



目录

1 前言
PaddleOCR是由百度飞桨(PaddlePaddle)开源的OCR工具库,支持多语言文本检测、识别和版面分析。其特点包括:
-
提供轻量级中英文OCR模型(支持80+语言)
-
支持文本检测(DB、EAST等算法)与识别(CRNN、SVTR等算法)解耦使用
-
推理速度快,部署灵活(支持Python/C++/移动端)
PaddleOCR 的核心功能是从图像中提取文本信息,因此它在多模态任务中可以作为 文本信息提取模块。
一般情况下,在多模态任务中,我们只需要基于PaddleOCR已有的预训练模型对图像进行文本提取即可,不需要手动训练模型。因此本文仅涉及基于PaddleOCR进行推理,不包含模型训练,如果你对这个有需求,可以浏览PaddleOCR 文档。
Github链接:PaddlePaddle/PaddleOCR
官方使用文档:概述 - PaddleOCR 文档
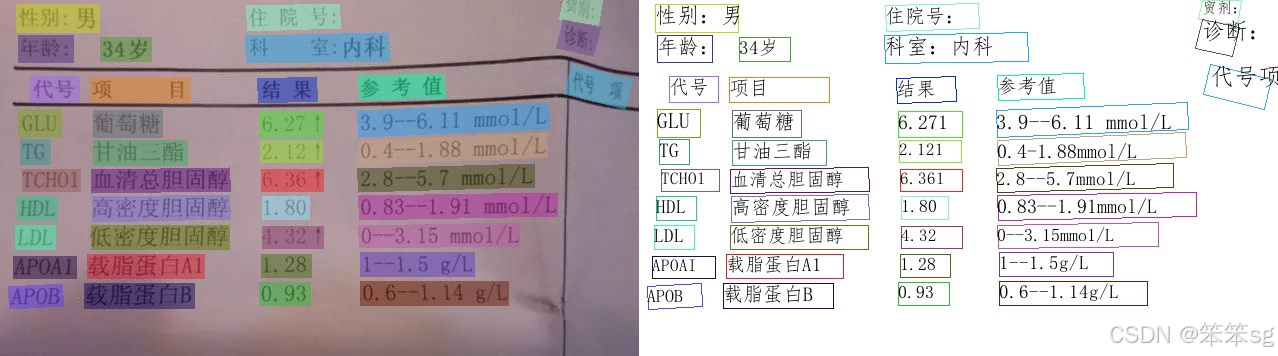
