






目录
3 通过 Hugging Face Transformers 使用 BLIP-2
1 前言
BLIP-2(Bootstrapping Language-Image Pretraining)是一种结合了图像和语言处理的深度学习模型,旨在实现高效的视觉语言理解。BLIP-2 主要用于解决图像到文本的生成任务(如图像描述生成、视觉问答等)和文本到图像的检索任务。
BLIP-2 是基于视觉-语言预训练的,它通过引入轻量级的视觉模块和强大的语言模型来增强图像和文本之间的关联。BLIP-2 在视觉理解和文本生成方面的表现显著提高,尤其是在零样本学习(Zero-shot Learning)和少样本学习(Few-shot Learning)任务中。
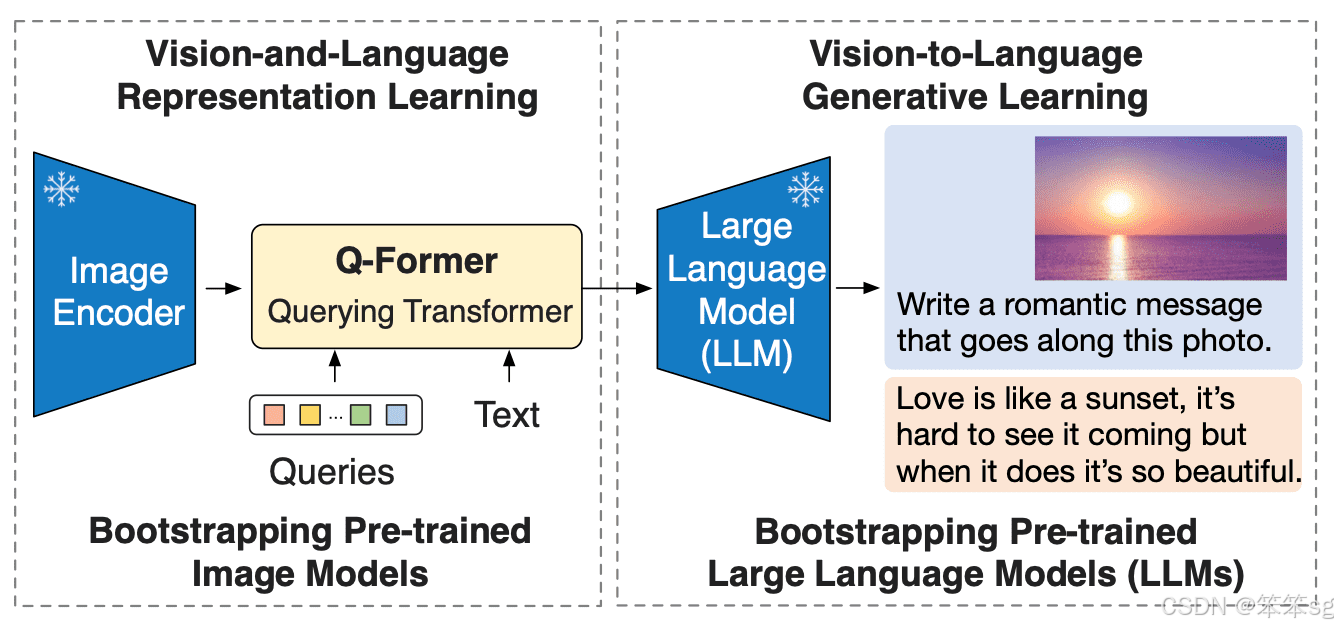
BLIP-2 通过引入一种新的视觉语言预训练范式来应对这一挑战,该范式可以任意组合并充分利用两个预训练好的视觉编码器和 LLM,而无须端到端地预训练整个架构。这使得我们可以在多个视觉语言任务上实现最先进的结果,同时显著减少训练参数量和预训练成本。此外,这种方法为多模态ChatGPT 类应用奠定了基础。双模态预训练:
- 视觉模块(Vision Encoder):BLIP-2 使用了一种叫做 "Querying Transformer" 的视觉编码器,能够有效地提取图像特征,并将图像内容转换为语言模型能够理解的输入格式。
- 语言模块(Language Model):BLIP-2 集成了强大的语言模型,通常是以 FLAN-T5 或 OPT 系列为基础。这使得 BLIP-2 不仅可以生成图像描述,还可以在视觉问答等任务中有效地理解和生成文本。
BLIP2虽曾风靡一时,凭借其较高的推理效率取得了一定的关注,但其生成质量尚显不足,且对图像的理解深度略显浅薄。接下来,我们将简要回顾BLIP2的特点及使用Demo,并介绍一些生成质量更为优异的开源工具。我们的终极目标是寻找一款兼具生成质量与推理效率的理想工具,以便在短时间内高效处理上万条图片的Caption任务。
2 BLIP-2 葫芦里卖的什么药?
Transformer-BLIP2使用文档:
BLIP2上手demo:
Transformers-Tutorials/BLIP-2 at master · NielsRogge/Transformers-Tutorials
BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂 (modality gap)。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。
Q-Former 是一个 transformer 模型,它由两个子模块组成,这两个子模块共享相同的自注意力层:
- 与冻结的图像编码器交互的图像 transformer,用于视觉特征提取
- 文本 transformer,用作文本编码器和解码器
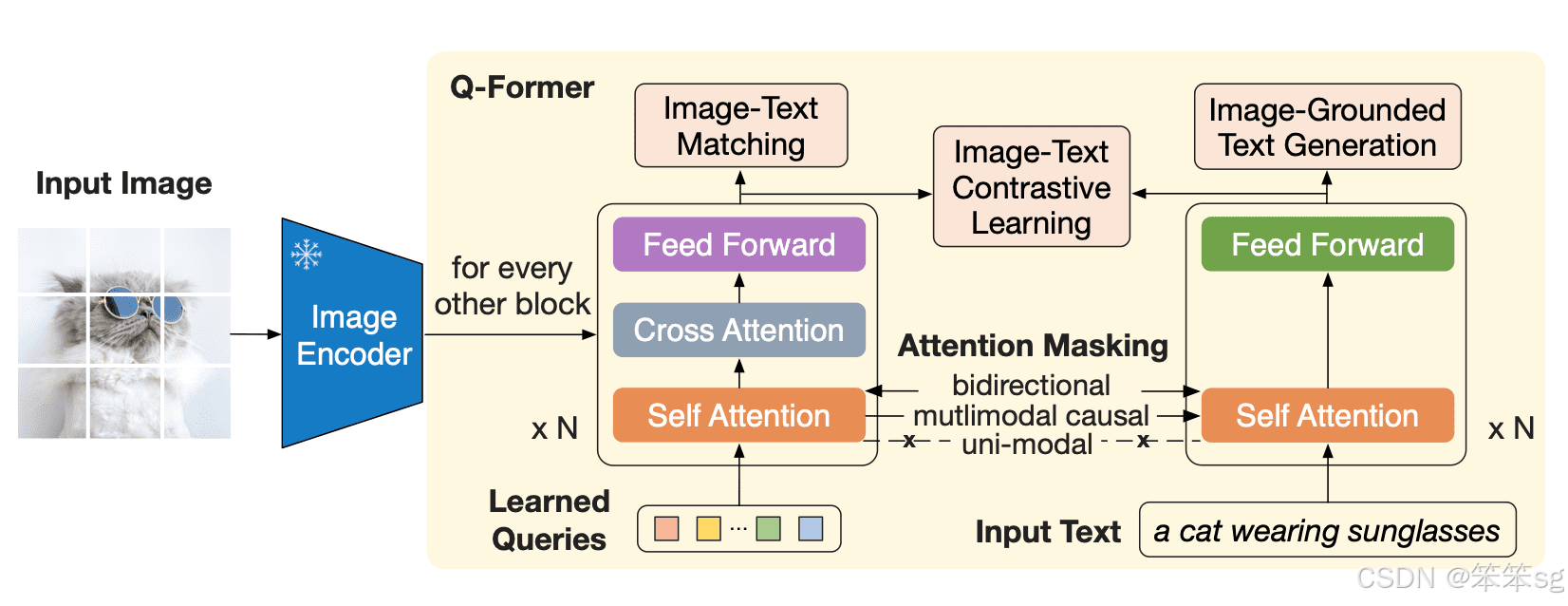
图像 transformer 从图像编码器中提取固定数量的输出特征,这里特征的个数与输入图像分辨率无关。同时,图像 transformer 接收若干查询嵌入作为输入,这些查询嵌入是可训练的。这些查询还可以通过相同的自注意力层与文本进行交互 (译者注: 这里的相同是指图像 transformer 和文本 transformer 对应的自注意力层是共享的)。
Q-Former 分两个阶段进行预训练。第一阶段,图像编码器被冻结,Q-Former 通过三个损失函数进行训练:
- 图文对比损失 (image-text contrastive loss): 每个查询的输出都与文本输出的 CLS 词元计算成对相似度,并从中选择相似度最高的一个最终计算对比损失。在该损失函数下,查询嵌入和文本不会 “看到” 彼此。
- 基于图像的文本生成损失: 查询内部可以相互计算注意力但不计算文本词元对查询的注意力,同时文本内部的自注意力使用因果掩码且需计算所有查询对文本的注意力。
- 图文匹配损失 (image-text matching loss): 查询和文本可以看到彼此,最终获得一个几率 (logit) 用以表示文字与图像是否匹配。这里,使用难例挖掘技术 (hard negative mining) 来生成负样本。
图像 transformer 作为一个信息瓶颈 (information bottleneck),查询嵌入经过它后,其输出嵌入已经不仅仅包含了视觉信息,而且包含了与文本相关的视觉信息。这些输出嵌入用作第二阶段 LLM 输入的视觉前缀。该预训练阶段主要涉及一个以基于图像的文本生成任务,损失函数使用因果 LM 损失。
BLIP-2 使用 ViT 作为视觉编码器。而对于 LLM,论文作者使用 OPT 和 Flan T5 模型。你可以找到在 Hugging Face Hub 上找到 OPT 和 Flan T5 的预训练 checkpoints。但不要忘记,如前所述,BLIP-2 设计的预训练方法允许任意的视觉主干模型和 LLM 的组合。
3 通过 Hugging Face Transformers 使用 BLIP-2
3.1 环境配置
Case1:如果你本地具备较好的显卡,可以支持较新的transformers库,只需要配置好pytorch以及transformers这两大库即可,关于pytorch的配置可以参见下面这篇文章:
⭐⭐[ pytorch+tensorflow ]⭐⭐配置两大框架下的GPU训练环境
Case2:如果不满足上述条件,建议你直接使用Kaggle中的GPU环境,也不需要再考虑pytorch和transformers版本的适配问题。
3.2 demo(理解图片背后的深刻内涵--“梗”)
这里以Case2为例,我们在Kaggle中选择GPU P100(16G的显存)
Step1:获取推理用的图片

import requests
from PIL import Image
url = 'https://th.bing.com/th/id/R.6d824950328338b56899df6720c8e153?rik=FXKByzAJM3qWlg&riu=http%3a%2f%2fwww.quickmeme.com%2fimg%2f4e%2f4e3bf1b222d6bcaf8bd7e560d7369f20249c5ebe48fd6da0a05cc2d02e1e7d0e.jpg&ehk=Dr3YqQMLIkX6SXtxw5RJBhHVA2G38d7TRmVdYi0IZhc%3d&risl=&pid=ImgRaw&r=0'
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
display(image.resize((596, 437)))Step2: 加载 BLIP-2 模型及其对应的处理器
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
# by default `from_pretrained` loads the weights in float32
# we load in float16 instead to save memory
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16) 
Step3:将模型转移到GPU上加速推理
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)Blip2ForConditionalGeneration(
(vision_model): Blip2VisionModel(
