







目录
1 What’s Hallucination in MLLMs (什么是MLLMs中的幻觉)
2 Causes of Hallucinations in MLLMs (幻觉的原因)
2.2 Lack of Data Diversity (数据多样性不足)
2.3 Hallucinations from Vision Model (来自视觉模型的幻觉)
2.4 Hallucinations from Language Model (来自语言模型的幻觉)
3 Multimodal Hallucination Metrics and Benchmarks (多模态幻觉的评估标准和基准)
4 Multimodal Hallucination Mitigation (多模态幻觉的缓解方法)
4.1 Introduce Negative Data (引入负面数据)
4.2 Address Noises and Errors (解决噪声和错误)
4.4 Post-hoc Correction (事后修正)
0 完整Tutorial内容
本文为"⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程"——第五部分的学习笔记,完整内容参见:
⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程-CSDN博客


1 What’s Hallucination in MLLMs (什么是MLLMs中的幻觉)
1.1 什么是MLLM中的幻觉?
在多模态大型语言模型(MLLMs)中,幻觉指的是模型生成的输出与实际内容不一致的现象。例如,当模型生成的答案与视觉输入相矛盾时,便会出现幻觉。例如,给定一张显示男孩正在打网球的图片,问题是关于在地面上靠近黄色网球的地方定位水瓶。尽管图像中没有水瓶,像GPT-4等模型(V1,V2,LA 1.0)仍然可能生成幻觉答案,声称图像中有水瓶。

1.2 MLLM中的幻觉类型
一般来说,MLLM中的幻觉可以分为三种类型:
- 物体幻觉:指生成了不存在的物体或错误的类别。例如,模型可能描述图像中的物体为一束花,但图像中并没有这样的花,从而产生了物体幻觉。
- 属性幻觉:涉及对颜色、形状、材质、内容甚至计数的错误描述。例如,模型可能会说花是粉色的,但实际花的颜色并不是粉色,这就会产生属性幻觉。
- 关系幻觉:指错误的人物与物体之间的互动或相对位置。例如,模型可能会说图像中的人们站在女孩周围,但实际上并非如此,这会导致关系幻觉。

2 Causes of Hallucinations in MLLMs (幻觉的原因)
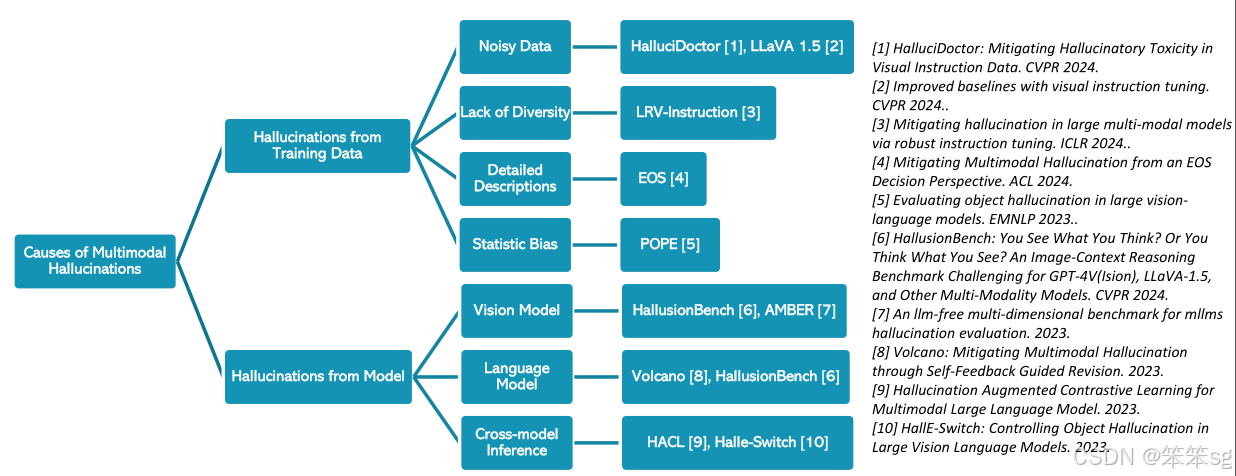
2.1 Noisy Data (噪声数据)
训练数据中可能包含不准确或错误的信息,这些数据被用来训练多模态语言模型时,可能导致幻觉。例如,某些从网上收集的图像-文本配对数据可能包含错误的信息。举个例子,在预训练阶段,数据中可能会描述“图像中有8个人在等待修剪”,但实际上图像中并没有这些人。这种噪声数据会导致模型生成错误的答案,进而产生幻觉。