2 效果展示


3 在线体验
超轻量PP-OCR mobile模型体验地址:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
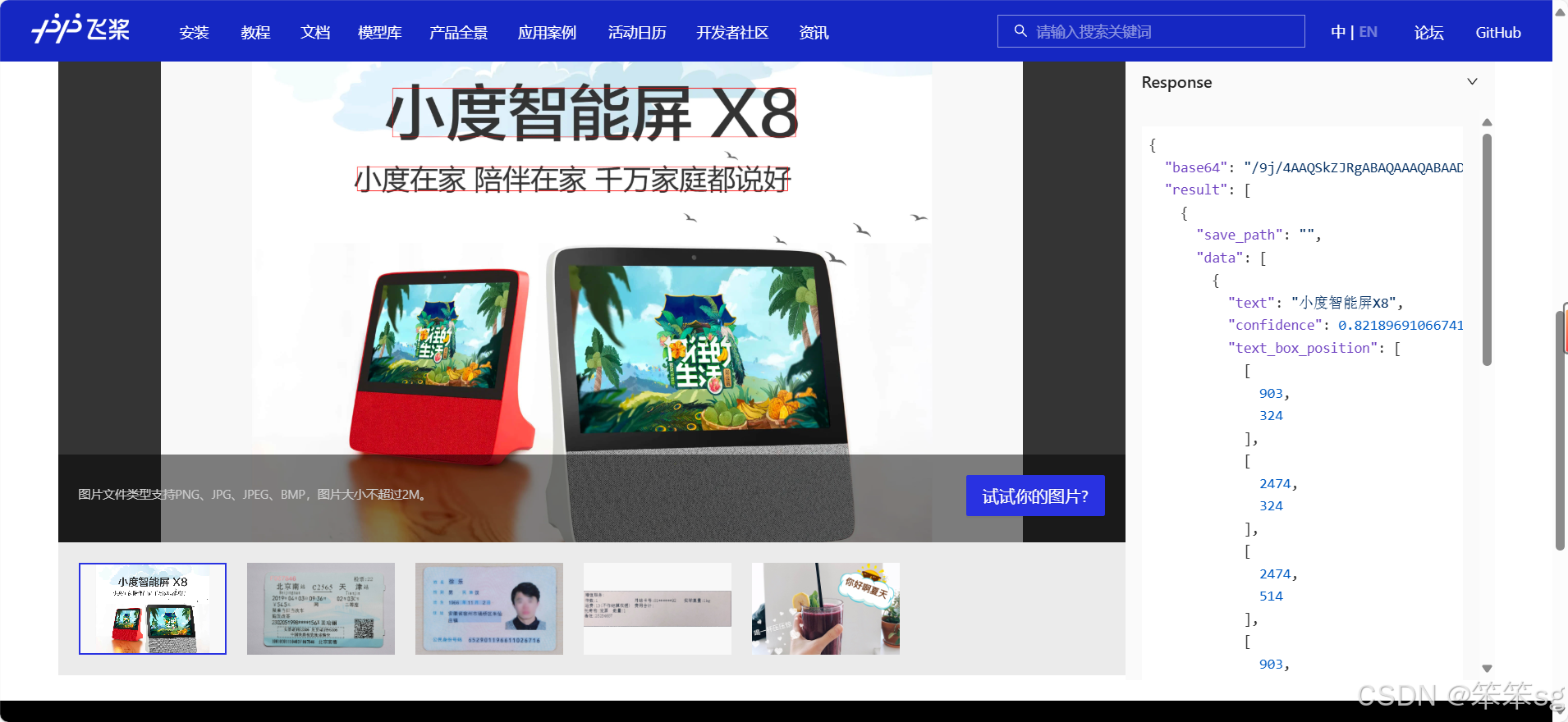
4 本地运行
4.1 环境配置
建议大家单独创建一个虚拟环境用于该项目,下面以我本人的辣鸡电脑为例进行演示:
(当然如果你电脑没显卡的话你也可以选择使用CPU,直接安装paddlepaddle和paddleocr即可)
Step1:查看CUDA版本
首先CMD中输入如下代码查看本地所能支持的最高CUDA版本
nvidia-smi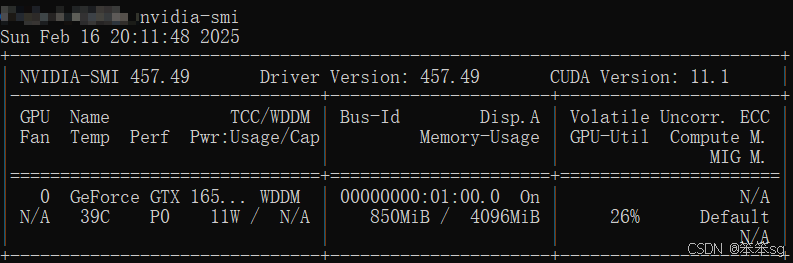
可以看到我的电脑最高只能安装11.1的CUDA。
Step2:根据CUDA版本去官网寻找对应的下载命令
链接:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