(embeddings): Blip2VisionEmbeddings(
(patch_embedding): Conv2d(3, 1408, kernel_size=(14, 14), stride=(14, 14))
)
(encoder): Blip2Encoder(
(layers): ModuleList(
(0-38): 39 x Blip2EncoderLayer(
(self_attn): Blip2Attention(
(dropout): Dropout(p=0.0, inplace=False)
(qkv): Linear(in_features=1408, out_features=4224, bias=True)
(projection): Linear(in_features=1408, out_features=1408, bias=True)
)
(layer_norm1): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)
(mlp): Blip2MLP(
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1408, out_features=6144, bias=True)
(fc2): Linear(in_features=6144, out_features=1408, bias=True)
)
(layer_norm2): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)
)
(qformer): Blip2QFormerModel(
(layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
(encoder): Blip2QFormerEncoder(
(layer): ModuleList(
(0): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=1408, out_features=768, bias=True)
(value): Linear(in_features=1408, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=1408, out_features=768, bias=True)
(value): Linear(in_features=1408, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=1408, out_features=768, bias=True)
(value): Linear(in_features=1408, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=1408, out_features=768, bias=True)
(value): Linear(in_features=1408, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=1408, out_features=768, bias=True)
(value): Linear(in_features=1408, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=1408, out_features=768, bias=True)
(value): Linear(in_features=1408, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): Blip2QFormerLayer(
(attention): Blip2QFormerAttention(
(attention): Blip2QFormerMultiHeadAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): Blip2QFormerSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate_query): Blip2QFormerIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output_query): Blip2QFormerOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(language_projection): Linear(in_features=768, out_features=2560, bias=True)
(language_model): OPTForCausalLM(
(model): OPTModel(
(decoder): OPTDecoder(
(embed_tokens): Embedding(50304, 2560, padding_idx=1)
(embed_positions): OPTLearnedPositionalEmbedding(2050, 2560)
(final_layer_norm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(layers): ModuleList(
(0-31): 32 x OPTDecoderLayer(
(self_attn): OPTSdpaAttention(
(k_proj): Linear(in_features=2560, out_features=2560, bias=True)
(v_proj): Linear(in_features=2560, out_features=2560, bias=True)
(q_proj): Linear(in_features=2560, out_features=2560, bias=True)
(out_proj): Linear(in_features=2560, out_features=2560, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=2560, out_features=10240, bias=True)
(fc2): Linear(in_features=10240, out_features=2560, bias=True)
(final_layer_norm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(lm_head): Linear(in_features=2560, out_features=50304, bias=False)
)
)Step4:开始推理(不含Prompt)
如果不提供任何文本提示,则模型将在默认情况下开始从BOS(序列开始)令牌生成文本。它会为图像生成一个标题。
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)one does not simply walk after leg day
可以看到模型只是简单地提取出了文字,没有能深刻地分析这个图片的含义。
Step5:开始推理(含Prompt)
您可以提供一个文本提示,模型将在给定图像的情况下继续执行该提示。
prompt = "The profound meaning of this picture is"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)The profound meaning of this picture is one does not simply walk after leg day
