






核密度估计(Kernel Density Estimation, KDE)是一种非参数方法,用于估计随机变量的概率密度函数。在区间预测中,核密度估计可以用来估计预测值的概率分布,进而确定预测值的置信区间。以下是核密度估计区间预测的原理和步骤的详细介绍。
| 代码获取戳此:KDE核密度估计区间预测(matlab) |
原理
核密度估计的基本原理是,通过每个数据点周围的核函数(Kernel Function)进行平滑处理,从而得到连续的概率密度估计结果。这里的核函数是一个非负函数,且在整个定义域上的积分为1。常用的核函数包括高斯核、均匀核和三角核等。
具体来说,对于给定的数据集X=x1,x2,...,xn,核密度估计通过以下方式计算任意点x处的概率密度:
fh(x)=nh1∑i=1nK(hx−xi)
其中,K(⋅)是核函数,h是带宽(Bandwidth),也称为平滑参数,用于控制核函数的宽度。带宽的选择对估计结果的精度有重要影响。如果带宽过大,则估计结果过于平滑,可能忽略数据的局部特征;如果带宽过小,则估计结果可能过于粗糙,受到噪声数据的影响较大。
步骤
核密度估计区间预测的步骤如下:
- 选择核函数:常用的核函数包括高斯核、均匀核和三角核等。其中,高斯核函数因其良好的平滑性和数学性质而广泛应用。
- 选择带宽:带宽是核密度估计中的一个重要参数,它决定了核函数的宽度。带宽的选择可以通过交叉验证、最大似然估计或启发式方法等方法来确定。一般来说,较小的带宽会使估计结果更加尖锐,而较大的带宽会使估计结果更加平滑。
- 计算核密度估计:对于每个数据点xi,计算其周围核函数的加权和,得到该点处的概率密度估计值。将所有数据点的概率密度估计值相加并除以数据点个数和带宽的乘积,即可得到整个数据集的概率密度估计函数。
- 确定预测区间:根据概率密度估计函数,可以确定预测值的置信区间。例如,可以计算预测值的累积分布函数(CDF),然后根据所需的置信水平(如95%)确定置信区间的上下限。
- 可视化结果:将计算得到的概率密度估计结果绘制成曲线图,可以更直观地理解数据的概率密度分布。同时,也可以将预测值的置信区间绘制在图上,以便更好地展示预测结果的不确定性。
% 获取训练集的预测结果和实际值
train_predicted_values = train_data(:, end-1)';
train_actual_values = train_data(:, 1)';
% 获取测试集的预测结果和实际值
test_predicted_values = test_data(:, end-1)';
test_actual_values = test_data(:, 1)';
% 计算训练集的误差
train_errors = train_actual_values - train_predicted_values;
% 训练核密度估计模型
n_train = length(train_errors);
std_dev_train = std(train_errors);
bandwidth_train = 3.5* std_dev_train * n_train^(-1/5);
[f_train, x_train] = ksdensity(train_errors, 'Kernel', 'normal', 'Bandwidth', bandwidth_train);
% 可视化估计的密度函数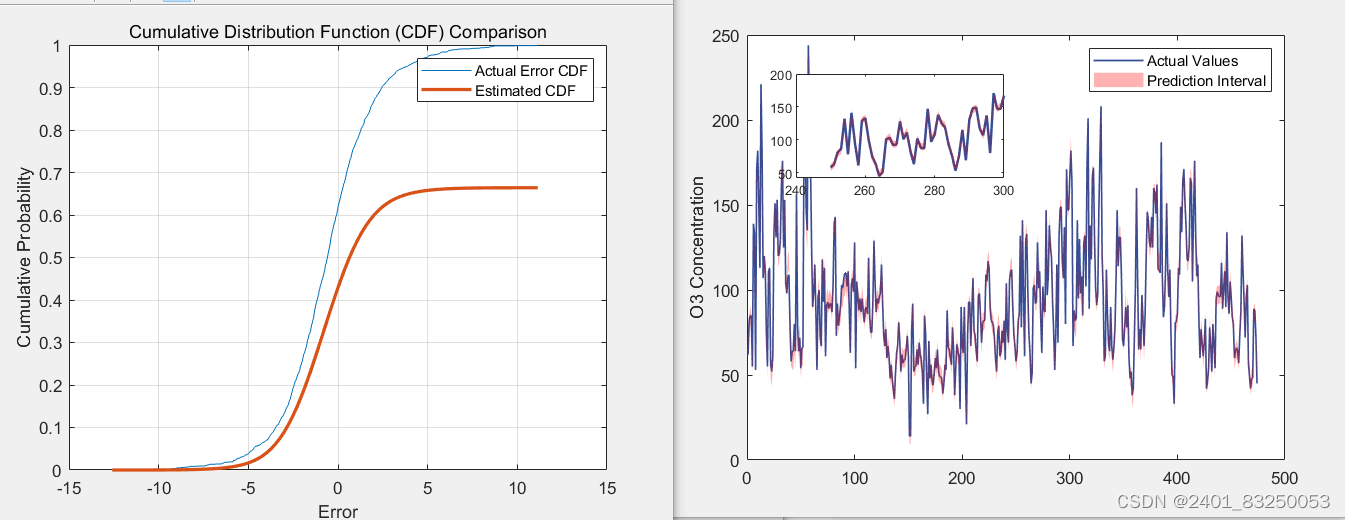















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