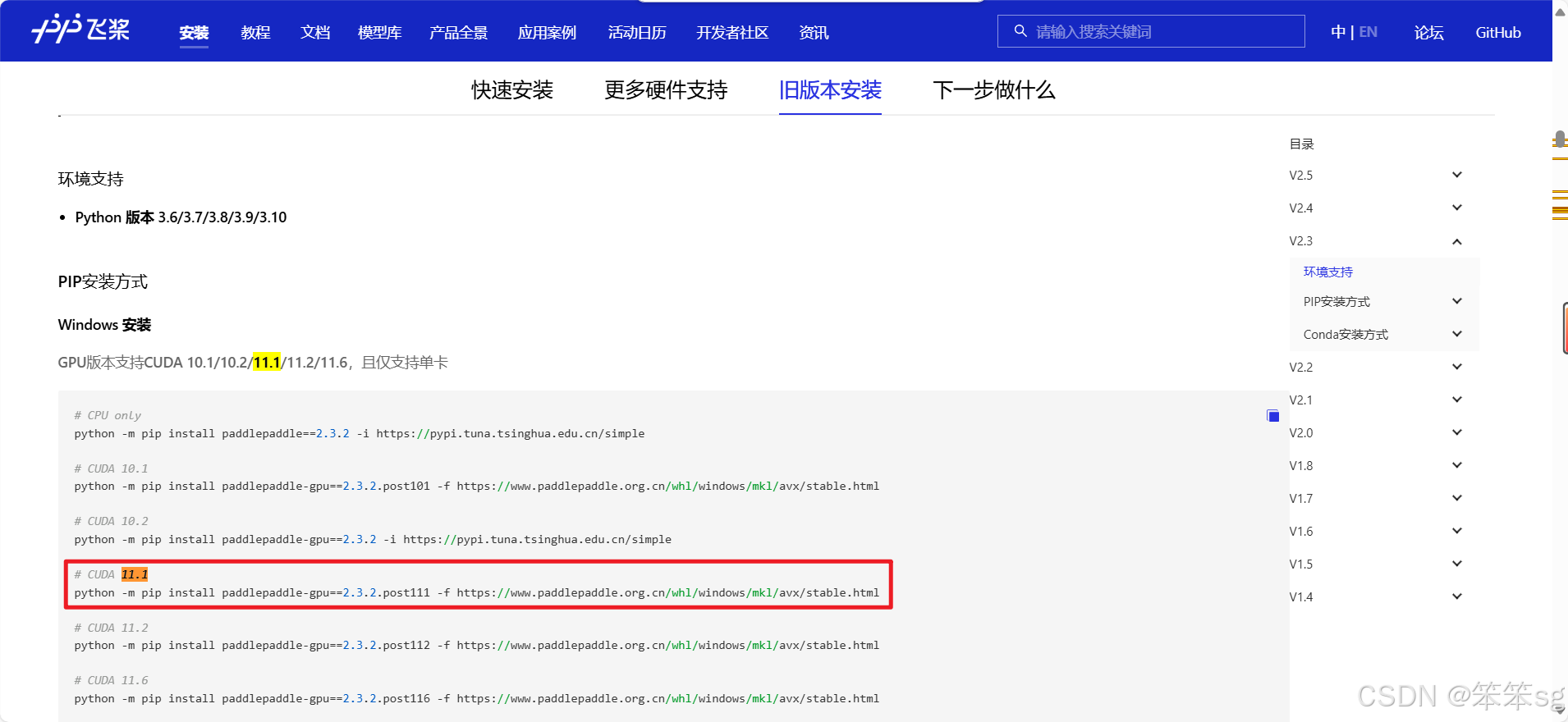
# CUDA 11.1
python -m pip install paddlepaddle-gpu==2.3.2.post111 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.htmlStep3:创建虚拟环境
conda create --prefix=你的路径 python=3.8(版本号自己选择)Step4:输入Step2中的命令安装即可
Step5:检测是否安装成功
import paddle
print(paddle.device.get_device()) # 应该输出 'gpu:0'
print(paddle.is_compiled_with_cuda()) # 应该输出 TrueStep6:安装 PaddleOCR
pip install paddleocr至此,你已经完成了环境配置的全部步骤!!!
