






一、 数据集制作
1.数据集分割
采集的格式是视频格式,首先进行分帧处理
# coding=utf-8
"""
原文地址:https://blog.csdn.net/bskfnvjtlyzmv867/article/details/79970146
"""
import os
import cv2
videos_src_path = "E:\dataset\Mydata\lwir\\" #视频路径
video_formats = [".MP4", ".MOV"] #视频格式
frames_save_path = "E:\dataset\Mydata\lwir\\" #分帧后图片保存地址
width = 1920
height = 1080 #大小
time_interval = 30 #视频分帧间隔时间
def video2frame(video_src_path, frame_save_path, frame_width, frame_height, interval):
"""
将视频按固定间隔读取写入图片
:param video_src_path: 视频存放路径
:param formats: 包含的所有视频格式
:param frame_save_path: 保存路径
:param frame_width: 保存帧宽
:param frame_height: 保存帧高
:param interval: 保存帧间隔
:return: 帧图片
"""
videos = os.listdir(video_src_path)
# def filter_format(x, all_formats):
# if x[-4:] in all_for
# mats:
# return True
# else:
# return False
#
# videos = filter(lambda x: filter_format(x, formats), videos)
for each_video in videos:
# print "正在读取视频:", each_video
print("正在读取视频:", each_video) # 我的是Python3.6
each_video_name = each_video[:-4]
os.mkdir(frame_save_path + each_video_name)
each_video_save_full_path = os.path.join(frame_save_path, each_video_name) + "/"
each_video_full_path = os.path.join(video_src_path, each_video)
cap = cv2.VideoCapture(each_video_full_path)
frame_index = 0
frame_count = 0
if cap.isOpened():
success = True
else:
success = False
print("读取失败!")
while(success):
success, frame = cap.read()
# print "---> 正在读取第%d帧:" % frame_index, success
print("---> 正在读取第%d帧:" % frame_index, success) # 我的是Python3.6
if frame_index % interval == 0 and success: # 如路径下有多个视频文件时视频最后一帧报错因此条件语句中加and success
resize_frame = cv2.resize(frame, (frame_width, frame_height), interpolation=cv2.INTER_AREA)
# cv2.imwrite(each_video_save_full_path + each_video_name + "_%d.jpg" % frame_index, resize_frame)
cv2.imwrite(each_video_save_full_path + "%d.jpg" % frame_count, resize_frame)
frame_count += 1
frame_index += 1
cap.release() # 这行要缩一下、原博客会报错
def main():
video2frame(videos_src_path, frames_save_path, width, height, time_interval)
if __name__ == '__main__':
main()
2.打标签
工具:labelme (我用的pycharm启动)
安装命令:pip install labelme
启动命令:labelme
标签跟原图片保存在同一个文件夹
3.标签格式转换
标签保存下来的格式是json文件,需要转换成掩码图片(本人转换为VOC数据集格式,这里的代码转换的跟VOC数据集不太一样,后面我自己手动改的)
这里我转换的时候遇到了一些问题 忘记了 后续想起来了再更新
这里生成四个文件夹
JPEGImages——原图像
SegmentationClassnpy——标签numpy格式
SegmentationClass——标签png格式(8位图,这里训练的标签要是8位彩图,扩充数据集的时候因为这个遇到好多问题,后续会讲到)
SegmentationClassVisualization——原图叠加标签
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main(args):
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassnpy"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClassnpy", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClass", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
label=lbl,
# img=imgviz.rgb2gray(img),
image=img,
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--input_dir", default="E:\Code\MY_Net_RGB\Mydata\\1-pic\\12-02\in_all\JSON", type=str,
help="input annotated directory") #保存JSON文件的路径
parser.add_argument("--output_dir", default="E:\Code\MY_Net_RGB\Mydata\\1-pic\\12-02\in_all\FINAL", type=str, help="output dataset directory") #最后输出的路径
parser.add_argument("--labels", default="E:\Code\MY_Net_RGB\Mydata\\1-pic\\12-02\in_all\class_names.txt", type=str, help="labels file") #保存类别名称的txt文件
parser.add_argument("--noviz", help="no visualization", action="store_true")
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)
4.VOC数据集格式制作
ImageSets——txt文件,保存的是训练和测试图片序号,利用代码生成
JPEGImages——原图像(jpg格式)
SegmentationClass——标签文件(png格式)
txt文件生成代码(这个代码没有划分出测试集,想修改代码,另分出测试集,目前都是手动划分,后期再修改)
import os
import random
import numpy as np
from PIL import Image
from tqdm import tqdm
#-------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# 修改train_percent用于改变验证集的比例 9:1
#
# 当前该库将测试集当作验证集使用,不单独划分测试集
#-------------------------------------------------------#
trainval_percent = 1
train_percent = 0.9
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'Mydata'
if __name__ == "__main__":
random.seed(0)
print("Generate txt in ImageSets.")
segfilepath = os.path.join(VOCdevkit_path, 'SODA/SegmentationClass')
saveBasePath = os.path.join(VOCdevkit_path, 'SODA/ImageSets')
temp_seg = os.listdir(segfilepath)
total_seg = []
for seg in temp_seg:
if seg.endswith(".png"):
total_seg.append(seg)
num = len(total_seg)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr)
print("train and val size",tv)
print("train size",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name = total_seg[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
print("Check datasets format, this may take a while.")
