







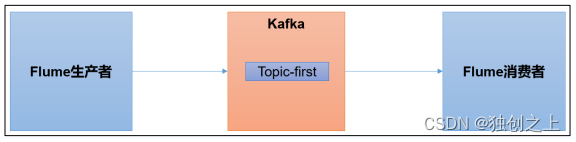
外部系统的集成,即通过不同的生产端或消费端来实现数据消费过程。
1、集成flume
flume是大数据开发者常用的组件,主要是高可用高可靠的日志系统,通过编写.conf文件来实现对日志文件的收集后转存到文件或hdfs集群的操作(离线日志文件)。可用于kafka的生产者,也可用于kafka的消费者。
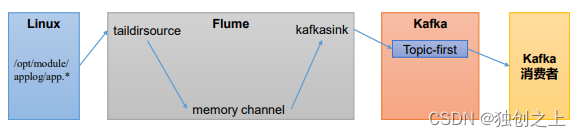
1)、flume作为生产端
前期准备:启动kafka集群和zookeeper
zk.sh start
kf.sh start
先启动kafka的消费者,便于接收flume生产端发送的数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
配置flume,设置数据来源,传输的方式。在 hadoop102 节点的 Flume 的 job 目录下创建 file_to_kafka.conf
1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/app.*
a1.sources.r1.positionFile =
/opt/module/flume/taildir_position.json
# 3 配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4 配置 sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:&表示在后台运行
bin/flume-ng agent -c conf/ -n a1 -f jobs/file_to_kafka.conf &
然后向/opt/module/applog/app.log 里追加数据,查看 kafka 消费者消费情况
mkdir applog
echo hello >> /opt/module/applog/app.log
可以在kafka消费端查看hello数据。
2)、flume作为消费者(接收kafka数据)
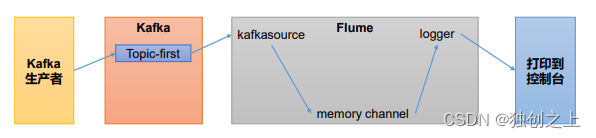
配置flume:在 hadoop102 节点的 Flume 的/opt/module/flume/jobs 目录下创建 kafka_to_file.conf
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 50
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092
a1.sources.r1.kafka.topics = first
a1.sources.r1.kafka. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