4.2 命令行使用
paddleocr --image_dir ./imgs/1.jpg --use_angle_cls true --use_gpu 0注意:图片路径替换为你自己的,这里我以下图为例:

观察以下模型输出:
[2025/02/16 20:23:04] ppocr INFO: for usage help, please use `paddleocr --help`
[2025/02/16 20:23:04] ppocr DEBUG: Namespace(alpha=1.0, alphacolor=(255, 255, 255), benchmark=False, beta=1.0, binarize=False, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='C:\\Users\\SGHN/.paddleocr/whl\\cls\\ch_ppocr_mobile_v2.0_cls_infer', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.6, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='C:\\Users\\SGHN/.paddleocr/whl\\det\\ch\\ch_PP-OCRv4_det_infer', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, formula=False, formula_algorithm='LaTeXOCR', formula_batch_num=1, formula_char_dict_path=None, formula_model_dir=None, fourier_degree=5, gpu_id=0, gpu_mem=500, help='==SUPPRESS==', image_dir='./imgs/1.jpg', image_orientation=False, invert=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='ch', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv4', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='F:\\Anaconda\\envs\\paddle_ocr\\lib\\site-packages\\paddleocr\\ppocr\\utils\\ppocr_keys_v1.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='C:\\Users\\SGHN/.paddleocr/whl\\rec\\ch\\ch_PP-OCRv4_rec_infer', recovery=False, recovery_to_markdown=False, return_word_box=False, save_crop_res=False, save_log_path='./log_output/', savefile=False, scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=False, use_mlu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2025/02/16 20:23:05] ppocr INFO: **********./imgs/1.jpg**********
[2025/02/16 20:23:05] ppocr DEBUG: dt_boxes num : 2, elapsed : 0.2707352638244629
[2025/02/16 20:23:05] ppocr DEBUG: cls num : 2, elapsed : 0.023896455764770508
[2025/02/16 20:23:06] ppocr DEBUG: rec_res num : 2, elapsed : 0.5195872783660889
[2025/02/16 20:23:06] ppocr INFO: [[[60.0, 19.0], [490.0, 19.0], [490.0, 60.0], [60.0, 60.0]], ('ONE DOESNOTSIMPLY', 0.9739073514938354)]
[2025/02/16 20:23:06] ppocr INFO: [[[103.0, 275.0], [448.0, 277.0], [448.0, 312.0], [103.0, 310.0]], ('WALKAFTER LEGDAY', 0.970147967338562)]最后两行就是我们所要的东西,结果是一个list,每个item包含了文本框,文字和识别置信度,可以看到模型很好地识别出来了文字,但间隔做的不是很好。
现在你可能会问:“有那么多参数,我怎么知道每个都是什么意思?”