可以看到即使我们暗示后,模型依然不能输出其真正内涵,这可能是由于:
BLIP-2 的预训练主要是为了结合图像和文本信息完成视觉语言任务,比如图像描述生成和视觉问答(VQA)。但它不一定在所有任务上都表现出色,尤其是复杂推理或生成任务(如深入的语义分析)。如果模型的权重预训练数据中类似任务不足,那么即使你提供复杂的
prompt,模型也可能倾向于生成最直接的输出,例如简单地识别图像中的文字或常规描述。
Step6:开始推理(VQA)
prompt = "Question: Who is this man? Answer:"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)Question: Who is this man? Answer: One does not simply walk after leg day
当然,我们也可以创建一个类似chatgpt的界面,只需将每个生成的响应连接到对话中。我们用一些文本提示模型(比如“这是哪个城市?”),模型为它生成一个答案“新加坡”),我们将这些文本连接到对话中。然后我们问一个后续问题(“为什么?”),我们也只是连接并提供给模型。
这意味着上下文不能太长——像OPT和T5这样的模型(在BLIP-2中使用的语言模型)的上下文长度为512个令牌。
总的来说,BLIP-2所采用的模型在输出简单的图片描述时表现尚可,但在深度理解图像的内涵,尤其是诸如梗等更具文化和情感色彩的元素时,往往力不从心。
3.3 demo(简单描述图片)
下面我们简单举一个例子来展示BLIP-2在“简单描述图片”这个任务上还是能做的不错的。

import requests
from PIL import Image
url = 'https://th.bing.com/th/id/R.3424c634dd60cb08e88d4a3725c9f511?rik=TwKABDUwVmIYQg&riu=http%3a%2f%2fn.sinaimg.cn%2fauto%2f528%2fw769h559%2f20200326%2f11af-irkazzv2171390.jpg&ehk=sFy4NcHq3%2b1QlAUIaHvhvKJ39G82CacLJONDIw1vjGw%3d&risl=&pid=ImgRaw&r=0'
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
display(image.resize((596, 437)))inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)elon musk is holding up his iron man glove
3.4 结论
优点:
BLIP-2 是一种零样本视觉语言模型,可用于各种含图像和文本提示的图像到文本任务。这是一种效果好且效率高的方法,可应用于多种场景下的图像理解,特别是当训练样本稀缺时。
该模型通过在预训练模型之间添加 transformer 来弥合视觉和自然语言模态之间的隔阂。这一新的预训练范式使它能够充分享受两种模态的各自的进展的红利。
如果您想了解如何针对各种视觉语言任务微调 BLIP-2 模型,请查看 Salesforce 提供的 LAVIS 库,它为模型训练提供全面支持。
要查看 BLIP-2 的运行情况,可以在 Hugging Face Spaces 上试用其演示。
局限性:
BLIP-2 的视觉模型如 ViT(Vision Transformer)能够很好地捕捉图片的低级特征(如物体位置、类别、结构等),但它对图片中的情感、意图、复杂交互的理解仍然有限。例如:
- 如果一张图片中有模棱两可的表情,BLIP-2 很难推断出其背后的含义。
- 对于图片中的幽默场景(如讽刺、双关),模型缺乏语境知识支持。
3.5 其他可供选择的模型
上文只是简单尝试了最简单的模型——"Salesforce/blip2-opt-2.7b",你也可以参见下面的链接尝试其他模型,不过显存可能会超过P100所能提供的16G显存。
4 Web端图像识别工具
下面简单介绍两款Web端图像识别工具,适合平时玩一玩:
4.1 Image Describer
刚才我们在3.2中展示的那张图片,BLIP-2并不能很好地捕捉到其背后的含义,下面我们试试一个网页端的服务:
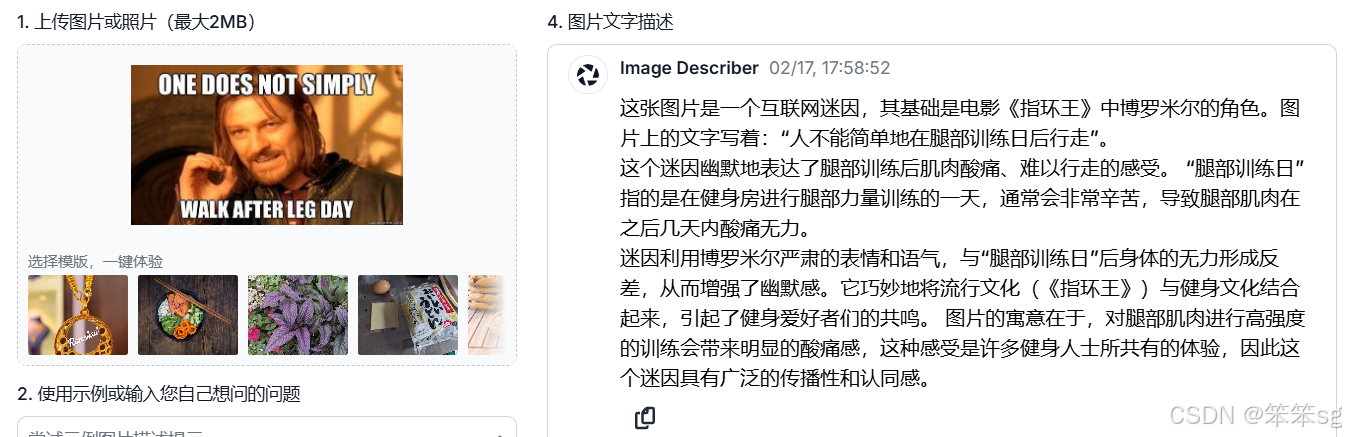
从生成质量上来看,这个模型显然优于BLIP2,但遗憾的是它是闭源的,且提供的API服务需要付费。
4.2 Image Describer X
试试另一个,这个效果也是蛮不错的,都能准确描述出图中的人物是谁而且洞悉其背后的含义。

5 JoyCaption Alpha Two
JoyCaption is an open, free, and uncensored captioning Visual Language Model (VLM).
5.1 什么是JoyCaption?
Github链接:
fpgaminer/joycaption: JoyCaption is an image captioning Visual Language Model (VLM)
JoyCaption 是一个图像描述生成的视觉语言模型(VLM),从零开始构建,作为一个免费的、开源的、无审查的模型供社区在训练扩散模型时使用。
主要特点:
- 免费和开源:将免费发布,开放权重,没有限制,就像大ASP一样,将附带训练脚本和大量有关如何构建的详细信息。
- 无审查:对SFW(适合所有年龄段)和NSFW(成人内容)概念都进行平等覆盖。没有“带白色物质的圆柱形物体”这种内容。
- 多样性:欢迎所有人。如果你喜欢数字艺术?写实风格?动漫?毛茸茸的角色?JoyCaption 为每个人而生。特别注重确保图像风格、内容、种族、性别、性取向等方面的广泛覆盖。
- 最小过滤:JoyCaption 在大量图像数据上进行训练,以便理解几乎所有方面的世界,几乎是所有内容。非法内容永远不会出现在 JoyCaption 的训练数据中。
5.2 动机
自动化的描述性标题使得扩散模型能够在更广泛的图像上进行训练和微调,因为训练者不再需要找到已经有文本关联的图像或自己编写描述。它们还提高了基于这些图像生成的文本到图像模型(例如 DALL-E 3 论文)的生成质量。然而,到目前为止,社区一直受制于 ChatGPT,后者昂贵且存在严格的审查;或者像 CogVLM 这样的替代模型,虽然也有图像描述功能,但在SFW领域以外的表现极差。
我正在构建 JoyCaption 来填补这一空白,力求在图像描述方面表现出与 GPT-4o 相近或相当的水平,同时保持免费、无审查和开源。
5.3 Demo链接
Joy Caption Alpha Two - a Hugging Face Space by fancyfeast
下面我们来重新对3.2中的图片进行试验,结果如下:
Prompt:Please describe the picture and try to analyze its deeper meaning, if it exists
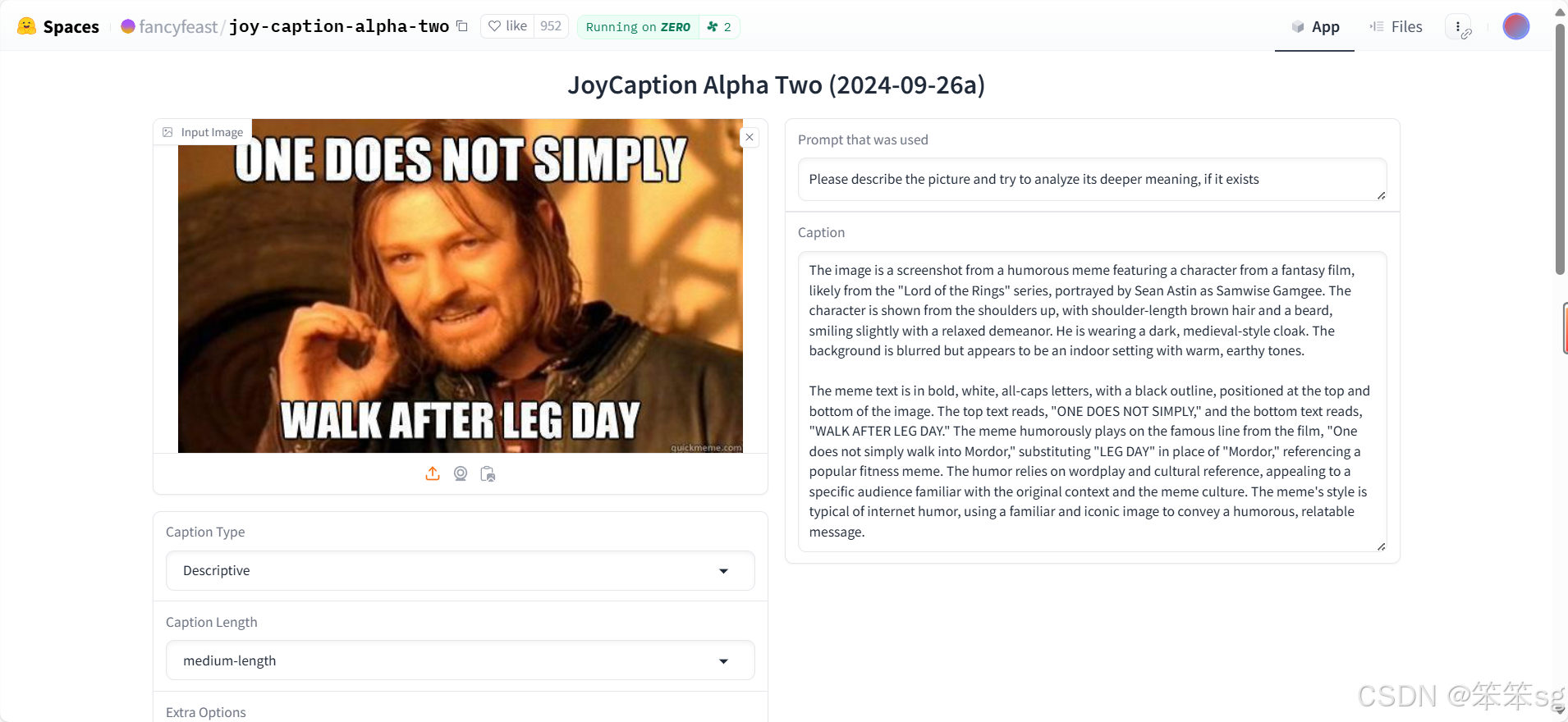

可以看到,这个模型可以深刻领悟这个图片的深层含义,而且是开源的,真是一个绝佳之选。
但是当我们手边有大量的图片数据集时,一个个手动上传无疑比较麻烦,因此有必要了解如何通过api调用这个应用。但在学习这个之前,我们有必要了解一下huggingface的Spaces模块。
