







本笔记仅记录《统计学习方法》中各个章节算法|模型的简要概述,比较泛泛而谈,用于应对夏令营面试可能会问的一些问题,不记录证明过程和详细的算法流程。大佬可自行绕路。
更多章节内容请参阅:李航《统计学习方法》学习笔记-CSDN博客
目录
逻辑斯谛回归:
逻辑斯谛回归是统计学习中的经典分类方法。可以简称为逻辑回归,“逻辑”是音译“逻辑斯谛(logistic)”的缩写,逻辑回归属于对数线性模型。
逻辑斯谛分布:
若X服从逻辑斯谛分布,那么它满足如下分布函数和密度函数:

二项逻辑斯谛回归模型:

由上述公式可以看出,对于Y=1而言,线性函数的值越接近正无穷,概率值越接近于1;越接近负无穷,概率值就越接近0。
模型参数估计:
我们常常用概率(Probability) 来描述一个事件发生的可能性。
而似然性(Likelihood) 正好反过来,意思是一个事件实际已经发生了,反推在什么参数条件下,这个事件发生的概率最大。
用数学公式来表达上述意思,就是:

需要注意的是在逻辑回归中,我们的损失函数不能使用像线性回归中的平方误差,因为逻辑回归也采用平方误差的话得到的函数并非凸函数,不易优化,容易陷入局部最小值,所以逻辑函数用的是别的形式的函数作为损失函数,叫对数损失函数(log loss function)

接下来只需要对L(w)求极大值,就可以得到w的估计值。
这样,问题就变成了以对数似然函数为目标函数的最优化问题。逻辑回归学习中通常采用的方法是梯度下降法及拟牛顿法。
多项逻辑斯谛回归:
只需要在二项的基础上拓展即可:
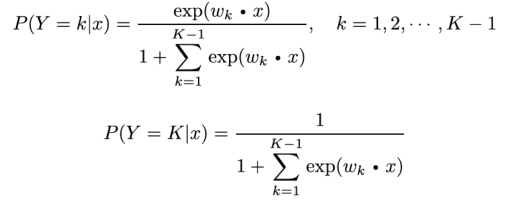
最大熵模型:
最大熵原理:
最大熵原理认为,学习概率模型时,在所有可能的概率模型中(有约束条件),熵最大的模型是最好的模型。
假设离散随机变量X的概率分布是P(X),那么其熵为:

一般来讲,当X服从均匀分布时,熵最大。
最大熵模型的定义:
将最大熵原理应用到分类得到最大熵模型。

最大熵模型的学习:
最大熵模型的学习过程就是求解最大熵模型的过程,可以形式化为约束最优化问题。

求解上述约束最优化问题所得出的解,就是最大熵模型学习的解。
最大熵模型的求解通常先将约束最优化的问题转换成无约束最优化的对偶问题。通过引入拉格朗日乘子将原问题转换为对偶问题。
例子:





模型学习的最优化算法:
逻辑回归模型、最大熵模型学习都可以归结为以似然函数为目标函数的最优化问题。通常采用的优化方法包括改进的迭代尺度法、梯度下降法、牛顿法或拟牛顿法等。
改进的迭代尺度法(IIS):


拟牛顿法(BFGS):


















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