这个你可以使用如下命令进行查看:
paddleocr - -helpusage: paddleocr [-h] [--use_gpu USE_GPU] [--use_xpu USE_XPU]
[--use_npu USE_NPU] [--use_mlu USE_MLU] [--ir_optim IR_OPTIM]
[--use_tensorrt USE_TENSORRT]
[--min_subgraph_size MIN_SUBGRAPH_SIZE]
[--precision PRECISION] [--gpu_mem GPU_MEM] [--gpu_id GPU_ID]
[--image_dir IMAGE_DIR] [--page_num PAGE_NUM]
[--det_algorithm DET_ALGORITHM]
[--det_model_dir DET_MODEL_DIR]
[--det_limit_side_len DET_LIMIT_SIDE_LEN]
[--det_limit_type DET_LIMIT_TYPE]
[--det_box_type DET_BOX_TYPE] [--det_db_thresh DET_DB_THRESH]
[--det_db_box_thresh DET_DB_BOX_THRESH]
[--det_db_unclip_ratio DET_DB_UNCLIP_RATIO]
[--max_batch_size MAX_BATCH_SIZE]
[--use_dilation USE_DILATION]
[--det_db_score_mode DET_DB_SCORE_MODE]
[--det_east_score_thresh DET_EAST_SCORE_THRESH]
[--det_east_cover_thresh DET_EAST_COVER_THRESH]
[--det_east_nms_thresh DET_EAST_NMS_THRESH]
[--det_sast_score_thresh DET_SAST_SCORE_THRESH]
[--det_sast_nms_thresh DET_SAST_NMS_THRESH]
[--det_pse_thresh DET_PSE_THRESH]
[--det_pse_box_thresh DET_PSE_BOX_THRESH]
[--det_pse_min_area DET_PSE_MIN_AREA]
[--det_pse_scale DET_PSE_SCALE] [--scales SCALES]
[--alpha ALPHA] [--beta BETA]
[--fourier_degree FOURIER_DEGREE]
[--rec_algorithm REC_ALGORITHM]
[--rec_model_dir REC_MODEL_DIR]
[--rec_image_inverse REC_IMAGE_INVERSE]
[--rec_image_shape REC_IMAGE_SHAPE]
[--rec_batch_num REC_BATCH_NUM]
[--max_text_length MAX_TEXT_LENGTH]
[--rec_char_dict_path REC_CHAR_DICT_PATH]
[--use_space_char USE_SPACE_CHAR]
[--vis_font_path VIS_FONT_PATH] [--drop_score DROP_SCORE]
[--e2e_algorithm E2E_ALGORITHM]
[--e2e_model_dir E2E_MODEL_DIR]
[--e2e_limit_side_len E2E_LIMIT_SIDE_LEN]
[--e2e_limit_type E2E_LIMIT_TYPE]
[--e2e_pgnet_score_thresh E2E_PGNET_SCORE_THRESH]
[--e2e_char_dict_path E2E_CHAR_DICT_PATH]
[--e2e_pgnet_valid_set E2E_PGNET_VALID_SET]
[--e2e_pgnet_mode E2E_PGNET_MODE]
[--use_angle_cls USE_ANGLE_CLS]
[--cls_model_dir CLS_MODEL_DIR]
[--cls_image_shape CLS_IMAGE_SHAPE] [--label_list LABEL_LIST]
[--cls_batch_num CLS_BATCH_NUM] [--cls_thresh CLS_THRESH]
[--enable_mkldnn ENABLE_MKLDNN] [--cpu_threads CPU_THREADS]
[--use_pdserving USE_PDSERVING] [--warmup WARMUP]
[--sr_model_dir SR_MODEL_DIR]
[--sr_image_shape SR_IMAGE_SHAPE]
[--sr_batch_num SR_BATCH_NUM]
[--draw_img_save_dir DRAW_IMG_SAVE_DIR]
[--save_crop_res SAVE_CROP_RES]
[--crop_res_save_dir CROP_RES_SAVE_DIR] [--use_mp USE_MP]
[--total_process_num TOTAL_PROCESS_NUM]
[--process_id PROCESS_ID] [--benchmark BENCHMARK]
[--save_log_path SAVE_LOG_PATH] [--show_log SHOW_LOG]
[--use_onnx USE_ONNX] [--return_word_box RETURN_WORD_BOX]
[--output OUTPUT] [--table_max_len TABLE_MAX_LEN]
[--table_algorithm TABLE_ALGORITHM]
