




目录
1 Tokenizer简介:
传统的数据预处理方法主要包含以下步骤。

Tokenizer的出现将这些步骤都封装起来,我们可以直接使用Tokenizer,而不需要再四处调包。
2 Tokenizer基本使用:

2.1 处理单条数据:
1)不同的模型对应不同的Tokenizer,因此我们在导入的时候统一使用AutoTokenizer
from transformers import AutoTokenizer
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
tokenizer
2)可以看到此时的tokenizer已经是BertTokenizerFast了。

3)句子分词
sen = "弱小的我也有大梦想!"
tokens = tokenizer.tokenize(sen)
tokens
分词结果如下:['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']
4)查看词典

可以看到有些是一个词,有些带一些###,这些在英文上是表示子词,可以缩小词表(比如playing、swimming可以拆分为play、swim、ing)
5)查看词典大小
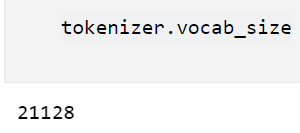
6)索引转换,将词序列转换为ID序列
# 将词序列转换为id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
ids
[2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106]
7)当然也可以逆着转
# 将id序列转换为token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
tokens
['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']
# 将token序列转换为string
str_sen = tokenizer.convert_tokens_to_string(tokens)
str_sen
'弱 小 的 我 也 有 大 梦 想!'
8)更便捷的方式(分词与索引转换相结合,encode)
# 将字符串转换为id序列,又称之为编码
ids = tokenizer.encode(sen, add_special_tokens=True)
ids
[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102]这里和之前的可能不太一样,是因为Bert分词器会将句子加上开始和结束的标志,101和102.
如果我们改为False就和之前一致了
9)当然我们也可以使用decode解码
# 将id序列转换为字符串,又称之为解码
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
str_sen
'[CLS] 弱 小 的 我 也 有 大 梦 想! [SEP]'
10)填充与截断(就是加入一个max_length参数,使用padding填充)
# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
ids
[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)
ids
[101, 2483, 2207, 4638, 102]
我们填充之后,怎么确定哪个句子是第一,哪个是第二呢?还有就是一个句子中填充的部分哪些是有效的呢?
其实这是由attention_mask和token_type_ids表示:
11)手动写
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
ids
[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
attention_mask = [1 if idx != 0 else 0 for idx in ids]#标记一个被填充的句子中的有效成分
token_type_ids = [0] * len(ids)#标记句子是第一个还是第二个
ids, attention_mask, token_type_ids
([101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
12)调用encode_plus
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15)
inputs
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}
inputs = tokenizer(sen, padding="max_length", max_length=15)
inputs
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}
2.2 处理Batch数据:
1)和之前一样的方法
sens = ["弱小的我也有大梦想",
"有梦想谁都了不起",
"追逐梦想的心,比梦想本身,更可贵"]
res = tokenizer(sens)
res
{'input_ids': [[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 102], [101, 3300, 3457, 2682, 6443, 6963, 749, 679, 6629, 102], [101, 6841, 6852, 3457, 2682, 4638, 2552, 8024, 3683, 3457, 2682, 3315, 6716, 8024, 3291, 1377, 6586, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
2)分条处理和一个Batch处理-时间上的差异:
可以发现一个Batch处理,时间开销更小,所以如果我们不需要对每条数据进行不同的操作的话,那么一个batch处理还是很不错的。