5.4 huggingface的Spaces模块
Hugging Face 的 Spaces 模块 是一个让开发者和研究人员能够快速创建和分享机器学习应用的平台。它使得任何人都能将他们的机器学习模型和应用程序以简单、互动的方式展示给公众。这个模块是基于 Gradio 或 Streamlit 框架构建的,允许用户创建用户友好的网页界面,供其他人使用他们的模型进行推理和实验。
5.4.1 主要特点:
-
简化的模型部署: Spaces 使得用户无需进行复杂的部署过程即可将模型应用展示出来。通过上传代码和配置文件,用户可以创建一个可交互的 Web 界面来展示其机器学习模型。
-
开源与自由: Hugging Face 的 Spaces 是开源的,允许用户自由使用、修改、分享自己的模型和应用程序。这对于模型的开源社区来说极具吸引力。
-
Gradio 和 Streamlit: Hugging Face 提供了与 Gradio 和 Streamlit 的集成,二者都是流行的 Python 库,可以让开发者以交互式的方式创建用户界面。通过这些工具,用户可以快速构建前端界面与模型进行交互。
-
免费与付费选项: Hugging Face 提供免费的 Spaces 来展示模型,但在使用资源时会有限制。对于更高的性能和更多的功能,用户可以选择付费订阅。
-
多种任务类型支持: Spaces 支持多种类型的机器学习任务,如图像分类、文本生成、翻译、问答、语音识别等。通过提供相应的模型和接口,开发者可以展示他们的工作。
-
社区共享和发现: 由于 Spaces 是公开的,用户可以方便地发现其他人的模型应用,并进行试用或下载。它为机器学习社区提供了一个方便的交流和共享平台。
-
快速迭代与反馈: 用户可以通过 Spaces 模块快速发布新版本,收集用户反馈,快速进行改进。这对研究人员和开发人员来说是一个理想的原型测试和展示环境。
5.4.2 工作原理:
- 上传应用:开发者可以将自己的机器学习模型代码和前端界面上传到 Hugging Face。
- 配置界面:使用 Gradio 或 Streamlit,开发者为其应用设计一个交互界面,用户可以通过该界面与模型互动。
- 公开与分享:发布后,用户可以与其他人分享该应用,或通过搜索发现感兴趣的应用和模型。
5.4.3 示例:
假设你训练了一个图像分类模型,并想让别人测试它。在 Hugging Face Spaces 上,你可以:
- 上传模型和必要的 Python 代码。
- 使用 Gradio 创建一个简单的图像上传界面,允许用户选择图像并获得分类结果。
- 分享该链接,任何人都可以访问并测试你的模型。
5.5 通过API调用
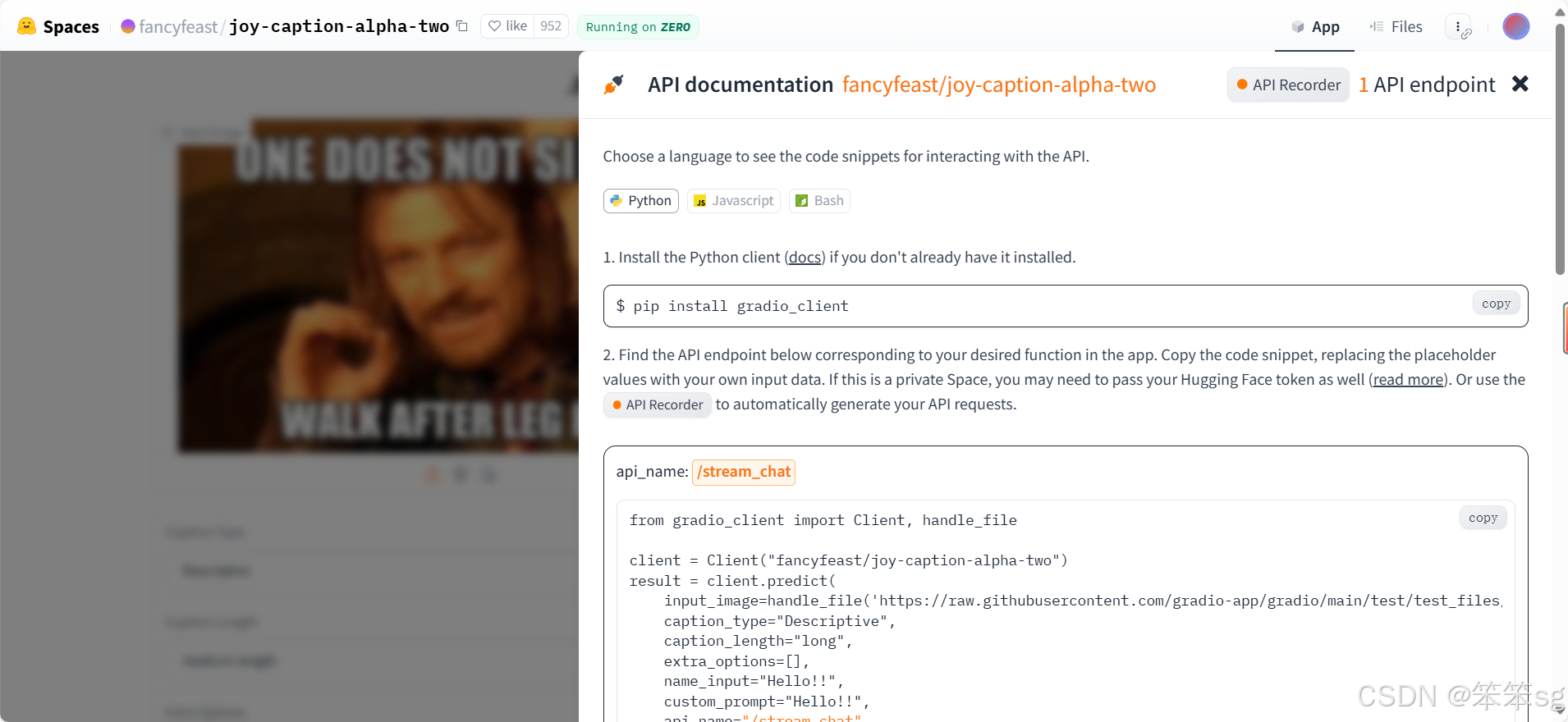
如上图所示,首先需要安装gradio_client(确保下载的是最新版本)
接着运行如下代码即可:
import os
os.environ["http_proxy"] = "http://127.0.0.1:7897" # 替换为你自己的代理服务器地址
os.environ["https_proxy"] = "http://127.0.0.1:7897"
from gradio_client import Client, handle_file
client = Client("fancyfeast/joy-caption-alpha-two")
result = client.predict(
input_image=handle_file(
"https://th.bing.com/th/id/R.6d824950328338b56899df6720c8e153?rik=FXKByzAJM3qWlg&riu=http%3a%2f%2fwww.quickmeme.com%2fimg%2f4e%2f4e3bf1b222d6bcaf8bd7e560d7369f20249c5ebe48fd6da0a05cc2d02e1e7d0e.jpg&ehk=Dr3YqQMLIkX6SXtxw5RJBhHVA2G38d7TRmVdYi0IZhc%3d&risl=&pid=ImgRaw&r=0"
),
caption_type="Descriptive",
caption_length="medium-length",
extra_options=[],
name_input="YSY",
custom_prompt="Please describe the picture and try to analyze its deeper meaning, if it exists",
api_name="/stream_chat",
)
print(result)

如果遇见HTTPSConnectionPool(host=‘huggingface.co‘, port=443)错误,参见下方链接:
出现了HTTPSConnectionPool(host=‘huggingface.co‘, port=443)错误的解决方法
但是“世界上没有免费的午餐”,虽然huggingface免费提供无服务器推理 API,但对于普通 Hugging Face 用户存在速率限制(大约每小时几百个请求)。若要访问更高的速率限制,泽可以 升级到 PRO 帐户,每月只需 9 美元。但是,对于高容量的生产推理工作负载,得查看它们的 专用推理端点 解决方案。
gradio_client.exceptions.AppError: The upstream Gradio app has raised an exception: You have exceeded your GPU quota (60s requested vs. 51s left). <a style="white-space: nowrap;text-underline-offset: 2px;color: var(--body-text-color)" href="https://huggingface.co/join">Create a free account</a> to get more usage quota.
5.6 本地部署
直接在Kaggle上部署,使用P100
import torch
import requests
from PIL import Image
from transformers import AutoProcessor, LlavaForConditionalGeneration
import time
# IMAGE_PATH = ""
PROMPT = "Please describe the picture and try to analyze its deeper meaning, if it exists"
MODEL_NAME = "fancyfeast/llama-joycaption-alpha-two-hf-llava"
# Load JoyCaption
# bfloat16 is the native dtype of the LLM used in JoyCaption (Llama 3.1)
# device_map=0 loads the model into the first GPU
processor = AutoProcessor.from_pretrained(MODEL_NAME)
llava_model = LlavaForConditionalGeneration.from_pretrained(
MODEL_NAME, torch_dtype="float16", device_map="auto"
)
llava_model.eval()