2.2 Lack of Data Diversity (数据多样性不足)
训练数据集可能缺乏足够的多样性,特别是在指令跟随任务中,许多数据集只包含正面指令,而缺乏负面指令。例如,模型可能只被训练来回答“是”或者“不是”类型的问题,但在实际应用中,模型需要能够处理更多样化的指令。如果数据集只包含正面指令,模型可能会偏向于输出“是”的回答,而忽略拒绝或者否定的可能性,从而影响模型的生成质量。

2.3 Hallucinations from Vision Model (来自视觉模型的幻觉)
视觉模型的能力不足可能导致幻觉的产生。视觉编码器如果不够强大,可能无法准确理解图像内容,导致生成错误的答案。例如,当问题询问图像中的费用总和时,视觉模型可能无法清晰地从图像中提取出正确的数字,因此给出错误的答案。举个例子,当模型需要从图像中读取数据时,如果视觉模型无法清楚地看到图像中的内容,它可能会误解图像并给出错误的答案。

2.4 Hallucinations from Language Model (来自语言模型的幻觉)
语言模型的能力通常比视觉模型强大,因此模型可能更多依赖于语言模型的记忆而不是图像信息,从而产生幻觉。例如,当问题要求基于图表提供信息时,模型可能会根据先前的记忆生成答案,而不是基于当前图像的内容。举个例子,在2008年北京奥运会金牌数的问题中,即使图像中的信息已经修改,模型仍然基于其语言模型的记忆错误地回答“中国金牌最多”,而没有正确分析图像中的新数据。

3 Multimodal Hallucination Metrics and Benchmarks (多模态幻觉的评估标准和基准)
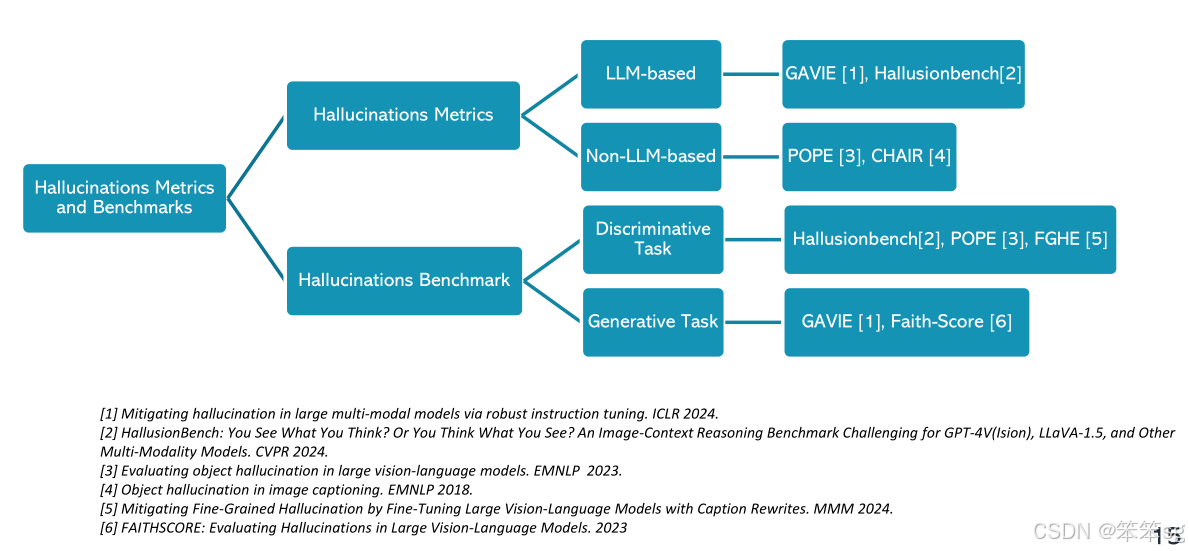
3.1 评估幻觉的两大类方法
幻觉的评估可以分为两大类:
基于语言模型(LLM)的评估:这类方法侧重于生成式任务,模型需要根据开放性问题给出答案。
基于非语言模型的评估:这类方法侧重于判别式任务,模型只需回答“是”或“不是”这样简短的回答。
3.2 评估任务

