






浏览器组成
- 用户界面(User Interface) 菜单 工具栏 后退千金按钮 书签目录 也就是能看到的除了显示页面的主窗口外的部分
- 浏览器引擎(Browser engine) 用来查询及操作渲染引擎的接口
- 渲染引擎(Rendering engine)用来显示请求的内容
- 网络部分(Networking)用户网络掉哟经 例如HTTP请求 其接口与平台无关 并为所有平台提供底层实现
- JS解释器(JavaScript Interpreter) 主要负责处理JavaScript脚本程序 一般会附带在浏览器中 录入chrome的V8引擎
- UI后端(UI Backend) 用于回执基本的窗口组件 比如组合框和窗口
- 数据存储(Data Persistence) 保存类似于cookie storange等数据部分 HTML5 HTML5新增了web database技术,一种完整的轻量级客户存储技术。
https://kb.cnblogs.com/page/129756/
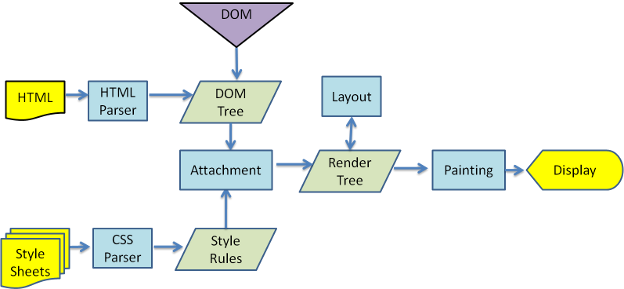
渲染引擎
在浏览器窗口中显示请求的内容
渲染主流程