[--table_model_dir TABLE_MODEL_DIR]
[--merge_no_span_structure MERGE_NO_SPAN_STRUCTURE]
[--table_char_dict_path TABLE_CHAR_DICT_PATH]
[--formula_algorithm FORMULA_ALGORITHM]
[--formula_model_dir FORMULA_MODEL_DIR]
[--formula_char_dict_path FORMULA_CHAR_DICT_PATH]
[--formula_batch_num FORMULA_BATCH_NUM]
[--layout_model_dir LAYOUT_MODEL_DIR]
[--layout_dict_path LAYOUT_DICT_PATH]
[--layout_score_threshold LAYOUT_SCORE_THRESHOLD]
[--layout_nms_threshold LAYOUT_NMS_THRESHOLD]
[--kie_algorithm KIE_ALGORITHM]
[--ser_model_dir SER_MODEL_DIR] [--re_model_dir RE_MODEL_DIR]
[--use_visual_backbone USE_VISUAL_BACKBONE]
[--ser_dict_path SER_DICT_PATH]
[--ocr_order_method OCR_ORDER_METHOD]
[--mode {structure,kie}]
[--image_orientation IMAGE_ORIENTATION] [--layout LAYOUT]
[--table TABLE] [--formula FORMULA] [--ocr OCR]
[--recovery RECOVERY]
[--recovery_to_markdown RECOVERY_TO_MARKDOWN]
[--use_pdf2docx_api USE_PDF2DOCX_API] [--invert INVERT]
[--binarize BINARIZE] [--alphacolor ALPHACOLOR] [--lang LANG]
[--det DET] [--rec REC] [--type TYPE] [--savefile SAVEFILE]
[--ocr_version {PP-OCR,PP-OCRv2,PP-OCRv3,PP-OCRv4}]
[--structure_version {PP-Structure,PP-StructureV2}]
paddleocr: error: argument -h/--help: ignored explicit argument 'elp'此外,paddleocr也支持输入pdf文件,并且可以通过指定参数page_num来控制推理前面几页,默认为0,表示推理所有页。
paddleocr --image_dir ./xxx.pdf --use_angle_cls true --use_gpu false --page_num 2版本说明 paddleocr默认使用PP-OCRv4模型(--ocr_version PP-OCRv4),如需使用其他版本可通过设置参数--ocr_version,具体版本说明如下:

4.3 常用的参数
- 单独使用检测:设置
--rec为false
结果是一个list,每个item只包含文本框
[[27.0, 459.0], [136.0, 459.0], [136.0, 479.0], [27.0, 479.0]]
[[28.0, 429.0], [372.0, 429.0], [372.0, 445.0], [28.0, 445.0]]
......- 单独使用识别:设置
--det为false
paddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.994467]- 多语言检测:设置
--lang参数
PaddleOCR目前支持80个语种,可以通过修改--lang参数进行切换,对于英文模型,指定--lang=en
paddleocr --image_dir ./imgs_en/254.jpg --lang=en
结果是一个list,每个item包含了文本框,文字和识别置信度
[[[67.0, 51.0], [327.0, 46.0], [327.0, 74.0], [68.0, 80.0]], ('PHOCAPITAL', 0.9944712519645691)]
[[[72.0, 92.0], [453.0, 84.0], [454.0, 114.0], [73.0, 122.0]], ('107 State Street', 0.9744491577148438)]
[[[69.0, 135.0], [501.0, 125.0], [501.0, 156.0], [70.0, 165.0]], ('Montpelier Vermont', 0.9357033967971802)]
......全部语种及其对应的缩写列表可查看多语言模型教程
实测ch可以同时检测一张图片中的中英文,en只能检测英文。
4.4 Python脚本使用
from paddleocr import PaddleOCR, draw_ocr
# 初始化 PaddleOCR,优化参数
ocr = PaddleOCR(
use_angle_cls=True, # 启用文本方向分类器
lang="en", # 指定语言为英文
rec=True, # 启用文本识别模型
cls=True, # 启用文本方向分类器
use_gpu=True, # 启用 GPU 加速
det_db_thresh=0.3, # 文本检测阈值
det_db_box_thresh=0.5, # 文本检测框阈值
det_db_unclip_ratio=1.5, # 文本检测框扩展比例
rec_image_shape="3, 32, 320", # 文本识别模型输入图像尺寸