3 Fast / Slow Tokenizer
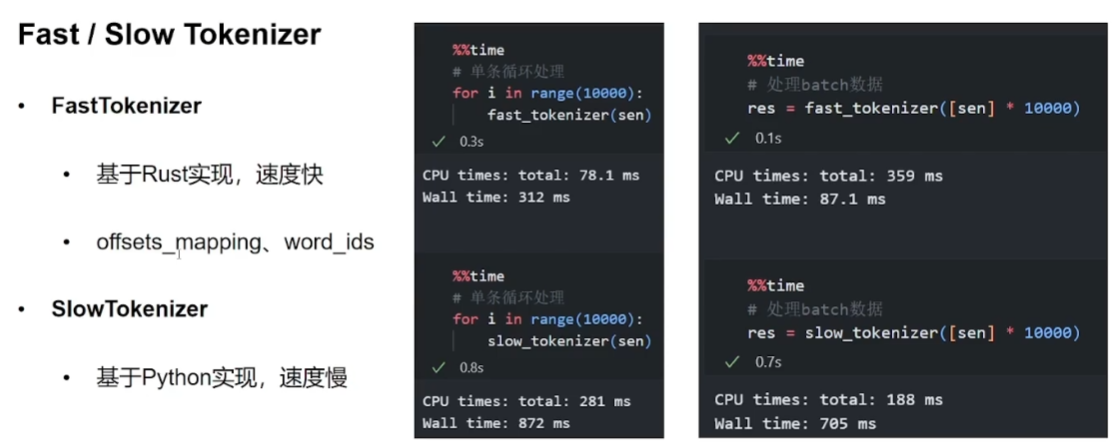
前者是使用Rust实现,速度快,且有一些额外的返回值;后者采用纯python实现,速度较慢。

是需要指定use_fast=false就可以得到slow tokenizer
3.1 直观的时间对比:
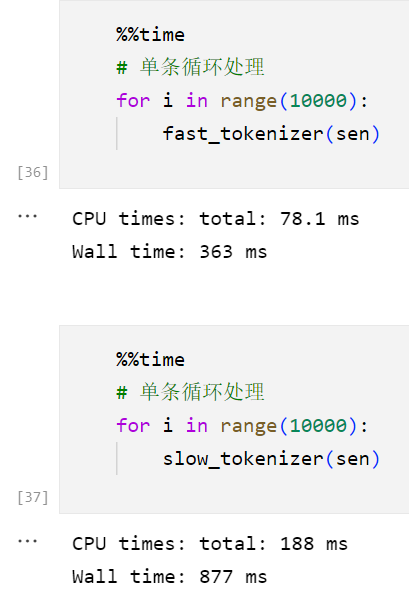
在Batch上的差异更大:
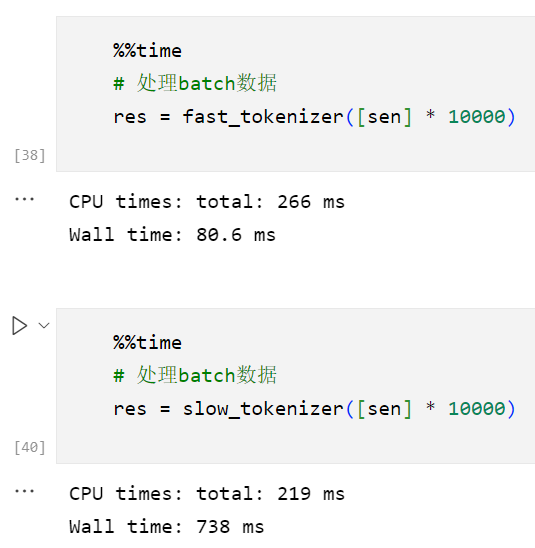
3.2 额外的返回值:
fast分词器专有功能:
sen = "弱小的我也有大Dreaming!"
inputs = fast_tokenizer(sen, return_offsets_mapping=True)inputs
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 10252, 8221, 106, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 12), (12, 15), (15, 16), (0, 0)]}
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
-
offset_mapping是一个表示每个输入 token 在原始文本中的起始和结束位置的列表。对于每个 token,offset_mapping返回一个元组(start, end),其中start是 token 在原始文本中的起始位置,end是 token 在原始文本中的结束位置。这个返回值可以用于将模型的输出与原始文本对齐。 -
word_ids是指在一些特定的 tokenizer 实现中,返回的表示输入文本中每个单词(word)的标识符的列表。这个返回值提供了一种以单词为单位而不是以标记(token)为单位进行处理的方式。例如dreaming就是识别为了7 7,拆分为dream和ing。其实这个就是告诉你哪部分是一个token,哪部分是一个词。
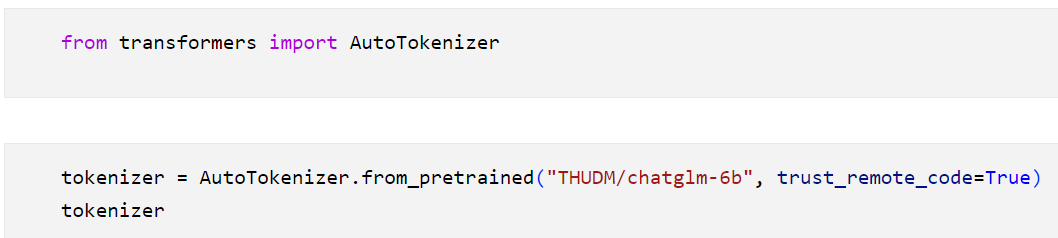
4 特殊的分词器的加载:
有些模型有自己的分词器,我们在使用的时候要加上trust_remote_code=True

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