print("检查数据集格式是否符合要求,这可能需要一段时间。")
classes_nums = np.zeros([256], np.int)
for i in tqdm(list):
name = total_seg[i]
png_file_name = os.path.join(segfilepath, name)
if not os.path.exists(png_file_name):
raise ValueError("未检测到标签图片%s,请查看具体路径下文件是否存在以及后缀是否为png。"%(png_file_name))
png = np.array(Image.open(png_file_name), np.uint8)
if len(np.shape(png)) > 2:
print("标签图片%s的shape为%s,不属于灰度图或者八位彩图,请仔细检查数据集格式。"%(name, str(np.shape(png))))
print("标签图片需要为灰度图或者八位彩图,标签的每个像素点的值就是这个像素点所属的种类。"%(name, str(np.shape(png))))
classes_nums += np.bincount(np.reshape(png, [-1]), minlength=256)
print("打印像素点的值与数量。")
print('-' * 37)
print("| %15s | %15s |"%("Key", "Value"))
print('-' * 37)
for i in range(256):
if classes_nums[i] > 0:
print("| %15s | %15s |"%(str(i), str(classes_nums[i])))
print('-' * 37)
if classes_nums[255] > 0 and classes_nums[0] > 0 and np.sum(classes_nums[1:255]) == 0:
print("检测到标签中像素点的值仅包含0与255,数据格式有误。")
print("二分类问题需要将标签修改为背景的像素点值为0,目标的像素点值为1。")
elif classes_nums[0] > 0 and np.sum(classes_nums[1:]) == 0:
print("检测到标签中仅仅包含背景像素点,数据格式有误,请仔细检查数据集格式。")
print("JPEGImages中的图片应当为.jpg文件、SegmentationClass中的图片应当为.png文件。")
print("如果格式有误,参考:")
print("https://github.com/bubbliiiing/segmentation-format-fix")
二、开始训练
1.训练
https://github.com/bubbliiiing/deeplabv3-plus-pytorch #DeepLabV3+训练完整代码
训练自己的数据集修改一下这几个文件里的相关路径,训练类别以及其他相关参数
2.预测
修改predict.py文件里的预测权重,改为自己训练的权重,以及相关预测类别等
以下是我预测的结果
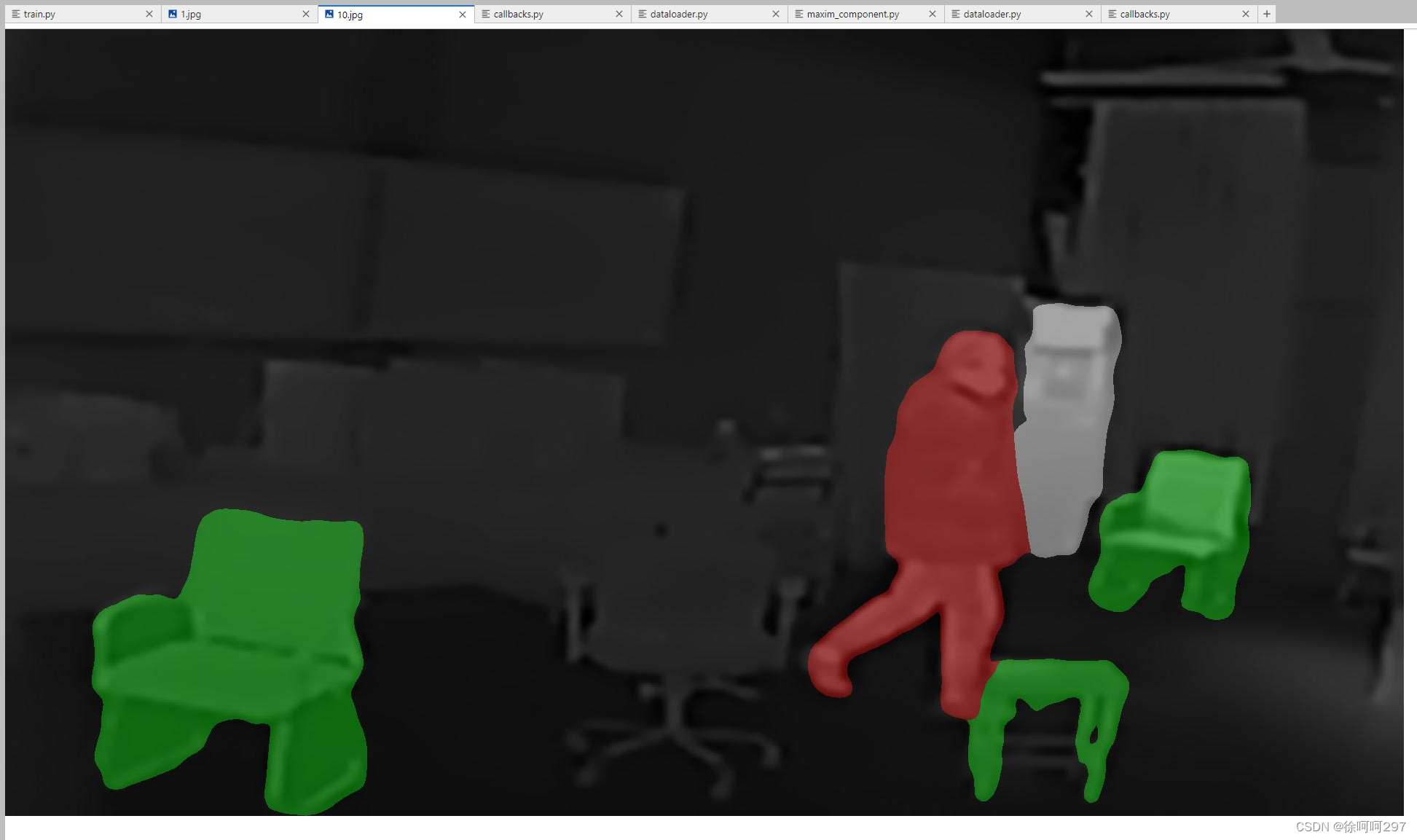
(暂时先这样)














 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









