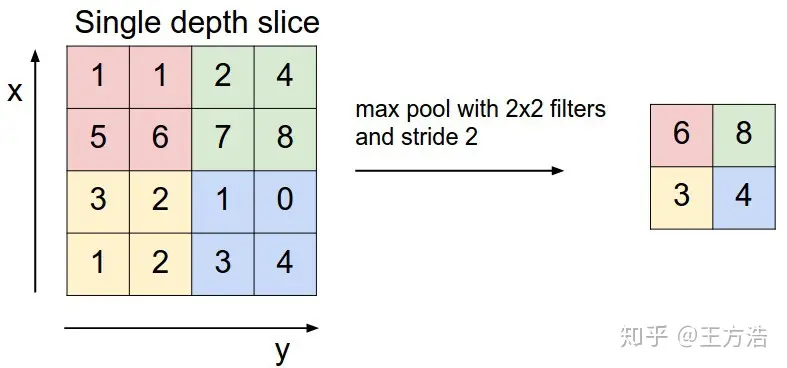
我们先从右边看起,可以看到把一个4 * 4的矩阵按照2 * 2做切分,每个2 * 2的矩阵里,我们取最大的值保存下来,红色的矩阵里面最大值为6,所以输出为6,绿色的矩阵最大值为8,输出为8,黄色的为3,蓝色的为4,。这样我们就把原来4 * 4的矩阵变为了一个2 * 2的矩阵。在看左边,我们发现原来224 * 224的矩阵,缩小为112 * 112了,减少了一半大小。
那么为什么这样做可行呢?丢失的一部分数据会不会对结果有影响,实际上,池化层不会对数据丢失产生影响,因为我们每次保留的输出都是局部最显著的一个输出,而池化之后,最显著的特征并没有没丢弃。我们只保留了认为最显著的特征,而把其他无用的信息丢掉,来减少运算。池化层的引入还保证了平移不变性,即同样的图像经过翻转变形之后,通过池化层,可以得到相似的结果。
既然是降采样,那么是否有其他方法实现降采样,也能达到同样的效果呢?当然有,通过其它的降采样方式,我们同样可以得到和池化层相同的结果,因此就可以拿这种方式替换掉池化层,可以起到相同的效果。
通常卷积层和池化层会重复多次形成具有多个隐藏层的网络,俗称深度神经网络。正如本篇文章最开始的图一所示。
3.5 上采样与下采样:
那么什么叫做下采样呢?它和上采样之间又有什么联系呢?
3.5.1 目的:
简单来讲下采样就是缩小图片尺寸(减小矩阵维度),而上采样就是增大图片尺寸(增大矩阵维度)。
- 前者的目的是①使得图像符合显示区域的大小;②生成对应图像的缩略图。
- 而后者的目的则是放大原图像,从而可以显示在更高分辨率的显示设备上。
3.5.2 实现的方法:
- 可以通过可学习卷积层和池化层两种方式实现下采样,这里我们仅介绍后者。池化层下采样是为了降低特征的维度。如Max-pooling和Average-pooling,目前通常使用Max-pooling,因为它计算简单而且能够更好的保留纹理特征。
- 而上采样常用的方式包括①插值②反卷积层③反池化层。(这里我们了解即可)
- 想要深入了解们可以查看上采样、下采样到底是什么?_ZhiBing_Ding的博客-CSDN博客
3.6 全连接层:
3.6.1 含义:
我们知道卷积和池化操作,提取的特征是局部特征。也就是说,卷积和池化是“不识庐山真面目,只缘身在此山中”。而全连接层呢?它的每次完成的是所有方向的连接(实现局部特征的融合),它看到的是全局特征。全连接是“不畏浮云遮望眼,自缘身在最高层”。
通俗来讲就是:
假设你是一只蚂蚁,你的任务是找小面包。这时候你的视野比较窄,只能看到很小一片区域,也就只能看到一个大面包的部分。
当你找到一片面包之后,你根本不知道你找到的是不是全部的面包,所以你们所有的蚂蚁开了个会,互相把自己找到的面包的信息分享出来,通过开会分享,最终你们确认,哦,你们找到了一个大面包。
3.6.2 一个具体的例子:
例如经过卷积池化后得到3x3x5的输出。那它是怎么样把3x3x5的输出,转换成1x4096的形式呢?