幻觉评估任务也分为两类:
生成任务(Generative Task):这是一个开放性问题,模型可以生成答案而不仅仅是“是”或“不是”。
判别任务(Discriminative Task):这是一个分类任务,模型需要通过“是”或“不是”来回答问题,判定图像中是否存在某物。例如,问题可能是:“图像中是否有水瓶?”模型根据问题回答“是”或“不是”。
3.3 评估标准
相关性分数(Relevance Score):这个标准用于评估模型生成的答案是否与问题相关,是否回答了问题。
准确性(Accuracy Score):该标准用于评估模型生成的答案是否与图像内容一致,即模型是否准确地理解了图像内容。
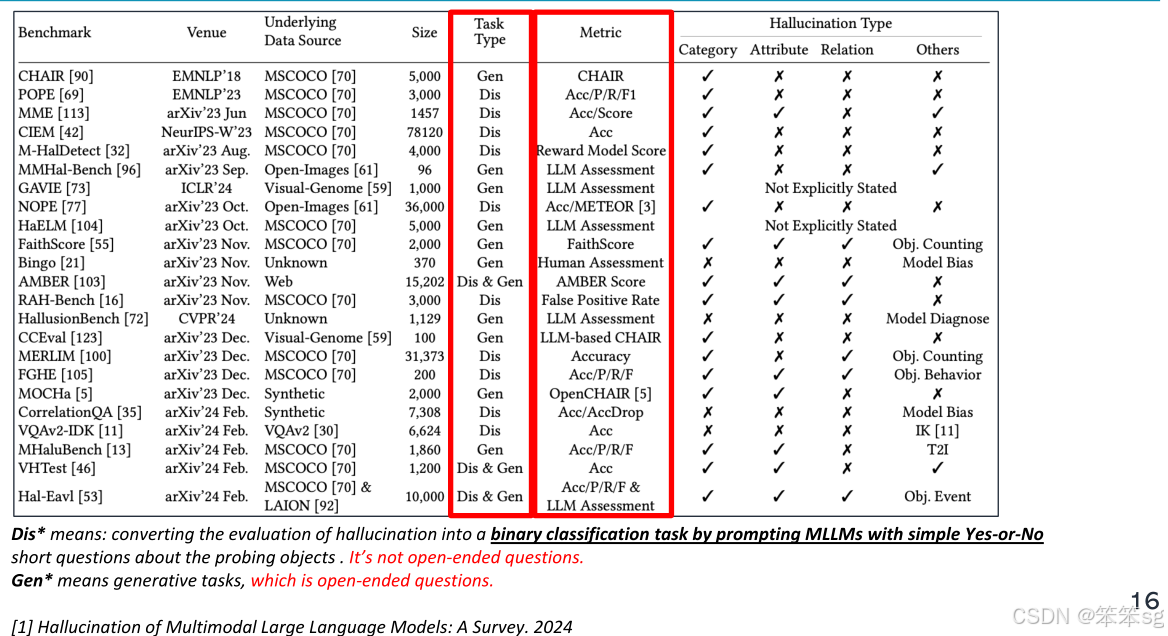
3.4 基准数据集问题
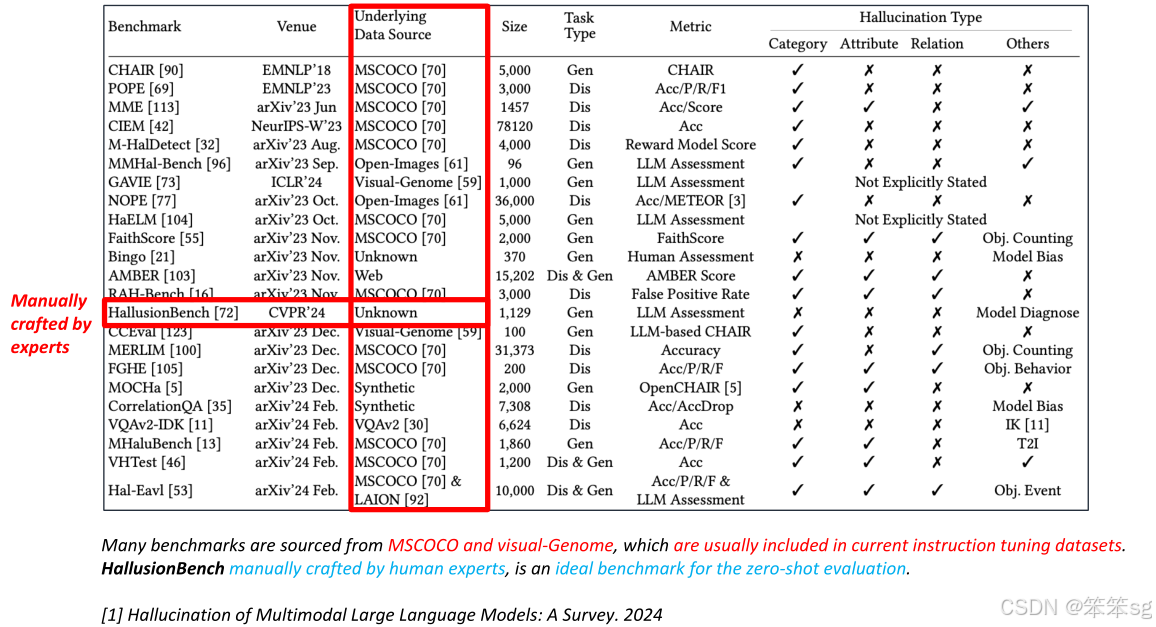