url = 'https://th.bing.com/th/id/OIP.bYJJUDKDOLVomd9nIMjhUwHaEX?w=318&h=188&c=7&r=0&o=5&pid=1.7'
with torch.no_grad():
start_time = time.time()
# Load image
# image = Image.open(IMAGE_PATH)
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
# Build the conversation
convo = [
{
"role": "system",
"content": "You are a helpful image captioner.",
},
{
"role": "user",
"content": PROMPT,
},
]
# Format the conversation
# WARNING: HF's handling of chat's on Llava models is very fragile. This specific combination of processor.apply_chat_template(), and processor() works
# but if using other combinations always inspect the final input_ids to ensure they are correct. Often times you will end up with multiple <bos> tokens
# if not careful, which can make the model perform poorly.
convo_string = processor.apply_chat_template(
convo, tokenize=False, add_generation_prompt=True
)
assert isinstance(convo_string, str)
# Process the inputs
inputs = processor(text=[convo_string], images=[image], return_tensors="pt").to(
"cuda"
)
inputs["pixel_values"] = inputs["pixel_values"].to(torch.float16)
# Generate the captions
generate_ids = llava_model.generate(
**inputs,
max_new_tokens=300,
do_sample=True,
suppress_tokens=None,
use_cache=True,
temperature=0.6,
top_k=None,
top_p=0.9,
)[0]
# Trim off the prompt
generate_ids = generate_ids[inputs["input_ids"].shape[1] :]
# Decode the caption
caption = processor.tokenizer.decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
caption = caption.strip()
print(caption)
end_time = time.time()
total_time = end_time - start_time
print(f"Total execution time: {total_time:.2f} seconds")
This image is a humorous meme featuring a close-up of actor Tom Cruise in a scene from the movie "Minority Report." The photograph shows Cruise with a serious expression, looking to his right, and holding a cigarette between his fingers. The background is dimly lit, adding a dramatic ambiance to the scene. Overlaid on the image in bold white text are the words: "One does not simply walk after leg day." This meme is a playful twist on a famous quote from J.R.R. Tolkien's "The Lord of the Rings," which originally reads: "One does not simply walk into Mordor." The meme humorously applies the phrase to the concept of working out, specifically after a leg day at the gym, implying that the effort required is as daunting as the perilous journey into Mordor. The juxtaposition of Cruise's intense look with the humorous text adds to the comedic effect. The meme uses a combination of cultural references and wordplay to create a humorous and relatable commentary on the challenges of physical fitness. Total execution time: 177.48 secondsl
5.7 两个量化版本
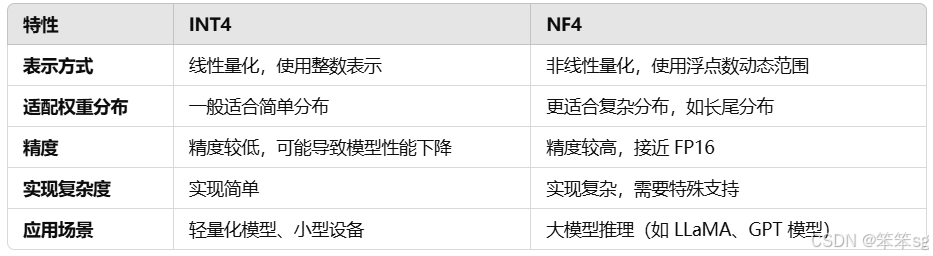
INT4:
OPEA/llama-joycaption-alpha-two-hf-llava-int4-sym-inc · Hugging Face
NF4:
John6666/llama-joycaption-alpha-two-hf-llava-nf4 at main
Example script for generating captions using joycaption with 4bit quantization
目前关于JoyCaption的量化问题也正在Github上的一个Issue中讨论:
How to run with BNB 4bit or 8bit quantization? · Issue #3 · fpgaminer/joycaption
5.8 使用VLLM
vLLM为JoyCaption提供了最高性能的推理,并提供了一个与OpenAI兼容的API,使得JoyCaption可以像其他VLM一样使用。示例用法:
vllm serve fancyfeast/llama-joycaption-alpha-two-hf-llava --max-model-len 4096 --enable-prefix-caching
vLLM对内存要求较高,因此你可能需要根据你的环境调整设置,比如强制启用急切模式、调整max-model-len、调整gpu_memory_utilization等。”
6 什么是vLLM?
