




 Apache Storm是一款开源的分布式实时计算系统,能够处理无限的数据流并进行实时分析。Storm通过Topology组织Spout和Bolt组件,前者负责获取数据,后者进行数据处理。Storm支持多种编程语言,并提供丰富的数据分组策略。
Apache Storm是一款开源的分布式实时计算系统,能够处理无限的数据流并进行实时分析。Storm通过Topology组织Spout和Bolt组件,前者负责获取数据,后者进行数据处理。Storm支持多种编程语言,并提供丰富的数据分组策略。
官网: http://storm.apache.org/
Apache Storm是一个免费的开源分布式实时计算系统。Storm可以很容易地可靠地处理无限的数据流,从而实时处理Hadoop为批处理所做的事情。Storm很简单,可以和任何编程语言一起使用
Storm编程模型
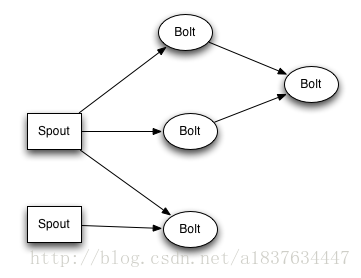
- 其中Spout 一条一条从数据源获取外部数据
- Spout 在内部发送Tuple给Bolt ; Bolt 根据业务进行处理
- Bolt 可以发送Tuple给另一个Bolt 进行业务处理
- Bolt 可以多线程处理同一个业务步骤(Bolt可以有多个处理同一个业务)
- Bolt 最后将结果保存到数据库(redis?)
- Bolt 可以接受多个Spout 发送过来的数据(一个Storm 程序可以获取多个数据源)
类似在Hadoop中 以上过程叫MapReduce
在Storm 中 叫 Topology(拓扑)
* Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
* Spout:在一个topology中获取源数据流的组件。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
* Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
* Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
* Stream:表示数据的流向。
Storm核心组件
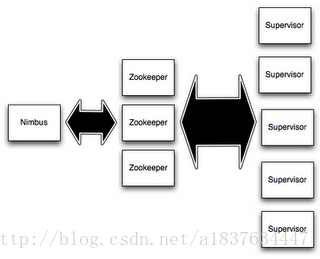
Supervisor中有多个Worker,每个Worker中运行着Spout任务或Bolt任务。
- Nimbus:负责资源分配和任务调度。
- Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。—通过配置文件设置当前supervisor上启动多少个worker。
- Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
- Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
Stream Grouping 数据分组策略
hadoop 中 默认实现 HashGrouping(hashCode%num)
Storm里面有7种主要类型的stream grouping
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。(random.nexInt(2))
- Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。(hashcode%num)
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。(先发本地,避免网络传输)


















 1971
1971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









