







最近在刷抖音时,发现这种电影人物唱歌视频比较火热,今天手把手教大家如何制作这种让电影人物唱歌的视频!
一、素材准备
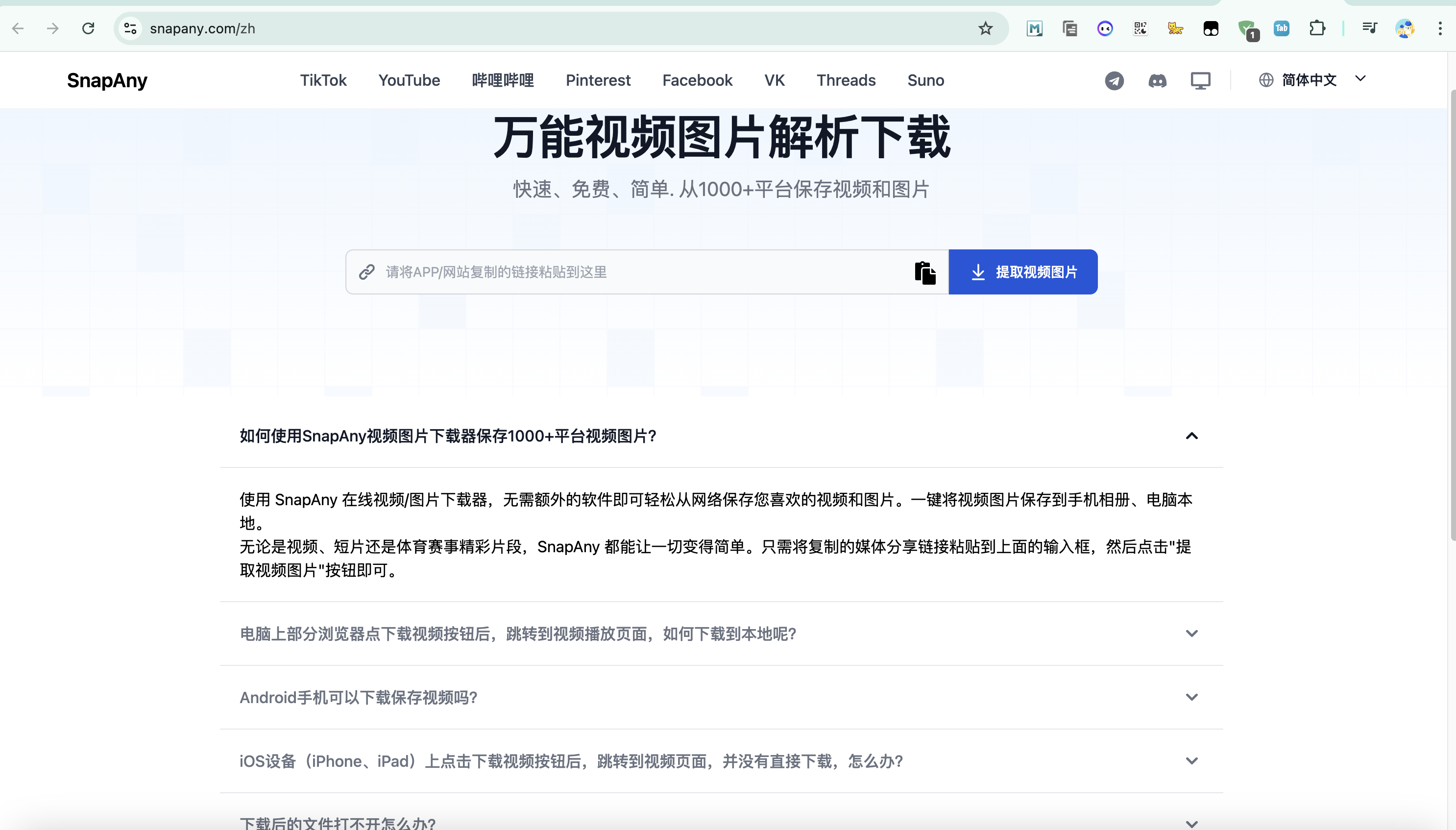
1、准备好视频或人物图片素材
这里需要准备一张人物截图或者电影视频片段,大家可以去各大视频网站找原始素材,再对链接进行视频提取,不知道如何提取链接的可以到如下地址,复制视频地址即可快速提取!