- 通过网络请求文档内容
- 取得内容渲染
- 解析html构建dom树
- 基于css样式 与style样式构建render树(包含 颜色 大小等属性)
- 布局render树 确定每个节点在屏幕上的确切坐标
- 绘制render树 遍历render树 并使用UI后端底层绘制每个节点
解析与Dom树构建
解析
将一个文档转换成具有一定意义(指编码可以理解和使用的东西)的结构
解析的结果通常是表达文档结构的节点树
语法
解析基于文档依据语法规则 文档的语言和格式
解析器-词法分析器
解析分为 语法分析 以及词法分析两个过程
词法分析 将输入分解为符号
语法分析 对于语言应用语法规则
解析器一般将工作 分配给 分词器 与解析器 从而构建解析树
转换
即系一般在转换中使用 即将文档转换成另外一个格式 例如编译
解析器类型
- 自上而下解析器
- 自下而上解析器
我们来认识一些名词
- 自动化解析 可以自动生成解析器的工具
- HTML解析器 将html解析为解析树
- HTML文法定义 W3C组织规定了HTML词汇表和语法
- 非上下文无关文法 类似BNF格式的语法
DTD (document tyoe definition 文档类型定义)
详见 http://www.w3.org/TR/html4/strict.dtd
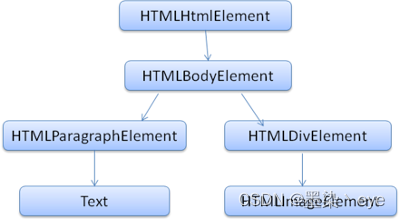
DOM
输出的树 也就是解析树 有DOM节点以及属性节点组成
作为html的外部接口供js等调用
<html>
<body>
<p>
Hello DOM
</p>
<div><img src=”example.png” /></div>
</body>
</html>
会转换为
解析算法
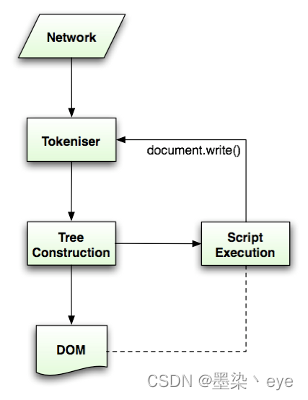
符号识别器识别出符号后 将其传递给构建器 并读取下一个符号 直处理完所有输入
with open file as f:
line=f.readline
send(line)
符号识别算法
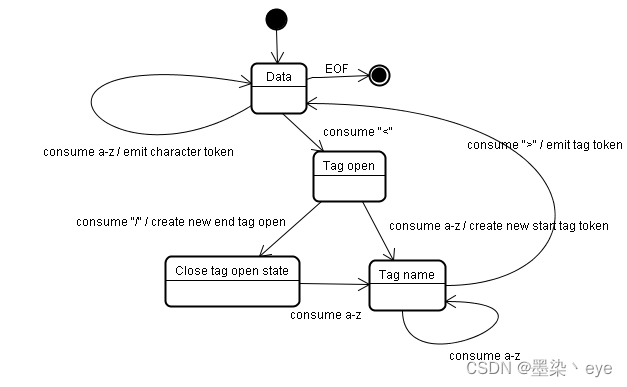
树的构建算法
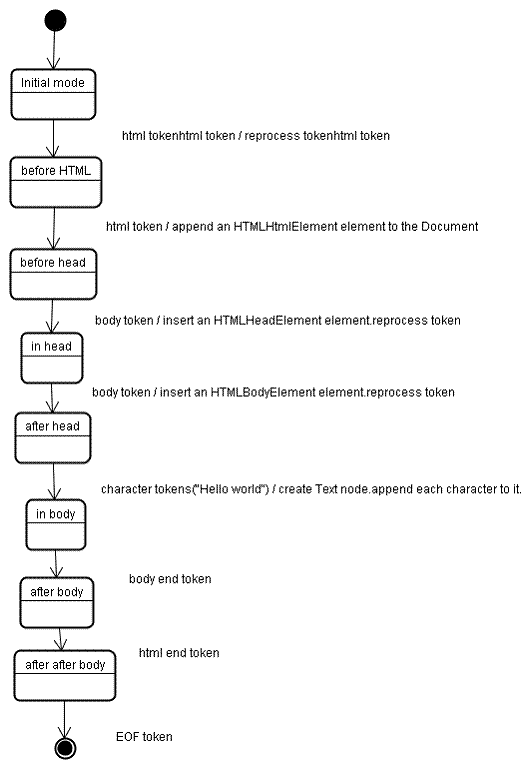
解析结束的处理
在这个阶段 浏览器将文档记为可交互的 并开始解析处于延时模式中的脚本(解析完成后执行)
文档状态被设置完成后 触发一个load事件
详情见
http://www.w3.org/TR/html5/syntax.html#html-parser
CSS解析器
Css属于上下文无关文法
comment///*[^*]*/*+([^/*][^*]*/*+)*//
num[0-9]+|[0-9]*"."[0-9]+
nonascii[/200-/377]
nmstart[_a-z]|{nonascii}|{escape}
nmchar[_a-z0-9-]|{nonascii}|{escape}
name{nmchar}+
ident{nmstart}{nmchar}*
“ident”是识别器的缩写,相当于一个class名,“name”是一个元素id(用“#”引用)。
巴科斯范式
BNF 规定是推导规则(产生式)的集合,写为:
< > : 内包含的为必选项
[ ] : 内包含的为可选项
{ } : 内包含的为可重复0至无数次的项
| : 表示在其左右两边任选一项,相当于"OR"的意思
::= : 是“被定义为”的意思 ,也可以替换为:=(本文使用::=)
"..." : 在双引号中的字("word")代表着这些字符本身 ,而double_quote用来代表双引号
( ) : 分组
斜体字: 参数,在其它地方有解释
这些选择器以逗号和空格(S表示空格)进行分隔。每个规则集合包含大括号及大括号中的一条或多条以分号隔开的声明。声明和选择器在后面进行定义。
原文链接:https://blog.csdn.net/taidaohualang/article/details/93624507
CSS语法
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
说明:一个规则集合有这样的结构
div.error , a.error {
color:red;
font-weight:bold;
}
div.error和a.error时选择器,大括号中的内容包含了这条规则集合中的规则,这个结构在下面的定义中正式的定义了:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
处理脚本及样式表的顺序
脚本
-
web的模式是同步的
-
解析到一个script标签时立即解析执行脚本 并阻塞文档
-
外引脚本 网络必须现请求到这个资源 会阻塞脚本直到资源被请求到
-
脚本标识成defer 不会阻塞文档解析
预解析
当执行脚本时,另一个线程解析剩下的文档,并加载后面需要通过网络加载的资源
预解析并不改变Dom树,它将这个工作留给主解析过程,自己只解析外部资源的引用,比如外部脚本、样式表及图片。
样式表
样式表不改变Dom树 不用停下文档的解析等待
如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题,这看起来是个边缘情况,但确实很常见。Firefox在存在样式表还在加载和解析时阻塞所有的脚本,而Chrome只在当脚本试图访问某些可能被未加载的样式表所影响的特定的样式属性时才阻塞这些脚本。















 2206
2206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