可以先去看7.1,等看到7.5再回头看这个~~~
6.1 简介
VLLM(即“vLLaMA”)其实就是一种优化的框架,专门用来加速和提高大语言模型(比如GPT、BERT等)的推理效率。简单来说,它让这些庞大的模型在推理时更快,占用的内存更少。这样,处理大量数据时,能够更高效地进行操作,适用于需要快速响应和大量计算的场景。
想象一下,如果你有一个超级智能的大模型,但它在实际应用中太慢或吃掉太多内存,VLLM就是让这个大模型更轻便、更快速的工具。
vLLM 是一个快速且易于使用的库,专为大型语言模型 (LLM) 的推理和部署而设计。
vLLM 的核心特性包括:
-
最先进的服务吞吐量
-
使用 PagedAttention 高效管理注意力键和值的内存
-
连续批处理传入请求
-
使用 CUDA/HIP 图实现快速执行模型
-
优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成
-
推测性解码
-
分块预填充
vLLM 的灵活性和易用性体现在以下方面:
-
无缝集成流行的 HuggingFace 模型
-
具有高吞吐量服务以及各种解码算法,包括并行采样、束搜索等
-
支持张量并行和流水线并行的分布式推理
-
流式输出
-
提供与 OpenAI 兼容的 API 服务器
-
支持 NVIDIA GPU、AMD CPU 和 GPU、Intel CPU 和 GPU、PowerPC CPU、TPU 以及 AWS Neuron
-
前缀缓存支持
-
支持多 LoRA
6.2 说明文档
说明文档(ZN):欢迎来到 vLLM! | vLLM 中文站
说明文档(EN):Welcome to vLLM — vLLM
7 MiniCPM-o-2_6
技术原理说明文档:MiniCPM-o 2.6: 端侧可用的 GPT-4o 级视觉、语音、实时流式多模态大模型
7.1 什么是MiniCPM-o?
Github链接:MiniCPM-o/README_zh.md at main · OpenBMB/MiniCPM-o
MiniCPM-o 是从 MiniCPM-V 升级的最新端侧多模态大模型系列。该系列模型可以以端到端方式,接受图像、视频、文本、音频作为输入,并生成高质量文本和语音输出。自2024年2月以来,我们以实现高性能和高效部署为目标,发布了6个版本的模型。目前系列中最值得关注的模型包括:
-
MiniCPM-o 2.6: 🔥🔥🔥 MiniCPM-o 系列的最新、性能最佳模型。总参数量 8B,视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别,是开源社区中模态支持最丰富、性能最佳的模型之一。在新的语音模式中,MiniCPM-o 2.6 支持可配置声音的中英双语语音对话,还具备情感/语速/风格控制、端到端声音克隆、角色扮演等进阶能力。模型也进一步提升了 MiniCPM-V 2.6 的 OCR、可信行为、多语言支持和视频理解等视觉能力。基于其领先的视觉 token 密度,MiniCPM-V 2.6 成为了首个支持在 iPad 等端侧设备上进行多模态实时流式交互的多模态大模型。
-
MiniCPM-V 2.6: MiniCPM-V 系列中性能最佳的模型。总参数量 8B,单图、多图和视频理解性能超越了 GPT-4V。它取得了优于 GPT-4o mini、Gemini 1.5 Pro 和 Claude 3.5 Sonnet等的单图理解表现,并成为了首个支持在 iPad 等端侧设备上进行实时视频理解的多模态大模型。
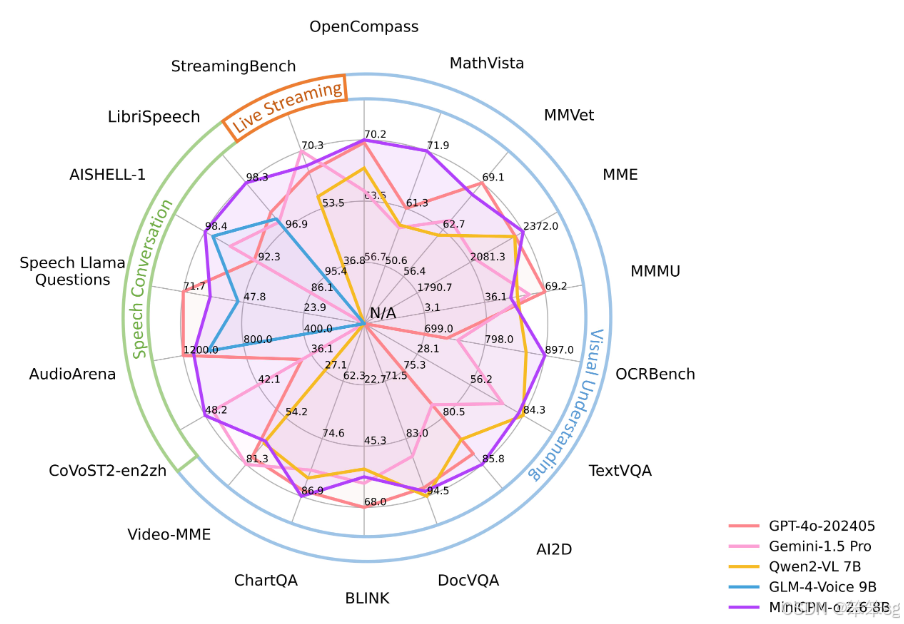
简单来说,MiniCPM-o 比GPT更强大,主要体现在它对多种模态的支持、语音能力的提升以及在移动设备上出色的实时处理能力。
7.2 一些Demo


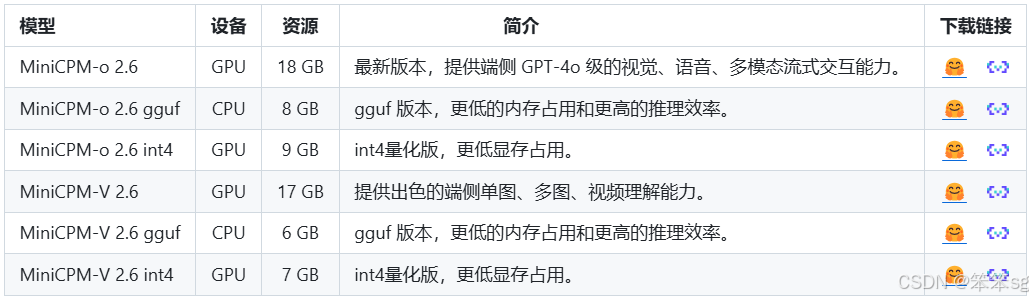
7.3 模型库
7.4 推理(多轮对话)
配置好环境后即可执行该demo:

import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True)
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)你可以得到如下推理结果:
"The landform in the picture is a mountain range. The mountains appear to be karst formations, characterized by their steep, rugged peaks and smooth, rounded shapes. These types of mountains are often found in regions with limestone bedrock and are shaped by processes such as erosion and weathering. The reflection of the mountains in the water adds to the scenic beauty of the landscape."