drop_score=0.5, # 过滤低置信度识别结果
)
img_path = "./imgs/1.jpg"
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert("RGB")
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path="./fonts/simfang.ttf")
im_show = Image.fromarray(im_show)
im_show.save("result.jpg")[2025/02/16 20:45:51] ppocr DEBUG: Namespace(alpha=1.0, alphacolor=(255, 255, 255), benchmark=False, beta=1.0, binarize=False, cls=True, cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='C:\\Users\\SGHN/.paddleocr/whl\\cls\\ch_ppocr_mobile_v2.0_cls_infer', cls_thresh=0.9, cpu_threads=10, crop_res_save_dir='./output', det=True, det_algorithm='DB', det_box_type='quad', det_db_box_thresh=0.5, det_db_score_mode='fast', det_db_thresh=0.3, det_db_unclip_ratio=1.5, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='C:\\Users\\SGHN/.paddleocr/whl\\det\\en\\en_PP-OCRv3_det_infer', det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, det_pse_thresh=0, det_sast_nms_thresh=0.2, det_sast_score_thresh=0.5, draw_img_save_dir='./inference_results', drop_score=0.5, e2e_algorithm='PGNet', e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_limit_side_len=768, e2e_limit_type='max', e2e_model_dir=None, e2e_pgnet_mode='fast', e2e_pgnet_score_thresh=0.5, e2e_pgnet_valid_set='totaltext', enable_mkldnn=False, formula=False, formula_algorithm='LaTeXOCR', formula_batch_num=1, formula_char_dict_path=None, formula_model_dir=None, fourier_degree=5, gpu_id=0, gpu_mem=500, help='==SUPPRESS==', image_dir=None, image_orientation=False, invert=False, ir_optim=True, kie_algorithm='LayoutXLM', label_list=['0', '180'], lang='en', layout=True, layout_dict_path=None, layout_model_dir=None, layout_nms_threshold=0.5, layout_score_threshold=0.5, max_batch_size=10, max_text_length=25, merge_no_span_structure=True, min_subgraph_size=15, mode='structure', ocr=True, ocr_order_method=None, ocr_version='PP-OCRv4', output='./output', page_num=0, precision='fp32', process_id=0, re_model_dir=None, rec=True, rec_algorithm='SVTR_LCNet', rec_batch_num=6, rec_char_dict_path='f:\\Anaconda\\envs\\paddle_ocr\\lib\\site-packages\\paddleocr\\ppocr\\utils\\en_dict.txt', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_model_dir='C:\\Users\\SGHN/.paddleocr/whl\\rec\\en\\en_PP-OCRv4_rec_infer', recovery=False, recovery_to_markdown=False, return_word_box=False, save_crop_res=False, save_log_path='./log_output/', savefile=False, scales=[8, 16, 32], ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ser_model_dir=None, show_log=True, sr_batch_num=1, sr_image_shape='3, 32, 128', sr_model_dir=None, structure_version='PP-StructureV2', table=True, table_algorithm='TableAttn', table_char_dict_path=None, table_max_len=488, table_model_dir=None, total_process_num=1, type='ocr', use_angle_cls=True, use_dilation=False, use_gpu=True, use_mlu=False, use_mp=False, use_npu=False, use_onnx=False, use_pdf2docx_api=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_visual_backbone=True, use_xpu=False, vis_font_path='./doc/fonts/simfang.ttf', warmup=False)