2、准备音频素材
这里我们去剪映APP上找MP3音频素材,里面有很多娱乐音乐素材,而且可以快速截取所需的音频片段,大家可以按截图进行搜索
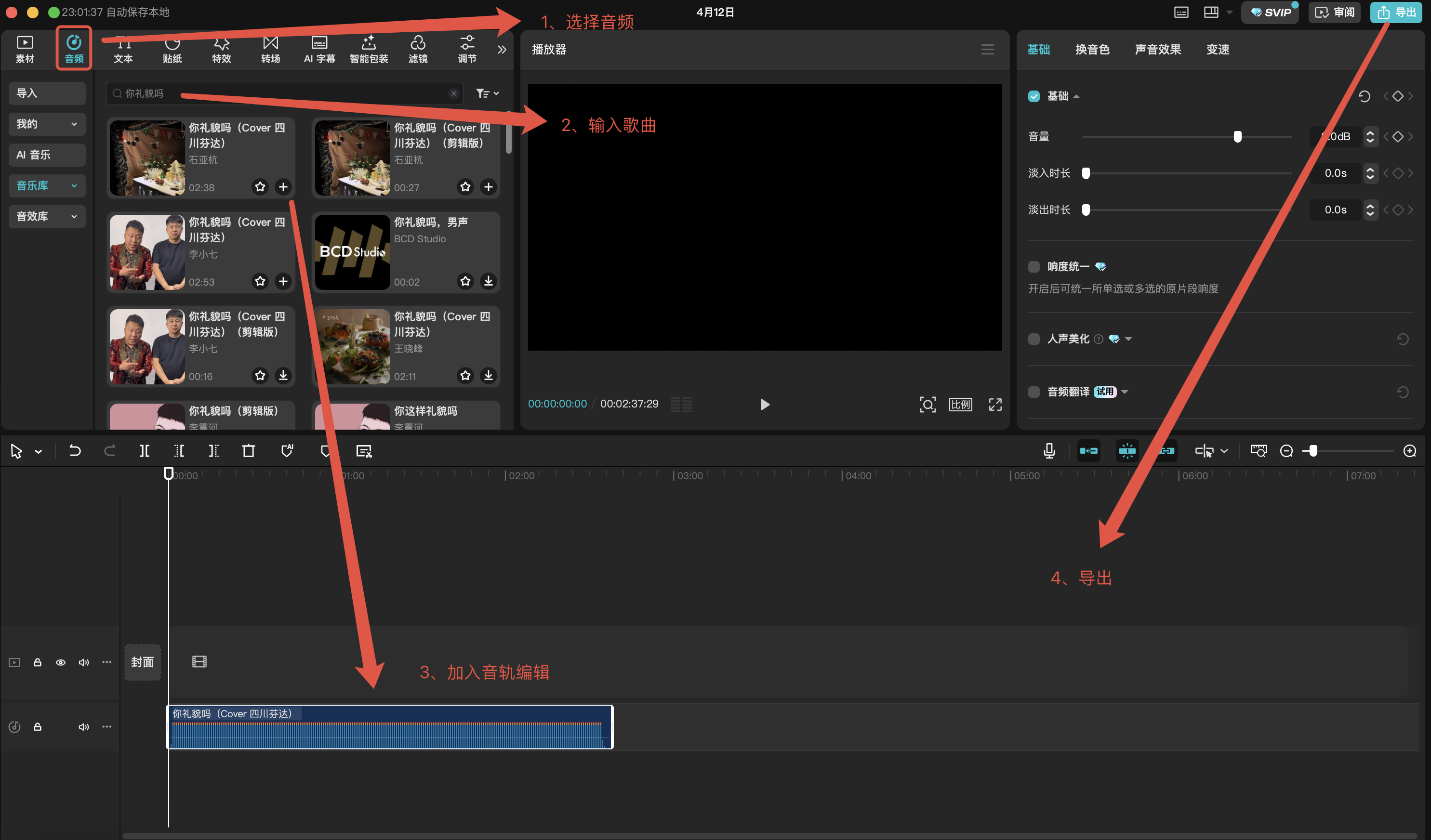
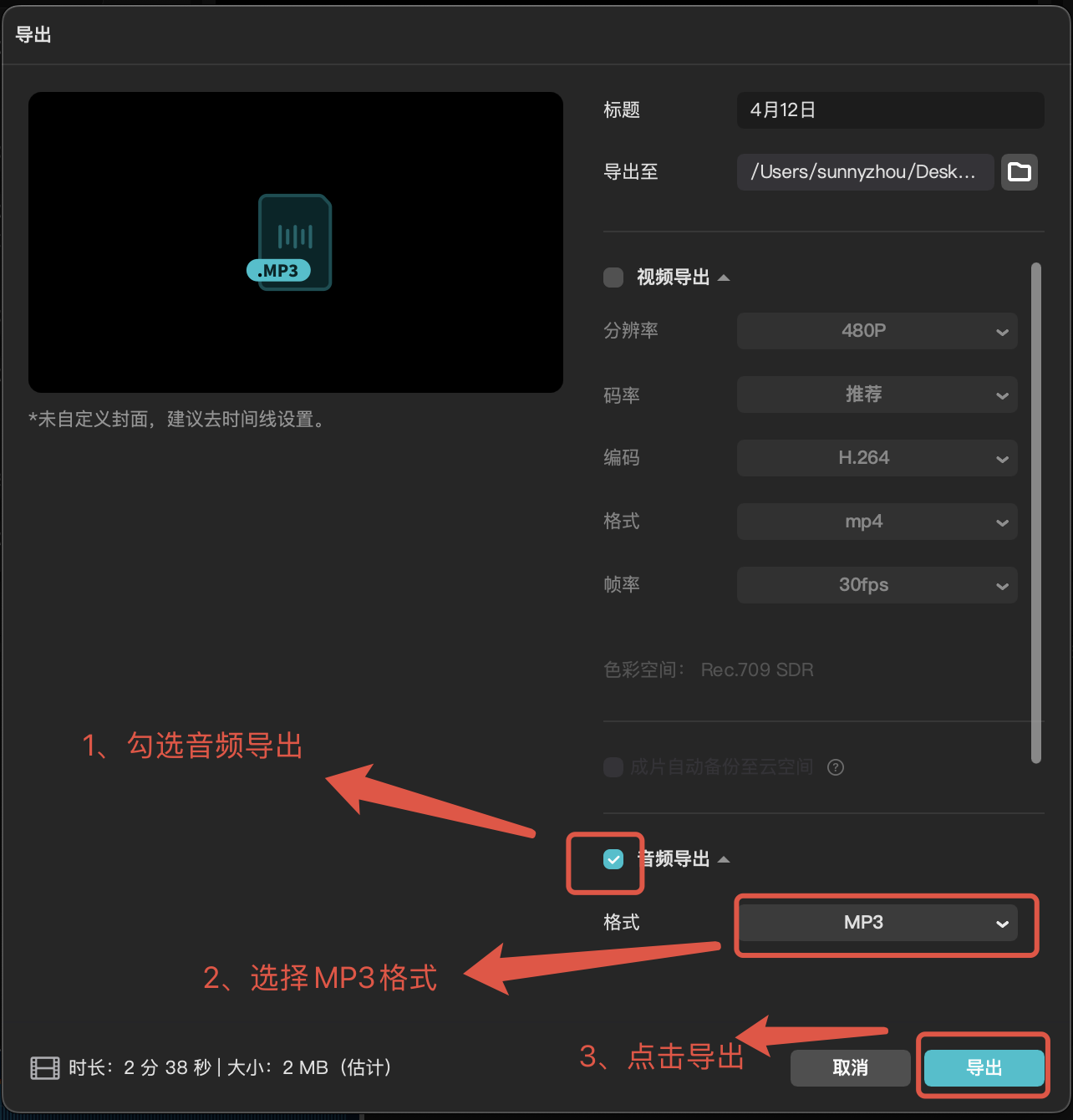
点击导出后,选择MP3格式,