当前多模态大型语言模型的评估基准大多来源于如MSCOCO等数据集。然而,这些数据集在训练过程中有时没有包括图像信息,这可能导致评估不公平。具体来说,有些模型在训练时可能包含了更多的图像数据,而其他模型则没有,这使得它们的对比不公平。
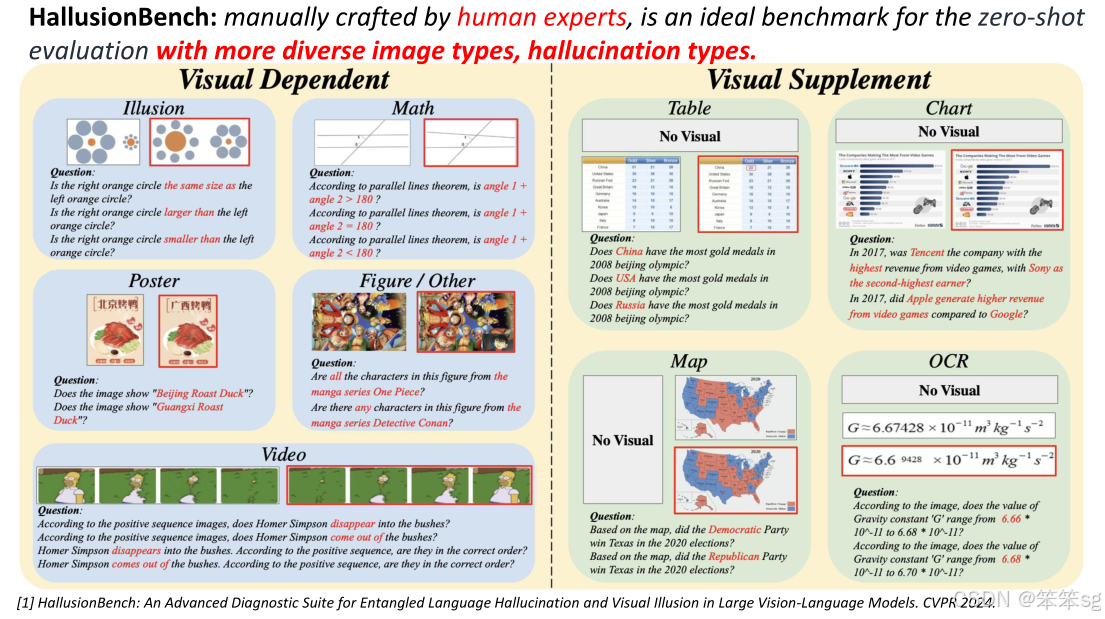
3.5 基于人类专家的评估基准
为了更加公平和全面地评估多模态语言模型的幻觉,建议构建由人类专家设计的基准。这些基准包含更多样化的图像标签,涵盖海报、图表、视频、地图等内容。每个图像配有多个问题,且每个问题只会在一个或两个词上有所变化。如果模型能够正确回答所有问题,则视为模型成功预测。
3.6 具体示例
判别任务的例子:比如,“图像中是否有水瓶?”这是一个基于“是”或“不是”的问题,模型需要通过判断图像中的内容来做出回答。
