







 Apriori算法用于数据挖掘中的频繁模式和关联规则挖掘。通过支持度和置信度衡量项集相关性。例如,某商场手机与充电器的销售,支持度56%,置信度70%。算法通过多次扫描数据集找到满足阈值的频繁项集。这里提供了一个使用Java连接MySQL实现Apriori的代码示例。
Apriori算法用于数据挖掘中的频繁模式和关联规则挖掘。通过支持度和置信度衡量项集相关性。例如,某商场手机与充电器的销售,支持度56%,置信度70%。算法通过多次扫描数据集找到满足阈值的频繁项集。这里提供了一个使用Java连接MySQL实现Apriori的代码示例。
Apriori算法在数据挖掘中主要挖掘频繁模式和关联规则,这个算法比较简单,但是开销很大,需要扫描数据库。
预备知识:
支持度(Support)的公式是:Support(A->B)=P(A U B)。支持度揭示了A与B同时出现的概率。如果A与B同时出现的概率小,说明A与B的关系不大;如果A与B同时出现的非常频繁,则说明A与B总是相关的。支持度: P(A∪B),即A和B这两个项集在事务集D中同时出现的概率。
置信度(Confidence)的公式式:Confidence(A->B)=P(A | B)。置信度揭示了A出现时,B是否也会出现或有多大概率出现。如果置信度度为100%,则A和B可以捆绑销售了。如果置信度太低,则说明A的出现与B是否出现关系不大。置信度: P(B|A),即在出现项集A的事务集D中,项集B也同时出现的概率。
示例:某销售手机的商场中,70%的手机销售中包含充电器的销售,而在所有交易中56%的销售同时包含手机和充电器。则在此例中,支持度为56%,置信度为70%。
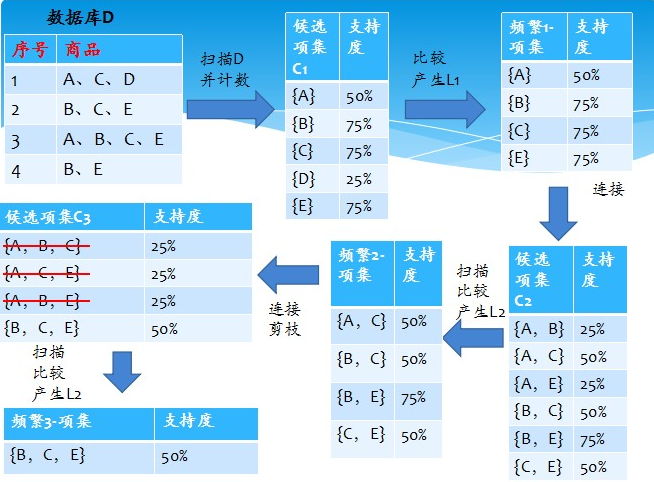
算法原理:扫描整体数据集,寻找满足支持度阈值和置信度阈值的频繁项集。每一次依次增加一项,就是说第1次找满足支持度阈值和置信度阈值的频繁1项集,第2次找满足支持度阈值和置信度阈值的频繁2项集;第k次找满足支持度阈值和置信度阈值的频繁k项集。
过程描述:
实现代码:
目的:挖掘频繁项集和关联规则;数据可以使数字也可以是文本。
package ne;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class apriori2
{
private final static int SUPPORT = 2; // 支持度阈值
private final static double CONFIDENCE = 0.7;
// 置信度阈值
private final static String ITEM_SPLIT = ";";
// 项之间的分隔符
private final static String CON = "->";
// 项之间的分隔符
/**
* 算法主程序
* @param dataList
* @return
*/
public Map<String, Integer> apriori(ArrayList<String> dataList)
{
Map<String, Integer> stepFrequentSetMap = new HashMap<>();
stepFrequentSetMap.putAll(findFrequentOneSets(dataList));
Map<String, Integer> frequentSetMap = new HashMap<String, Integer>();//频繁项集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2910
2910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