二、使用即梦AI生成数字人唱歌视频
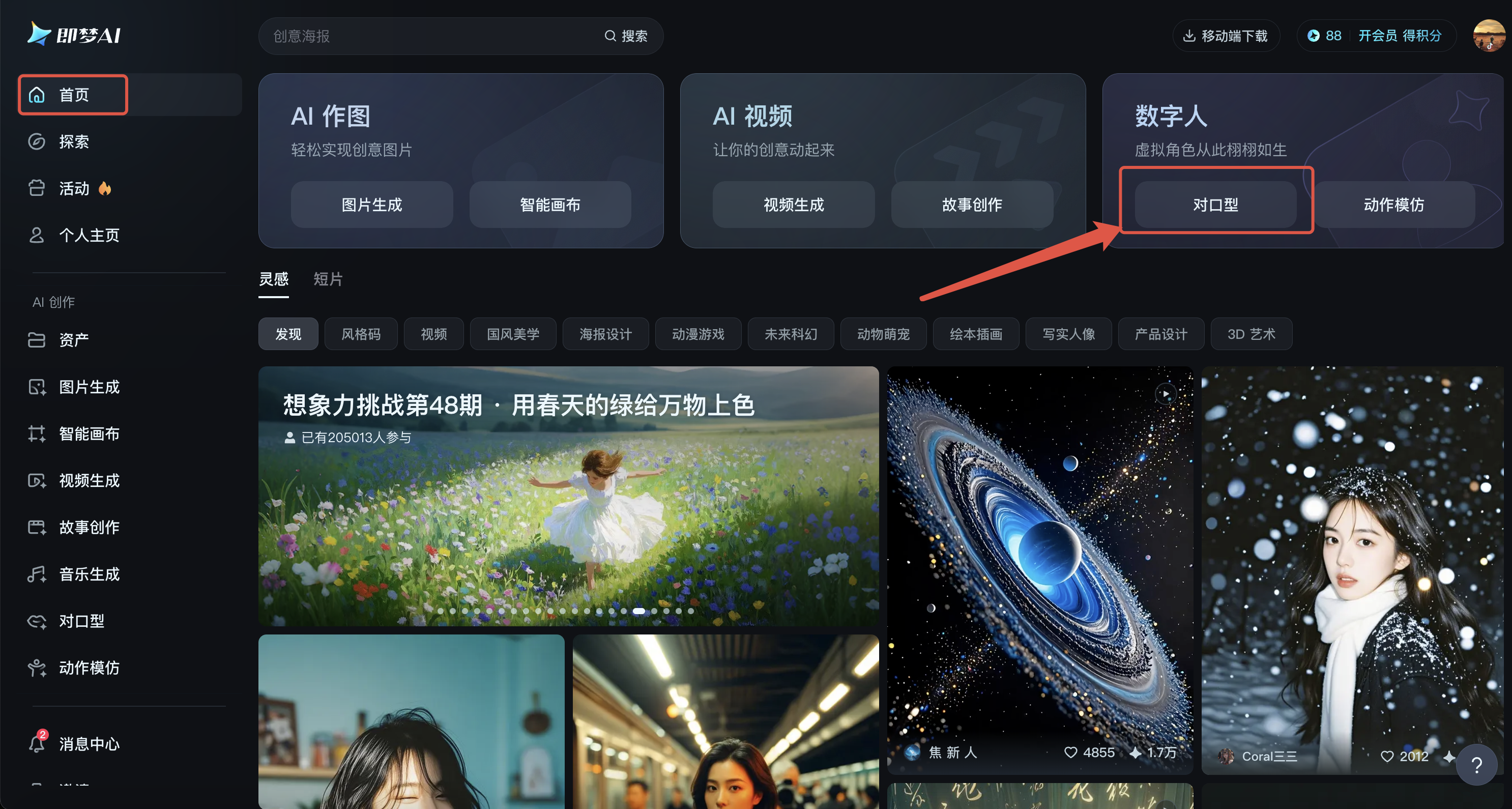
1、进入数字人对口型功能
打开即梦AI:即梦AI - 即刻造梦,进到首页后,点击对口型
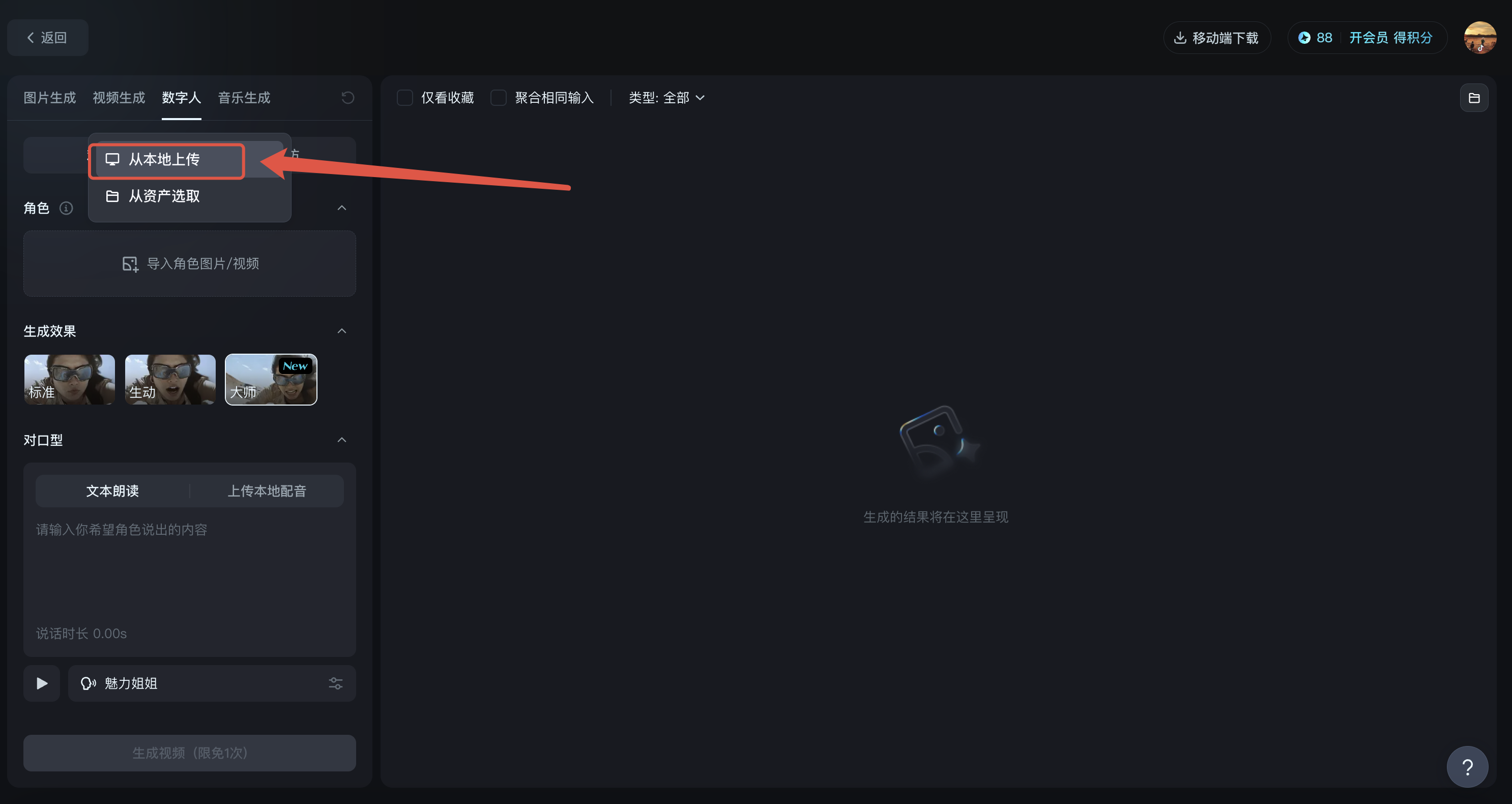
2、上传需要对口型的视频