生成任务的例子:比如,“你能帮我找到带有字母B的狗吗?”这是一个开放性问题,模型需要生成完整的答案,而不仅仅是回答“是”或“不是”。
4 Multimodal Hallucination Mitigation (多模态幻觉的缓解方法)
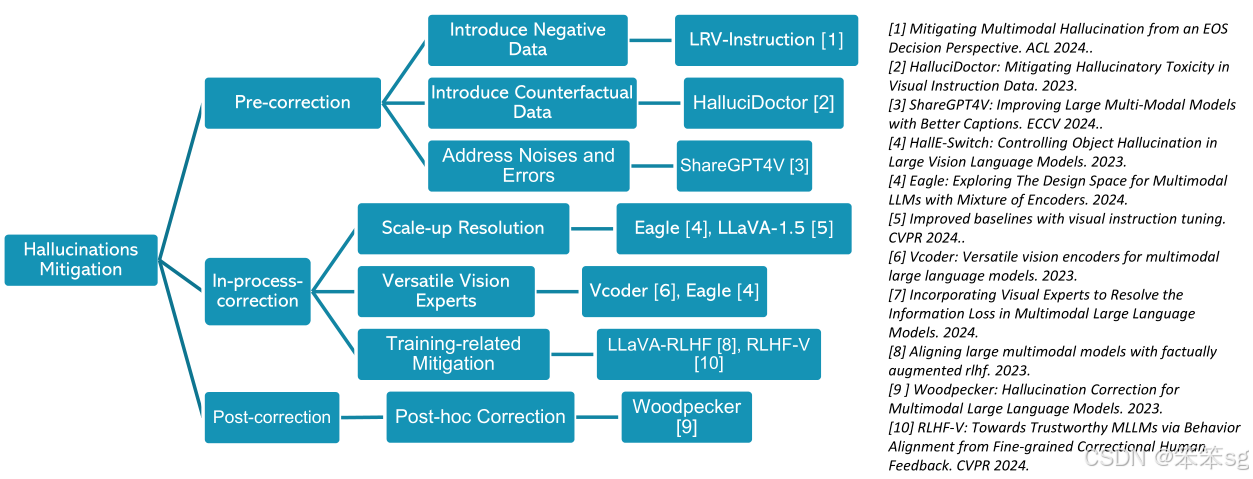
4.1 Introduce Negative Data (引入负面数据)
该方法通过在训练数据中加入负面样本来增加模型的鲁棒性。负面数据包括与正面数据相对的示例,例如“非存在物体操作”或“错误操作”。这样可以帮助模型更好地理解何时不能执行某个任务。例如,在任务中,如果问题涉及对象检测(例如“图像中是否有某个物体”),正面样本可能包含正常的物体识别任务,而负面样本则可以包含无物体或错误的操作任务。通过这种方式,模型在处理幻觉问题时能够避免生成不符合事实的答案。

