






基于QRF(分位数随机森林)的随机森林分位数多变量回归区间预测模型结合了随机森林和分位数回归的概念,用于估计多个输入变量与单个输出变量之间的关系,并预测输出变量的分位数区间。以下是对其原理和步骤的详细介绍:
| 代码获取戳此:基于QRF随机森林分位数多变量回归区间预测模型 |
原理
- 随机森林:
- 随机森林是一种基于决策树的集成学习方法。它通过构建多个决策树(通常称为“树”),并对这些树的预测结果进行平均或投票来得到最终预测。
- 决策树的每个节点基于输入特征进行分割,以最小化目标变量的残差。通过组合多个这样的树,随机森林可以减少过拟合并提高预测精度。
- 分位数回归:
- 分位数回归是一种估计因变量条件分位数的统计方法。与经典的最小二乘法回归不同,分位数回归不假设因变量的分布是对称的或正态的,因此可以更灵活地处理具有异常值或偏态分布的数据。
- 分位数回归可以预测不同分位数水平(如0.25、0.5、0.75等)下的因变量值,从而提供关于因变量分布的全面信息。
- QRF(分位数随机森林):
- QRF结合了随机森林和分位数回归的思想。在QRF中,每个决策树不仅预测目标变量的均值,还预测其不同分位数水平下的值。
- 通过在随机森林的每个决策树上进行分位数回归,QRF可以生成一个关于目标变量分布的全面预测,而不仅仅是其均值。
步骤
- 数据准备:
- 收集包含多个输入变量和单个输出变量的数据集。
- 对数据进行必要的预处理,如缺失值填充、异常值处理、数据标准化或归一化等。
- 构建QRF模型:
- 设置随机森林的参数,如树的数量(即“森林”的大小)、每个树的最大深度、节点分裂时考虑的特征数量等。
- 选择要预测的分位数水平(如0.1、0.25、0.5、0.75、0.9等)。
- 初始化一个空的随机森林模型。
- 训练QRF模型:
- 对于数据集中的每个样本,使用自助法(bootstrap)进行有放回抽样,生成多个训练子集。
- 对于每个训练子集,构建一棵决策树。在树的每个节点上,基于输入特征进行分裂,以最小化目标变量在所选分位数水平下的残差。
- 重复上述过程,直到达到指定的树的数量或满足其他停止条件。