打开后界面如下,点击导入视频->从本地上传,选择从各视频平台下载剪辑的短片
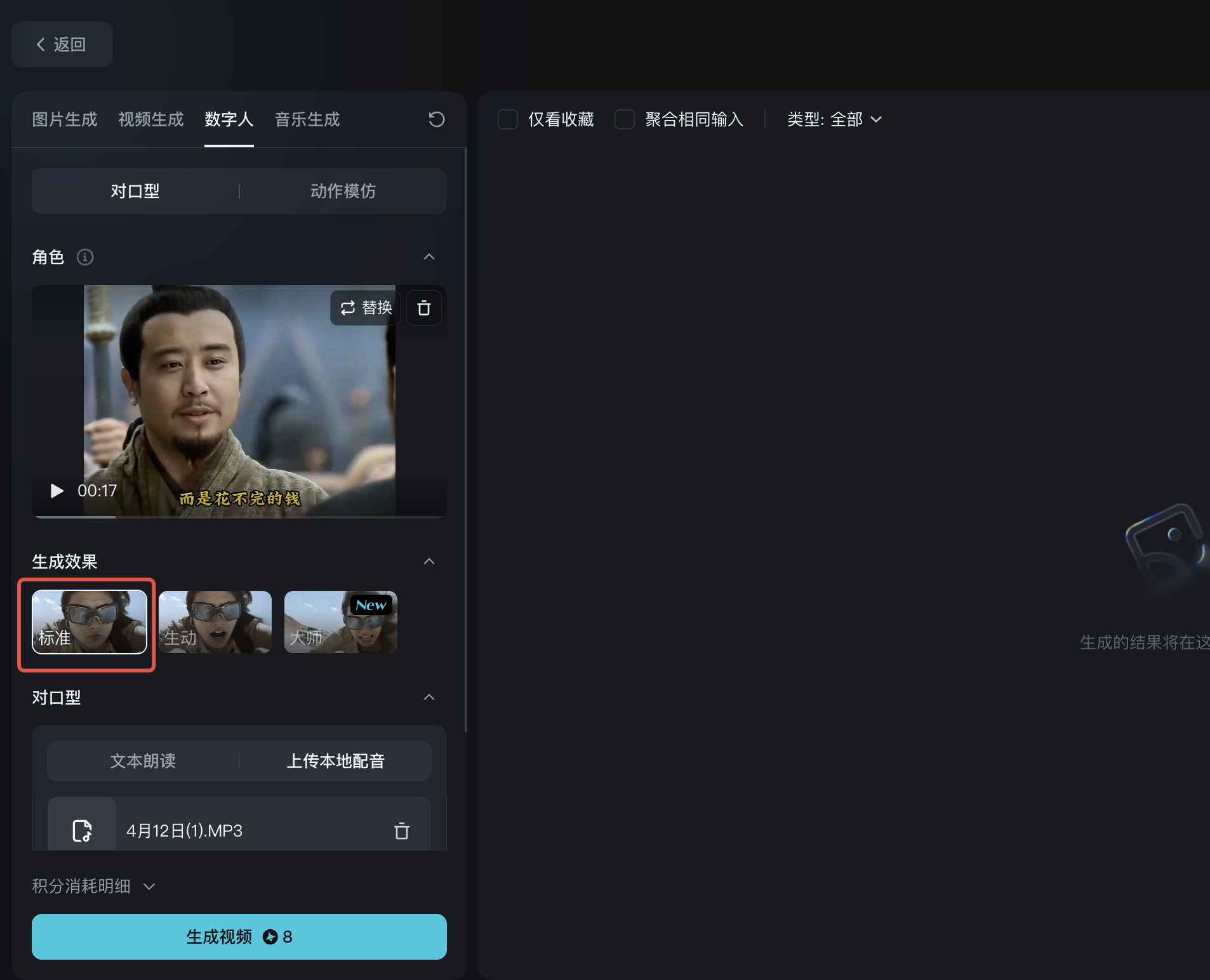
3、选择生成效果
这里生成效果有三种模式:标准、生动、大师!这里我们选择标准效果即可,这三种生成效果区别如下:
- 标准:仅修改口型,比较适合演讲、对白。