4.2 Address Noises and Errors (解决噪声和错误)
该方法关注如何通过减少训练数据中的噪声和错误来减轻幻觉问题。例如,使用生成式模型(如GPT-4)来生成更准确的图像描述,从而减少噪声。例如,MS COCO数据集中,人工生成的简短图像描述常常缺乏足够的信息,可能导致模型产生错误的推理。通过使用更精确的图像描述和与视觉内容更为一致的训练数据,可以减少模型的幻觉。作者提到通过精心设计的生成任务(如GPT-4生成的高质量图像描述),模型能够生成更准确的答案,从而降低幻觉的风险。

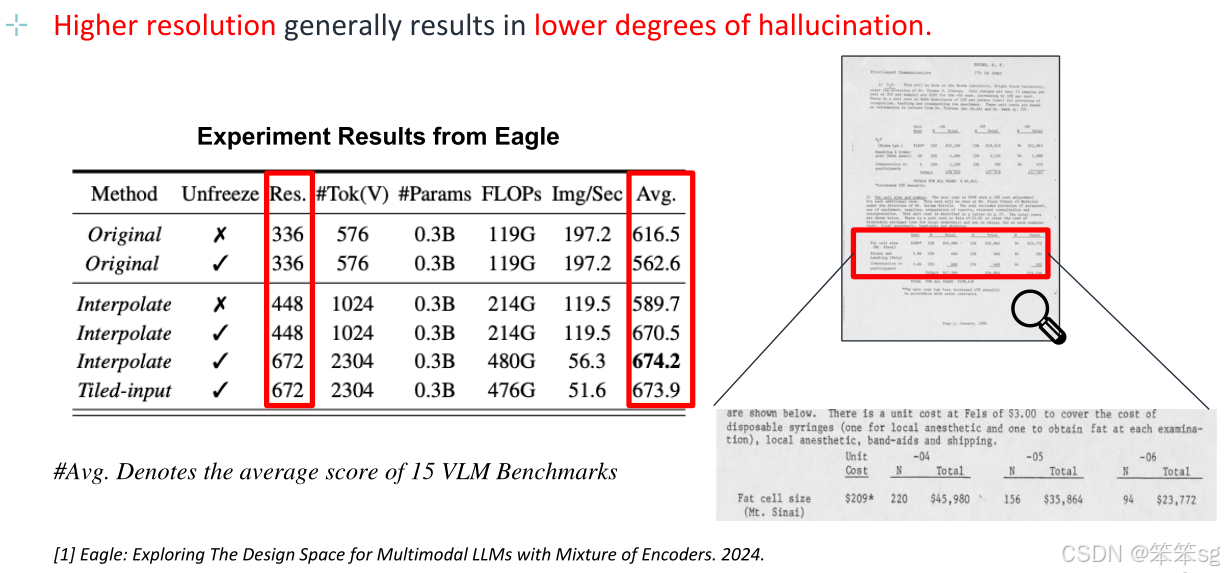
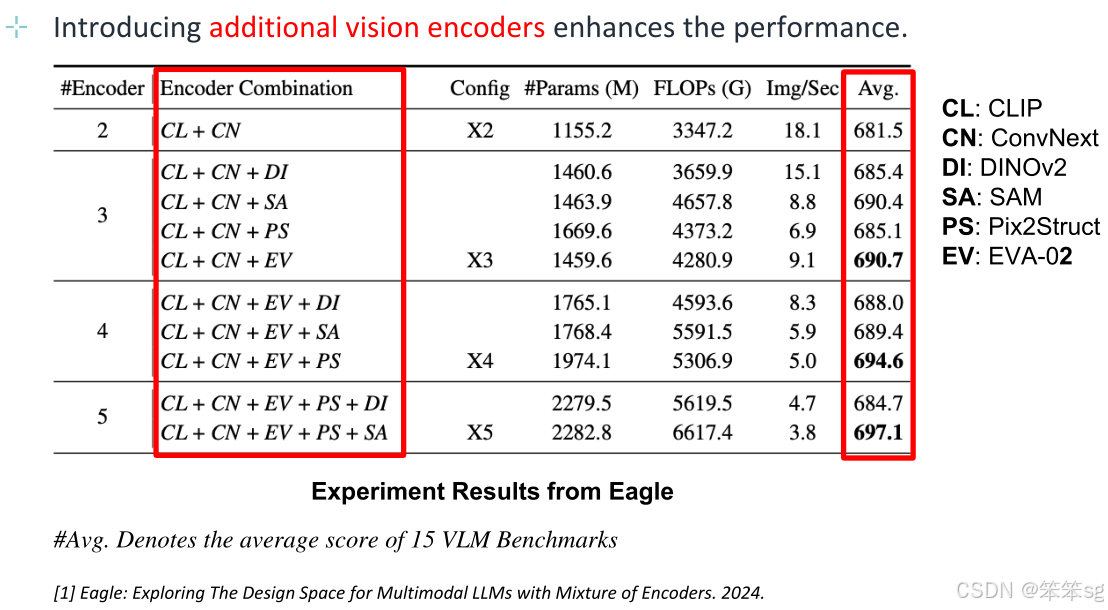
4.3 Training-related Mitigation-RLHF (训练相关的缓解方法-RLHF)
强化学习与人类反馈(RLHF)是一种训练方法,可以通过不断优化模型的偏好来减少幻觉。在此方法中,模型的输出会根据人类反馈进行调整,从而逐步改进模型的表现。例如,模型可以根据人类的反馈优化回答的准确性和相关性,通过这种训练策略,模型会逐渐学会避免错误的推理和幻觉生成,提供更精确的答案。
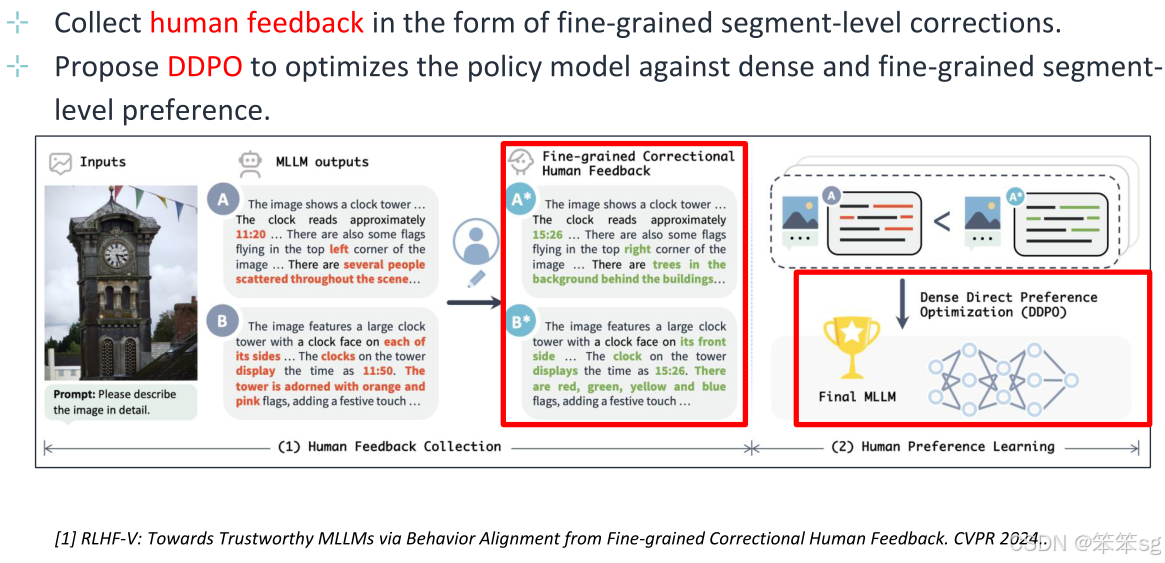
4.4 Post-hoc Correction (事后修正)