- 预测:
- 对于新的输入数据,将其传递给训练好的QRF模型。
- 每棵树都会基于其学习到的规则对输入数据进行预测,并给出目标变量在不同分位数水平下的预测值。
- 对所有树的预测结果进行平均或投票(取决于具体的集成策略),以得到最终的预测结果。
部分代码
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 转置以适应模型
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
%% 训练模型
qutile_size = [0.05, 0.95]; % 分位数范围
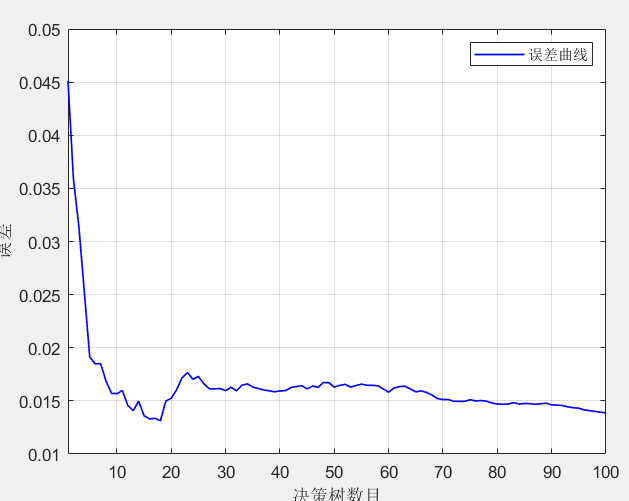
trees = 100; % 决策树数目
leaf = 1; % 最小叶子数
OOBPrediction = 'on'; % 打开误差图
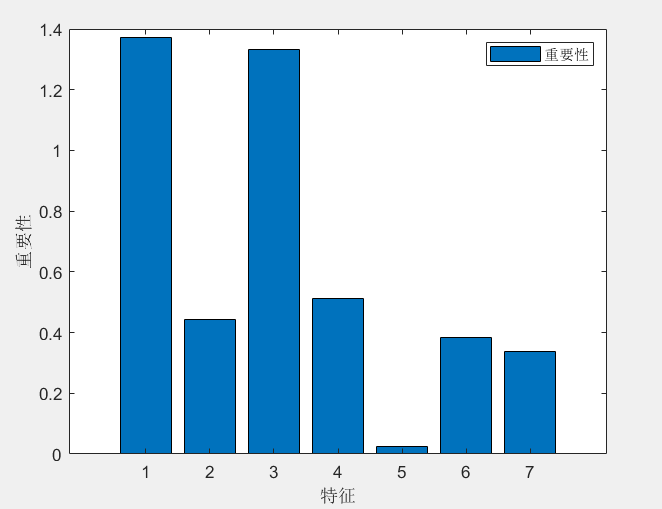
OOBPredictorImportance = 'on'; % 计算特征重要性
Method = 'regression'; % 分类还是回归
net = TreeBagger(trees, p_train, t_train, 'OOBPredictorImportance', OOBPredictorImportance,...
'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', leaf);
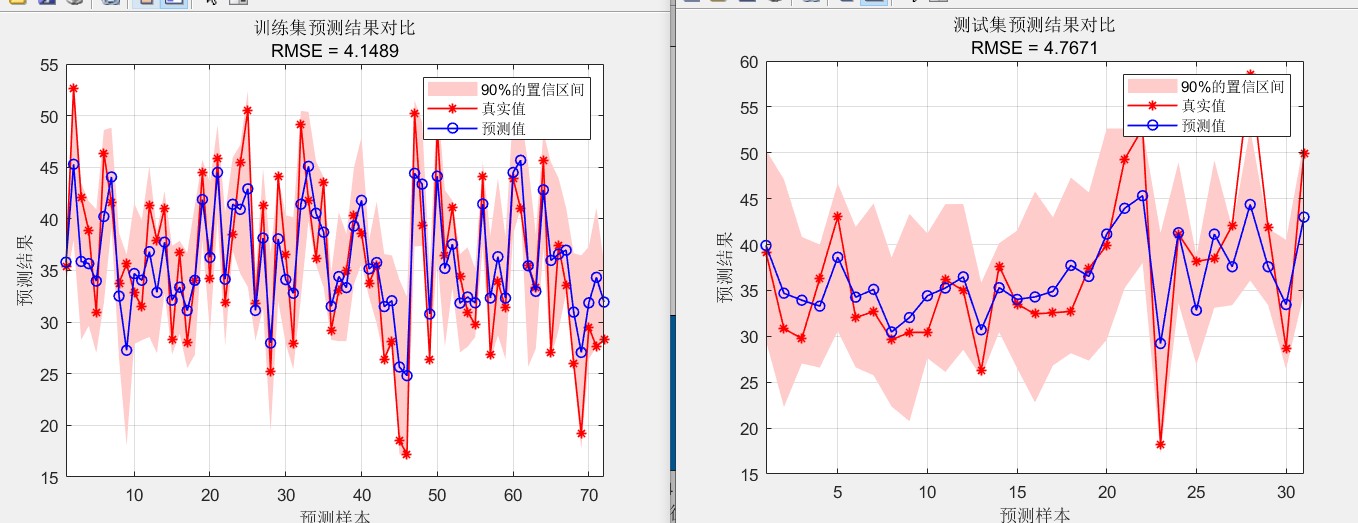
importance = net.OOBPermutedPredictorDeltaError; % 重要性评价指标包括: R2、MAE、MAPE、MSE和区间覆盖率和区间平均宽度百分比等,代码质量极高,方便学习和替换数据















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