- 生动:更丰富的面部动作,比较适合唱歌、表演。但是可能会被裁剪。在生动模式下,无论上传什么比例的图片,视频都会被裁剪成 1:1 的大头视频。
- 大师:可以生成超逼真的「全身动作」和「背景动效」,不被裁剪,且支持多人对口型。但是大师模式的缺点是,暂时还不支持生成动物角色的对口型视频。(标准和生动模式是支持动物角色的)
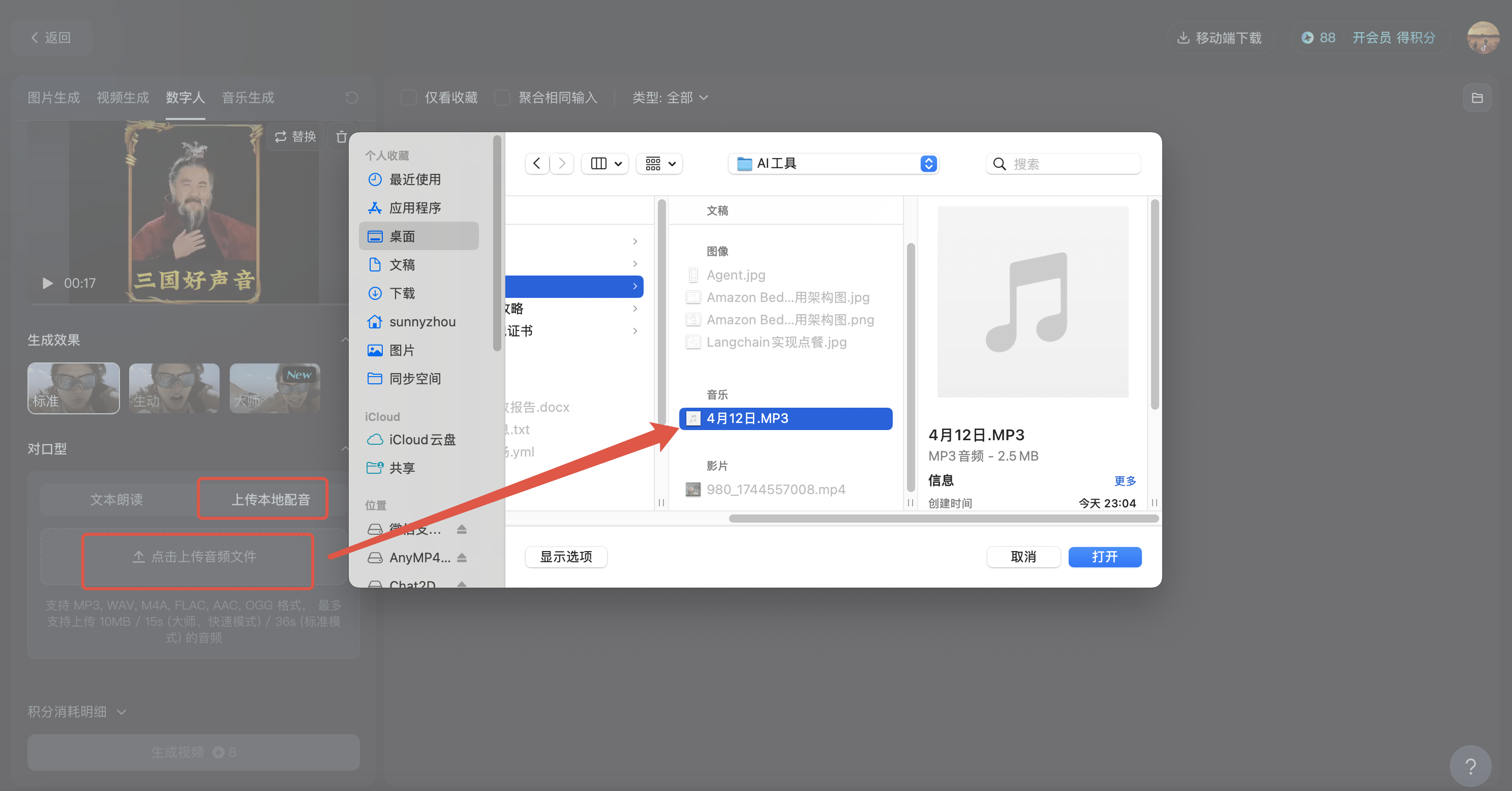
4、上传本地配音
选择上传本地配音,点击上传音频文件(注意:这里音频文件不能超过36秒,如果超了可以使用剪映剪辑下,挑选精华音频时段)
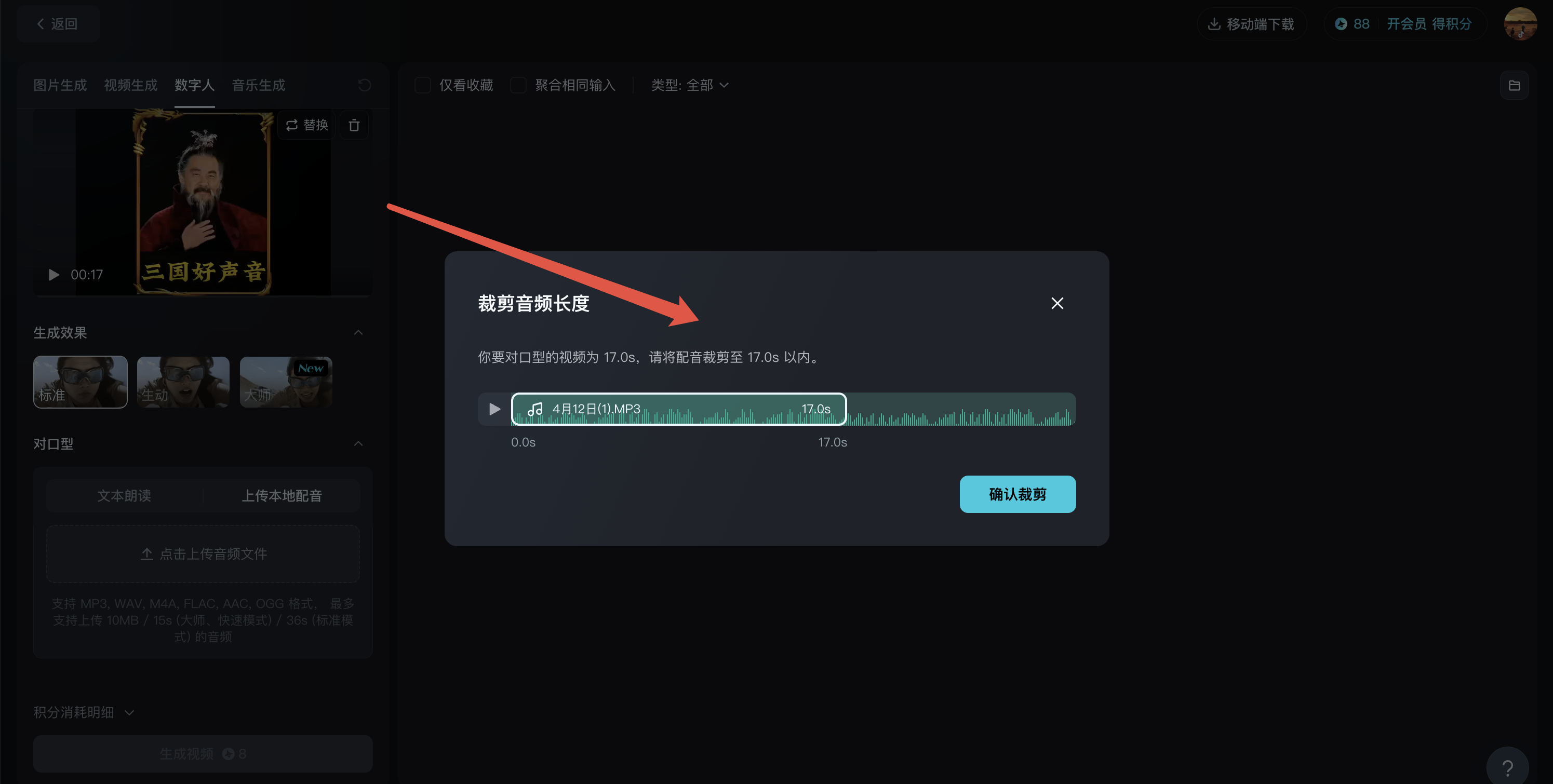
5、确认音频裁剪起始位置
上传完音频后,系统会自动检测视频时长,选择需要的音频起始段,直接点击确认裁剪即可