该方法在模型生成答案之后进行后处理,修正模型的错误或不准确的部分。具体来说,当模型生成答案后,可以根据一些关键字和概念来检查答案的准确性。然后,模型可以重新评估这些生成的答案,检测其中的幻觉部分并进行修正。例如,如果模型生成的答案包含错误信息(如提到图像中有某个人,但图像实际上没有人),通过后处理,模型可以识别并纠正这些错误。通过这种方式,模型的答案会更加准确。
例如,作者提到在一个具体的例子中,模型最初的答案提到图像中有一个人,而后通过后处理,模型识别到图像中并没有人,最终修正了答案。

5 解决MLLM幻觉未来的方向

-
建立更标准的基准测试:目前的评估方法多局限于“是”或“否”的简单判断,模型的回答可能无法准确反映实际情况。作者提出,未来应建立更标准化、易于使用的基准测试,能够支持更自由的问答,避免过于简单的“是/否”回答,这样能提高模型的准确性。
-
发展低成本的评估模型:现有的评估方法如GPT-4等通常需要支付费用,作者建议如何开发更便宜、有效的评估模型,从而降低成本。
-
将幻觉视为一种特性:作者指出,幻觉可能不仅仅是错误的答案,也可以被视为模型的“想象力”。如果能够更好地控制模型生成的“幻觉”,也许能够发挥其创造性,使得模型能够更精准地结合图像信息并生成更富有创意的回答。例如,幻觉的部分可以被视为模型对于数据的想象,这样可以帮助模型更好地进行创新,生成更具创意的内容。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