[2025/02/16 20:45:51] ppocr WARNING: The first GPU is used for inference by default, GPU ID: 0
[2025/02/16 20:45:52] ppocr WARNING: The first GPU is used for inference by default, GPU ID: 0
[2025/02/16 20:45:53] ppocr WARNING: The first GPU is used for inference by default, GPU ID: 0
[2025/02/16 20:45:54] ppocr DEBUG: dt_boxes num : 2, elapsed : 0.051377296447753906
[2025/02/16 20:45:54] ppocr DEBUG: cls num : 2, elapsed : 0.013004064559936523
[2025/02/16 20:45:54] ppocr DEBUG: rec_res num : 2, elapsed : 0.022168874740600586
[[[60.0, 18.0], [488.0, 20.0], [488.0, 58.0], [60.0, 56.0]], ('ONEDOESNOTSIMPLY', 0.9400332570075989)]
[[[105.0, 278.0], [446.0, 278.0], [446.0, 310.0], [105.0, 310.0]], ('WALKAFTER LEGDAY', 0.968696117401123)]
如果你在运行时遇到了如下报错信息:
Could not load library cudnn_cnn_infer64_8.dll. Error code 126可以参见下面文章的解决方案:
Could not load library cudnn_ops_infer64_8.dll. Error code 126
4.5 加速推理
如果你现在需要对一大批图片进行推理识别,你可以考虑如下的参数:
use_mp=True:
作用: 启用多进程(Multi-Processing)来加速模型的推理过程。
解释: 多进程允许程序同时使用多个CPU核心来并行处理任务。在深度学习推理中,使用多进程可以显著提高处理速度,尤其是在处理大量数据时。通过将任务分配到多个进程中,可以充分利用多核CPU的计算能力,减少总体推理时间。
适用场景: 当你有多个CPU核心,并且希望加快推理速度时,可以启用多进程。
enable_mkldnn=True:
作用: 启用MKL-DNN(Math Kernel Library for Deep Neural Networks)加速。
解释: MKL-DNN是Intel开发的一个高性能深度学习库,专门用于优化在Intel CPU上的深度学习推理性能。启用MKL-DNN可以利用Intel CPU的特定指令集和硬件优化,从而加速模型的推理过程。
适用场景: 当你在Intel CPU上运行深度学习模型时,启用MKL-DNN可以显著提高推理速度。
rec_batch_num=48:
作用: 设置文本识别模型的批处理大小(Batch Size)。
解释: 批处理大小是指在一次推理过程中同时处理的样本数量。较大的批处理大小可以提高GPU或CPU的利用率,从而加快推理速度。然而,批处理大小也受限于硬件内存的大小。
rec_batch_num=48表示每次推理时,模型会同时处理48个样本。适用场景: 当你希望提高推理速度,并且硬件(如GPU或CPU)有足够的内存来支持较大的批处理大小时,可以适当增加批处理大小。
5 关于模型训练
本篇笔记仅记录使用PaddleOCR进行推理,如果你对训练感兴趣,可以查看以下笔记:
2024年最新版PaddleOCR新手指导(训练自己的数据集与知识蒸馏) - 飞桨AI Studio星河社区6
6 关于中英文OCR领域最好的开源工具
注:以下内容由DeepSeek生成:
6.1 中文OCR
-
PaddleOCR
-
特点: 由百度开发,支持多语言(包括中文和英文),提供预训练模型,识别精度高,支持文本检测、方向分类和识别。
-
优势: 更新频繁,社区活跃,文档完善,适合工业应用。
-
-
CnOCR
-
特点: 专注于中文OCR,轻量级,适合简单场景。
-
优势: 易于使用,适合快速集成。
-
6.2 英文OCR
-
Tesseract
-
特点: 由Google维护,支持多种语言(包括英文),历史悠久,社区庞大。
-
优势: 成熟稳定,支持自定义训练,适合复杂场景。
-
-
EasyOCR
-
特点: 支持多语言(包括英文),基于深度学习,识别速度快。
-
优势: 使用简单,适合快速部署。
-
6.3 总结
-
中文OCR: PaddleOCR 是最佳选择,CnOCR 适合轻量级需求。
-
英文OCR: Tesseract 最为成熟,EasyOCR 适合快速部署。
根据具体需求选择合适的工具。
如果你想要了解Tesseract,可以参见:
tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