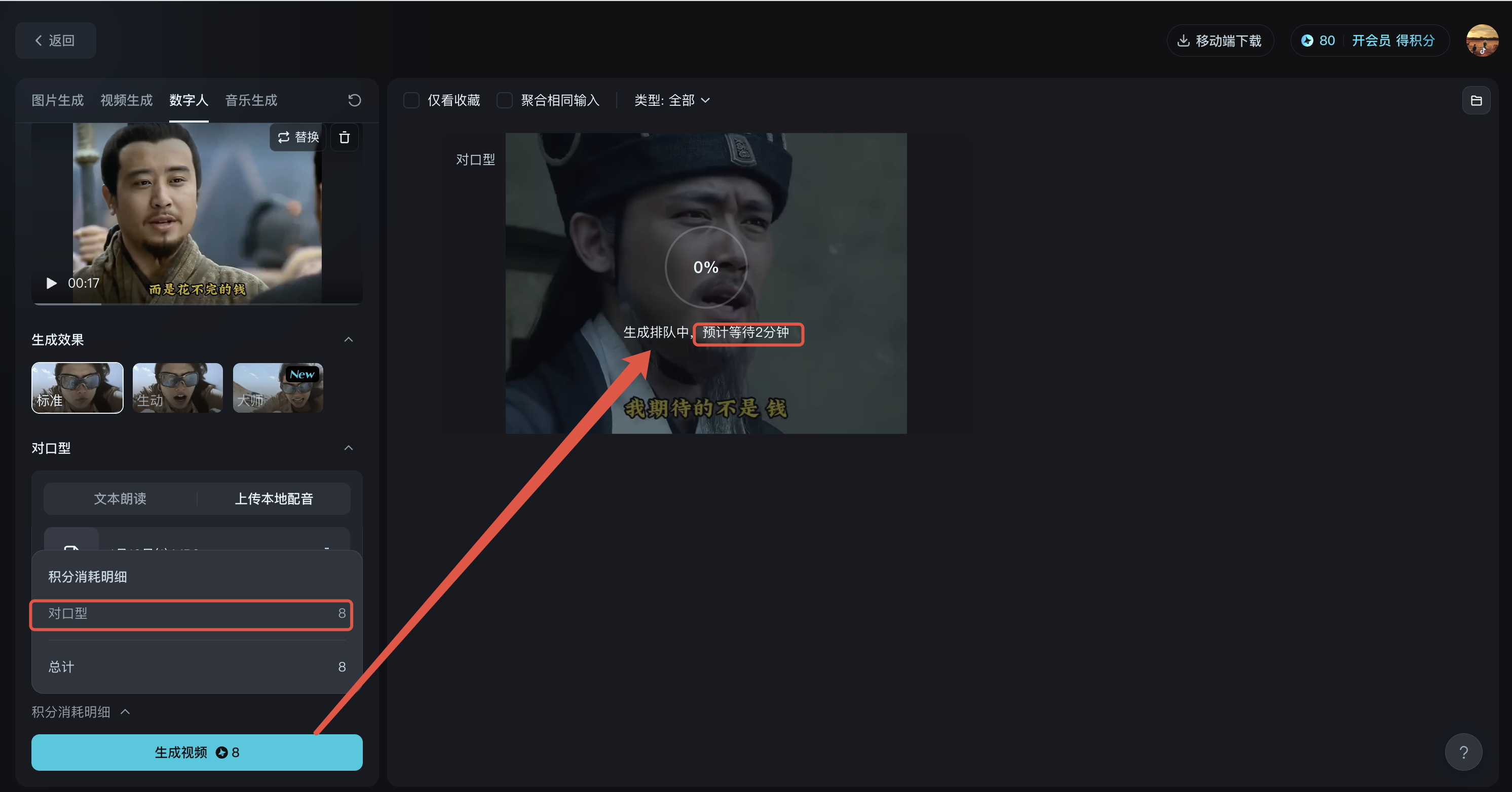
6、生成视频
点击生成视频,预计2分钟左右便可生成对口型视频了!目前每次对口型消耗8点积分,每天登录会自动赠送88点积分(该赠送积分不会累加,赠送积分会在24小时内自动过期),不过基本上也可以满足日常娱乐需求了!
总结
通过以上步骤,您可以轻松制作出电影人物唱歌的视频。记得选择合适的音频和视频,使用正版素材,避免侵权。希望这篇教程能帮助您制作出精彩的视频,享受创作的乐趣!


















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