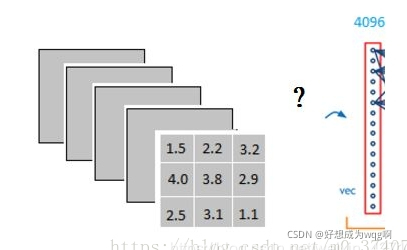
很简单,可以理解为在最后又做了一个卷积:
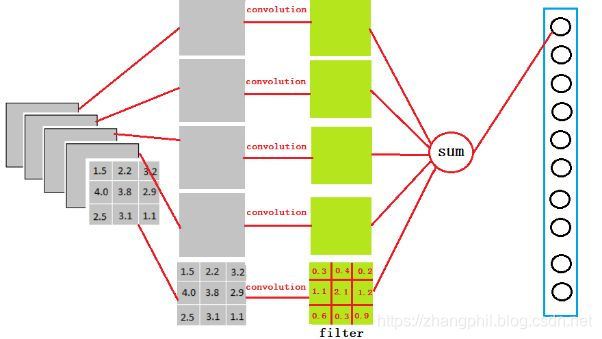
但是这次的卷积核尺寸是3X3X5(filter,或者称之为滤波器),即全连接层特意设计了和feature map中大小尺寸相同的卷积核。此处卷积不像CNN之前卷积和下采样过程会产生深度矩阵feature map。这一次每一次卷积只会产生一个值(因为卷积核和feature map大小尺寸相同)。在把3X3X5的卷积输出转成全连接层中4096神经元中之一的过程中,通过filter的激活函数,对5张3X3特征图中的每一张进行卷积,然后再把这5张feature map卷积结果求和,和就是4096个神经元中之一。我们实际就是用4096个3x3x5的卷积层去卷积激活函数的输出。
这一步卷积一个非常重要的作用,就是把分布式特征representation映射到样本标记空间(通俗来讲就是它把特征representation整合到一起,输出为一个值)这样做,有一个什么好处?可以大大减少特征位置对分类带来的影响。
比如下面这个例子:
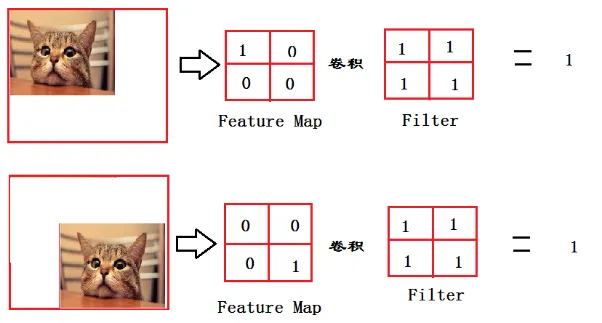
猫在哪我不管,我只要猫,于是我让filter去把这个猫找到,实际就是把feature map 整合成一个值,这个值大,哦,有猫。这个值小,那就可能没猫,和这个猫在哪关系不大,鲁棒性大大增强了。
全连接层在实际的运用中往往是两层,是因为只有一层全连接层,有些情况下解决不了非线性问题,如果两层,效果就好多了。如泰勒展开拟合光滑曲线一样。如下图所示:
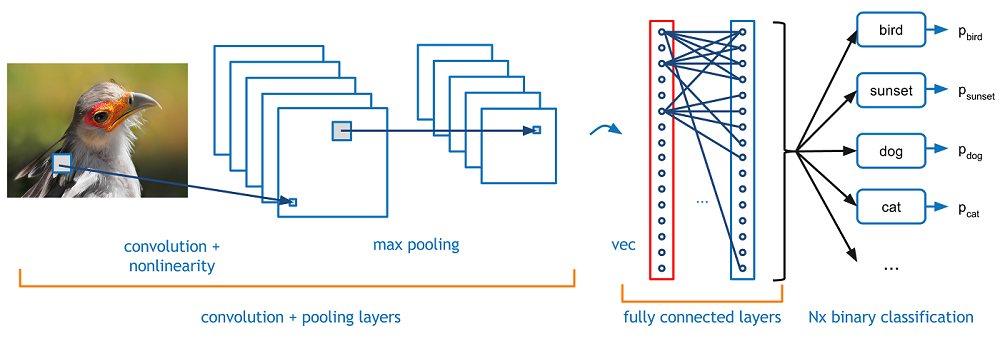
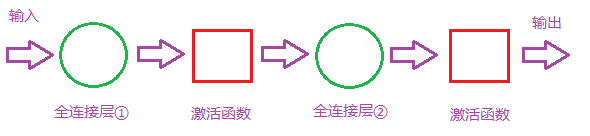
当然我们最终的目标是实现分类(如上图所示),这就要介绍激活函数和输出层。
3.7 激活函数与输出层:
-
激活函数:全连接层通常在计算加权和后应用激活函数,以引入非线性特性。常用的激活函数包括ReLU(修正线性单元)、sigmoid和tanh等。激活函数可以增加模型的表达能力,并帮助网络学习复杂的非线性关系。
-
输出层:全连接层的最后一层是输出层,用于分类任务。输出层通常是一个具有相应类别数目的神经元组成的层(例如假设你的输出层有两个神经元,分别表示猫和狗的类别。)。每个神经元对应一个类别,并输出该类别的概率或得分。常用的激活函数是softmax函数,它将神经元的输出转化为表示概率分布的值。
4 CNN的用途:
- 图像分类(yolo系列);
- 视频分类、文本分类;
- 语音识别。
5 RNN和CNN的区别:
| CNN | RNN | |
|---|---|---|
| 优点 | 擅长提取局部和位置不变特征 | 擅长处理变长文本 |
| 参数量 | 少 | 多 |
| 运算方式 | 并行(卷积核之间没有相互依赖) | 串行(对之前的数据有较大依赖) |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









