







Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了内存内运算技术,能在数据尚未写入硬盘时即在内存内分析运算。Spark在内存内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。[1]Spark允许用户将数据加载至集群内存,并多次对其进行查询,非常适合用于机器学习算法。
https://zh.wikipedia.org/wiki/Apache_Spark
下载
Spark官网:
https://spark.apache.org/
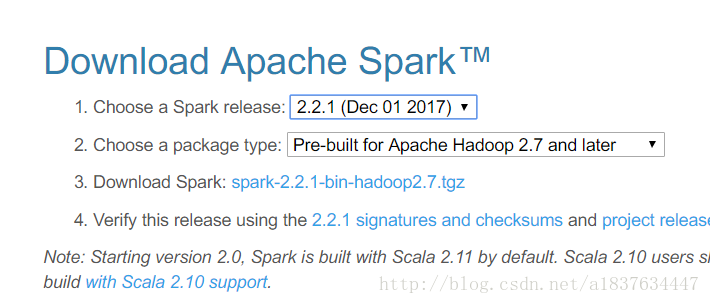
找到download按钮,目前最新版本2.21 下载即可
下载后是一个文件扩展名为 .tgz 的压缩包
将其放入linux 系统中,解压tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz -C /home/ning/app/
安装配置
1.进入 conf 文件夹,并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vi spark-env.sh2.修改spark-env.sh文件中的内容
export JAVA_HOME=/home/ning/app/jdk1.8.0_152
export SPARK_MASTER_IP=node1
export SPARK_MASTER_PORT=7077分别将JAVA_HOME路径,MASTER所在机器及端口进行配置
修改完毕后保存退出
3.重命名并修改slaves.template文件
node2
node3这个文件中放的是子节点所在的位置(Worker节点)
修改完毕后保存退出
4. 在master节点上启动spark
sbin/start-all.sh 启动之前:
将配置拷贝到其他节点
需要配置ssh 免密登陆
需要修改hosts 文件
启动
启动后执行jps命令
主节点上有Master进程
其他子节点上有Work进行
登录Spark管理界面查看集群状态(主节点):http://node1:8080/
蒙特·卡罗算法求PI
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 --executor-memory 1G --total-executor-cores 4 /home/ning/app/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar

Pi is roughly 3.145055725278626















 8217
8217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