"When traveling to this scenic location, it's important to pay attention to the weather conditions, as the area appears to be prone to fog and mist, especially during sunrise or sunset. Additionally, ensure you have proper footwear for navigating the potentially slippery terrain around the water. Lastly, respect the natural environment by not disturbing the local flora and fauna."但是,通过这个demo进行推理,获取每张图片的Caption需要花费不少时间,那么有没有一种更高效的方式能够支持大规模图片的快速推理呢?有的有的,兄弟。
7.5 基于 vLLM 的高效推理
vLLM 现已官方支持MiniCPM-o 2.6、MiniCPM-V 2.6、MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.0。
链接:MiniCPM-o/README_zh.md at main · OpenBMB/MiniCPM-o
7.5.1 单个样本
# SPDX-License-Identifier: Apache-2.0
"""
This example shows how to use vLLM for running offline inference with
the correct prompt format on vision language models for text generation.
For most models, the prompt format should follow corresponding examples
on HuggingFace model repository.
"""
import random
import time
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
from vllm.assets.image import ImageAsset
from vllm.assets.video import VideoAsset
from vllm.utils import FlexibleArgumentParser
# MiniCPM-V
def run_minicpmv_base(question: str, modality: str, model_name):
assert modality in ["image", "video"]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
max_model_len=4096,
max_num_seqs=2,
trust_remote_code=True,
)
stop_tokens = ["<|im_end|>", "<|endoftext|>"]
stop_token_ids = [tokenizer.convert_tokens_to_ids(i) for i in stop_tokens]
modality_placeholder = {
"image": "(<image>./</image>)",
"video": "(<video>./</video>)",
}
messages = [
{"role": "user", "content": f"{modality_placeholder[modality]}\n{question}"}
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
return llm, prompt, stop_token_ids
def run_minicpmo(question: str, modality: str):
return run_minicpmv_base(question, modality, "openbmb/MiniCPM-o-2_6")
def run_minicpmv(question: str, modality: str):
return run_minicpmv_base(question, modality, "openbmb/MiniCPM-V-2_6")
model_example_map = {
"minicpmo": run_minicpmo,
"minicpmv": run_minicpmv,
}
def get_multi_modal_input(args):
if args.modality == "image":
image = ImageAsset("cherry_blossom").pil_image.convert("RGB")
img_question = "What is the content of this image?"
return {
"data": image,
"question": img_question,
}
if args.modality == "video":
video = VideoAsset(
name="sample_demo_1.mp4", num_frames=args.num_frames
).np_ndarrays
vid_question = "Why is this video funny?"
return {
"data": video,
"question": vid_question,
}
msg = f"Modality {args.modality} is not supported."
raise ValueError(msg)
def apply_image_repeat(image_repeat_prob, num_prompts, data, prompt, modality):
assert image_repeat_prob <= 1.0 and image_repeat_prob >= 0
no_yes = [0, 1]
probs = [1.0 - image_repeat_prob, image_repeat_prob]
inputs = []
cur_image = data
for i in range(num_prompts):
if image_repeat_prob is not None:
res = random.choices(no_yes, probs)[0]
if res == 0:
cur_image = cur_image.copy()
new_val = (i // 256 // 256, i // 256, i % 256)
cur_image.putpixel((0, 0), new_val)
inputs.append({"prompt": prompt, "multi_modal_data": {modality: cur_image}})
return inputs
def main(args):
model = args.model_type
if model not in model_example_map:
raise ValueError(f"Model type {model} is not supported.")
modality = args.modality
mm_input = get_multi_modal_input(args)
data = mm_input["data"]
question = mm_input["question"]
llm, prompt, stop_token_ids = model_example_map[model](question, modality)
sampling_params = SamplingParams(
temperature=0.2, max_tokens=64, stop_token_ids=stop_token_ids
)
assert args.num_prompts > 0
if args.num_prompts == 1:
inputs = {
"prompt": prompt,
"multi_modal_data": {modality: data},
}
else:
if args.image_repeat_prob is not None:
inputs = apply_image_repeat(
args.image_repeat_prob, args.num_prompts, data, prompt, modality
)
else:
inputs = [
{
"prompt": prompt,
"multi_modal_data": {modality: data},
}
for _ in range(args.num_prompts)
]
# Measure inference time for image or video
start_time = time.time()
outputs = llm.generate(inputs, sampling_params=sampling_params)
elapsed_time = time.time() - start_time
print("-- Inference time = {:.2f} seconds".format(elapsed_time))
for o in outputs:
generated_text = o.outputs[0].text
print(generated_text)
if __name__ == "__main__":
parser = FlexibleArgumentParser(
description="Demo on using vLLM for offline inference with "
"vision language models for text generation"
)
parser.add_argument(
"--model-type",
"-m",
type=str,
default="llava",
choices=model_example_map.keys(),
help='Huggingface "model_type".',
)
parser.add_argument(
"--num-prompts", type=int, default=4, help="Number of prompts to run."
)
parser.add_argument(
"--modality",
type=str,
default="image",
choices=["image", "video"],
help="Modality of the input.",
)
parser.add_argument(
"--num-frames",
type=int,
default=16,
help="Number of frames to extract from the video.",
)
parser.add_argument(
"--image-repeat-prob",
type=float,
default=None,
help="Simulates the hit-ratio for multi-modal preprocessor cache"
" (if enabled)",
)
parser.add_argument(
"--disable-mm-preprocessor-cache",
action="store_true",
help="If True, disables caching of multi-modal preprocessor/mapper.",
)
parser.add_argument(
"--time-generate",
action="store_true",
help="If True, then print the total generate() call time",
)
args = parser.parse_args()
main(args)
7.5.2 批处理
import os
import json
import time
from typing import List, Dict, Any
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
from vllm.assets.image import ImageAsset
from vllm.utils import FlexibleArgumentParser
from PIL import Image
def run_minicpmo_base(question: str, modality: str, model_name: str) -> tuple:
assert modality in ["image", "video", "audio"]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
max_model_len=4096,
max_num_seqs=2,
trust_remote_code=True,
)
stop_tokens = ["<|im_end|>", "<|endoftext|>"]
stop_token_ids = [tokenizer.convert_tokens_to_ids(token) for token in stop_tokens]
modality_placeholder = {
"image": "(<image>./</image>)",
"video": "(<video>./</video>)",
"audio": "(<audio>./</audio>)",
}
messages = [
{"role": "user", "content": f"{modality_placeholder[modality]}\n{question}"}
