







朴素贝叶斯的基本概念和定理
朴素贝叶斯假设数据是服从条件独立性假设的,有了这一个严格的限制,就可以求联合概率分布,算法中最重要的公式就是条件概率,
设输入空间是n维向量的集合,取其中m个样本做训练数据集,表示为S={S_1,S_2,…,S_m},其中每个样本S_i都是一个n维向量{x_1,x_2,…,x_n};输出空间是类标记的集合,表示为Y={C_1,C_2,…,C_k},取自输入空间的每个样本S_i都与输出空间中的一个类C_i相对应。当给定另外一个类别未知的数据样本X,可以把X分到后验概率最大的类中,也就是用最高的条件概率P(C_i |X)来预测X的类,这是朴素贝叶斯分类的基本思想。根据贝叶斯定理,后验概率计算过程为:
P(C_i |X)=[P(X|C_i)∙P(C_i)]⁄(P(X))
学术解释是后验概率可以通过先验概率求得,将后验概率最大的类最为输出类。
如果X每个维度的特征可能有T_j个取值,j=1,2,…,n,C_i的可能取值有k个,那么参数的个数为
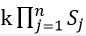
**
朴素贝叶斯分类的过程
**
首先选取一部分数据作为训练数据,然后求出先验概率和条件概率。
如下表所示的数据:

首先计算先验概率:
P(C=1)=9/15 ,P(C=-1)=6/15
然后计算条件概率:
P(X^((1) )=1|C=1)=2/9,P(X^((1) )=2|C=1)=3/9,P(X^((1) )=3|C=1)=4/9
P(X^((2) )=S|C=1)=1/9,P(X^((2) )=P|C=1)=4/9,P(X^((2) )=Q|C=1)=4/9
P(X^((1) )=1|C=-1)=3/6,P(X^((1) )=2|C=-1)=2/6,P(X^((1) )=3|C=-1)=1/6
P(X^((2) )=S|C=-1)=3/6,P(X^((2) )=P|C=-1)=2/6,P(X^((2) )=Q|C=-1)=1/6
最后对待预测的数据进行分类。
P(C=1)∙ P(X^((1) )=2|C=1)∙ P(X^((2) )=S|C=1)=9/15∙3/9∙1/9=1/45
P(C=-1)∙ P(X^((1) )=2|C=-1)∙ P(X^((2) )=S|C=-1)=6/15∙2/6∙3/6=1/15
依照朴素贝叶斯采用的概率最大化准则,该分类器输出的类标记为-1。
朴素贝叶斯分类算法的一些问题
1、朴素贝叶斯分类算法属于生成式模型—对于输入x,类别标签y,估计它们的联合概率分布P(x,y)。
2、朴素贝叶斯算法实现简单,学习和预测的效率较高,在小规模数据集上有较好的效果。
3、能够避免误差点和离群点对结果的影响,因为对每个检测样本的归类,都是根据全部训练集的信息得到的。
4、需要数据满足假设,即服从独立分布,但是大多数情况下数据不是服从独立分布的。
5、在低维数据上较适合,但是不适合高维数据。–这是因为要计算
6、可以适用于多分类。
7、处理特征的时候要把高相关的特征去掉,因为这样的特征起了多次作用。
8、对于类别类的输入特征变量,效果非常好。对于数值型变量特征,我们是默认它符合正态分布的,否则要变换成正太分布的。
9、为避免出现概率为0情况,要使用拉普拉斯平滑。
贝叶斯估计
用极大似然估计估计概率的时候会出现概率为0 的时候,这个会影响后续的计算,解决方法是使用贝叶斯估计,即在计算条件概率的时候加入拉普拉斯平滑。如下:
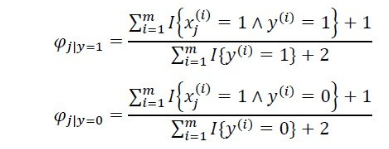
同样,也要对先验概率进行平滑,分子加lanmuda,分母加上K倍的lanmuda















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