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
return llm, prompt, stop_token_ids
def run_minicpmo(question: str, modality: str) -> tuple:
model_name = "openbmb/MiniCPM-o-2_6"
return run_minicpmo_base(question, modality, model_name)
model_example_map = {
"minicpmo": run_minicpmo,
}
def get_images_from_folder(folder_path: str) -> List[str]:
if not os.path.exists(folder_path):
raise FileNotFoundError(f"文件夹 {folder_path} 不存在。")
image_extensions = {".jpg", ".jpeg", ".png", ".bmp"}
image_paths = []
for filename in os.listdir(folder_path):
file_ext = os.path.splitext(filename)[1].lower()
if file_ext in image_extensions:
image_paths.append(os.path.join(folder_path, filename))
return image_paths
def get_images_from_folder(folder: str) -> List[str]:
"""
获取文件夹中所有图片路径。
"""
supported_extensions = (".jpg", ".jpeg", ".png", ".bmp")
return [
os.path.join(folder, f)
for f in os.listdir(folder)
if f.lower().endswith(supported_extensions)
]
def process_images_in_folder(
image_folder: str,
question: str,
model_type: str,
num_prompts: int = 1,
image_repeat_prob: float = None,
batch_size: int = 16,
) -> List[Dict[str, str]]:
"""
处理文件夹中的图片,对每张图片生成描述。
"""
image_paths = get_images_from_folder(image_folder)
print(f"加载了 {len(image_paths)} 张图片。")
modality = "image"
llm, prompt, stop_token_ids = model_example_map[model_type](question, modality)
all_results = []
total_time = 0.0
for i in range(0, len(image_paths), batch_size):
batch_paths = image_paths[i : i + batch_size]
inputs = []
for img_path in batch_paths:
try:
# 使用 Pillow 加载图片
image = Image.open(img_path).convert("RGB")
input_data = {"prompt": prompt, "multi_modal_data": {"image": image}}
inputs.append(input_data)
except Exception as e:
print(f"加载图片 {img_path} 失败:{str(e)}")
continue
if not inputs:
continue
start_time = time.time()
try:
outputs = llm.generate(
inputs,
sampling_params=SamplingParams(
temperature=0.2, max_tokens=350, stop_token_ids=stop_token_ids
),
)
batch_time = time.time() - start_time
total_time += batch_time
avg_time = batch_time / len(outputs)
print(
f"批次处理 {len(inputs)} 张图片,耗时 {batch_time:.2f} 秒,平均每张 {avg_time:.2f} 秒"
)
for img_path, output in zip(batch_paths, outputs):
img_filename = os.path.splitext(os.path.basename(img_path))[0]
caption = output.outputs[0].text
all_results.append({"id": img_filename, "caption": caption})
except Exception as e:
print(f"批次处理失败:{str(e)}")
average_total_time = total_time / len(image_paths) if image_paths else 0
print(
f"所有图片处理完成,总耗时 {total_time:.2f} 秒,平均每张 {average_total_time:.2f} 秒"
)
return all_results
def save_results_to_json(results: List[Dict[str, str]], output_file: str) -> None:
with open(output_file, "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
def main():
parser = FlexibleArgumentParser(
description="Batch caption inference for thousands of images using vLLM and MiniCPM-o 2.6"
)
parser.add_argument(
"--image-folder",
"-img",
type=str,
# required=True,
default="autodl-tmp/temp_data",
help="Folder containing the images for captioning.",
)
parser.add_argument(
"--question",
"-q",
type=str,
default="Please describe the picture and try to analyze its deeper meaning, if it exists:",
help="The question to ask for captioning.",
)
parser.add_argument(
"--model-type",
"-m",
type=str,
default="minicpmo",
choices=model_example_map.keys(),
help="Model type to use for captioning.",
)
parser.add_argument(
"--num-prompts",
type=int,
default=1,
help="Number of prompts to run for each image.",
)
parser.add_argument(
"--image-repeat-prob",
type=float,
default=None,
help="Probability for repeating images to simulate cache hit/miss.",
)
parser.add_argument(
"--batch-size",
"-b",
type=int,
default=16,
help="Number of images to process in each batch.",
)
parser.add_argument(
"--output-json",
"-o",
type=str,
default="captions.json",
help="Output JSON file path.",
)
args = parser.parse_args()
print("开始处理图片...")
results = process_images_in_folder(
args.image_folder,
args.question,
args.model_type,
args.num_prompts,
args.image_repeat_prob,
args.batch_size,
)
print(f"保存结果到 {args.output_json}...")
save_results_to_json(results, args.output_json)
print("完成!")
if __name__ == "__main__":
main()
7.5.3 注意事项
1)vLLM会占用较大的内存空间,所以请确保使用的机器系统空间较大。
2)vLLM的版本(>=0.7.1)。
3)如果使用本地路径的模型,请确保模型代码已更新到Hugging Face上的最新版(注意是HF上,不是Github)
当你执行时遇见报错"AttributeError: 'MiniCPMOProcessor' object has no attribute 'get_audio_placeholder'",参见下面这个解决方案:
7.6 详细了解MiniCPM系列
【端侧GPT-4o】MiniCPM-o 2.6 - 飞书云文档
8 其他开源工具
在上文,我们介绍了BLIP2、JoyCaption以及MiniCPM-o-2.6。如果你仍然没找到心怡的开源工具,可以考虑以下这些:
8.1 LLaVA:
LLaVA 是一个视觉指令调优模型,旨在达到 GPT-4V 级别的能力甚至超越。它通过结合大型语言模型和视觉模型,能够理解和生成与图像相关的自然语言响应。
在线体验: LLaVA - a Hugging Face Space by badayvedat
8.2 LLaVA-NeXT:
LLaVA-NeXT 是 LLaVA 的后续版本,在性能、模型架构或数据集上进行了改进,以进一步提升多模态任务的表现。
8.3 xGen-MM (BLIP-3):
xGen-MM 是 Salesforce 的 LAVIS 项目的一部分,专注于多模态学习。BLIP-3 是一个视觉-语言预训练模型,能够处理图像和文本的联合任务。
8.4 lmdeploy:
lmdeploy 是一个用于压缩、部署和服务大型语言模型(LLMs)的工具包。它旨在帮助开发者更高效地部署和管理大规模语言模型。
InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.
8.5 InternVL:
InternVL 是一个开源的多模态对话模型,旨在接近 GPT-4o 的表现。它是 CVPR 2024 的口头报告项目,提供了 GPT-4o 的开源替代方案。
8.6 Qwen2-VL
Qwen2-VL 是阿里巴巴云 Qwen 团队开发的多模态大语言模型系列之一,专注于视觉-语言任务。
8.7 Qwen2.5-VL
Qwen2.5-VL 是 Qwen2-VL 的升级版本,可能在模型架构、训练数据或性能上进行了优化,以提升多模态任务的表现。
8.8 CogVLM
CogVLM 是一个最先进的开源视觉语言模型之一,专注于多模态预训练,能够处理图像和文本的联合任务。
THUDM/CogVLM: a state-of-the-art-level open visual language model | 多模态预训练模型
8.9 Florence-2
Florence-2 是微软开发的一个大规模视觉-语言模型,专注于多模态任务。它在模型规模、训练数据或任务多样性上进行了扩展。
microsoft/Florence-2-large · Hugging Face
8.10 MiniGPT-4
最近的 GPT-4 展现了卓越的多模态能力,例如可以直接根据手写文字生成网站、识别图像中的幽默元素。这些特性在之前的视觉-语言模型中是极为罕见的。我们认为,GPT-4 之所以具备如此先进的多模态生成能力,主要原因在于其使用了更强大的大型语言模型(LLM)。为了验证这一现象,我们提出了 MiniGPT-4:它通过仅使用一层投影层,将一个冻结的视觉编码器与一个冻结的大语言模型 Vicuna 对齐。我们的实验表明,MiniGPT-4 拥有许多类似于 GPT-4 的能力,例如生成详细的图像描述、根据手写草图创建网站。此外,我们还观察到 MiniGPT-4 表现出其他新兴能力,包括根据图像创作故事和诗歌、基于图像内容提供问题解决方案、根据食物照片指导用户烹饪等。
在实验过程中,我们发现如果仅在原始图文对数据上进行预训练,模型容易生成不自然、连贯性差的语言输出,例如出现重复和片段化句子的问题。为了解决这一问题,我们在第二阶段精心筛选了一套高质量、对齐良好的数据集,并采用对话模板对模型进行微调。这一步骤对于提升模型生成的可靠性和整体可用性起到了关键作用。值得注意的是,我们的模型在计算上非常高效,因为我们仅训练了一个投影层,并利用了大约 500 万条对齐的图文对数据。
Vision-CAIR/MiniGPT-4: Open-sourced codes for MiniGPT-4 and MiniGPT-v2


















 2582
2582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









