







原理
在分类(classification)问题中,常常需要把一个事物分到某个类别。一个事物具有很多属性,把它的众多属性看做一个向量,即 x=(x1,x2,x3,…,xn) ,用x这个向量来代表这个事物。类别也是有很多种,用集合 Y=y1,y2,…ym 表示。如果x属于 y1 类别,就可以给x打上 y1 标签,意思是说x属于 y1 类别。这就是所谓的分类(Classification)。
x的集合记为X,称为属性集。一般X和Y的关系是不确定的,你只能在某种程度上说x有多大可能性属于类 y1 ,比如说x有80%的可能性属于类 y1 ,这时可以把X和Y看做是随机变量, P(Y|X) 称为Y的后验概率(posterior probability),与之相对的,P(Y)称为Y的先验概率(prior probability)1。
在训练阶段,我们要根据从训练数据中收集的信息,对X和Y的每一种组合学习后验概率 P(Y|X) 。分类时,来了一个实例x,在刚才训练得到的一堆后验概率中找出所有的 P(Y|x) , 其中最大的那个y,即为x所属分类。根据贝叶斯公式,后验概率为 P(Y|X)=P(X|Y)P(Y)P(X)
在比较不同Y值的后验概率时,分母P(X)总是常数,因此可以忽略。先验概率P(Y)可以通过计算训练集中属于每一个类的训练样本所占的比例容易地估计。这里直接计算P(Y|X)比较麻烦,而朴素贝叶斯分类提出了一个独立性假设:x1,x2,...,xn相互独立,这也是被称之为“朴素”的原因之一。于是P(X|Y) = P(x1|Y)P(x2|Y)...P(xn|Y),而P(xi|Y)很好求了。
对于二元分类,要比较P(Y=1|X)和P(Y=0|X)的大小,只需比较分子P(X|Y)P(Y)部分。因此只需计算n个条件概率和先验概率。
文本分类
<d,c>={Beijing joins the World Trade Organization, China}
对于这个只有一句话的文档,我们把它归类到 China,即打上china标签。
我们期望用某种训练算法,训练出一个函数γ,能够将文档映射到某一个类别:
γ:X→C
这种类型的学习方法叫做有监督学习,因为事先有一个监督者(我们事先给出了一堆打好标签的文档)像个老师一样监督着整个学习过程。
朴素贝叶斯分类器是一种有监督学习,常见有两种模型,多项式模型(multinomial model)和伯努利模型(Bernoulli model)。
多项式模型
在多项式模型中, 设某文档d=(t1,t2,…,tk),tk是该文档中出现过的单词,允许重复,则
先验概率P(c)= 类c下单词总数/整个训练样本的单词总数
类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+|V|)
V是训练样本的单词表(即抽取单词集合,单词出现多次,只算一个),|V|则表示训练样本包含多少种单词。在这里,m=|V|, p=1/|V|。
P(tk|c)可以看作是单词tk在证明d属于类c上提供了多大的证据,而P(c)则可以认为是类别c在整体上占多大比例(有多大可能性)。
伯努利模型
P(c)= 类c下文件总数/整个训练样本的文档总数
P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下文档总数+2) 在这里,m=2, p=1/2。
#这里一定要注意:伯努利是以文档为粒度的,所以分母是文档总数,而不是网上以讹传讹的类c下单词总数
这里贴几个以讹传讹的链接:
http://blog.csdn.net/kongying168/article/details/7026389
http://cn.soulmachine.me/blog/20100528/
还有好多其他的就不一一列举了。
上面两个模型中的分子分母都加上了一些数,这是为了防止某个条件概率为0,从而整个P(X|Y) = P(x1|Y)P(x2|Y)...P(xn|Y)乘积为0。
实例演示
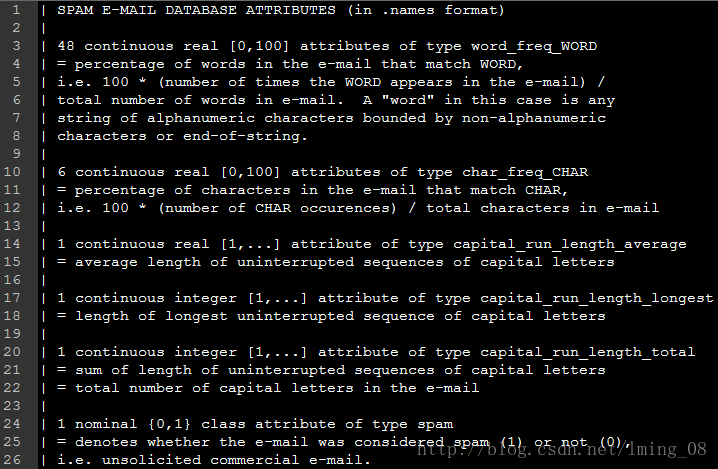
#!/usr/bin/python
# NaiveBayes classification
# lming_08 2014.07.06
import math
import numpy as np
from sklearn import metrics
class NaiveBayes:
def __init__(self, trainFile):
self.trainingFile = trainFile
self.trainingData = self.read_data(trainFile)
# Read training or testing data
def read_data(self, file):
data = []
fd = open(file)
for line in fd:
arr = line.rstrip().split(',')
# Turn an instance's last column(y column) as integer
arr[-1] = int(arr[-1])
# Append the instance to trainingData
data.append(tuple(arr))
fd.close()
return data
def train_model_with_Bernoulli(self):
self.sumPosInstance = 0.
self.sumNegInstance = 0.
self.termfreq = {}
for instance in self.trainingData:
if int(instance[-1]) == 1:
self.sumPosInstance += 1
else:
self.sumNegInstance += 1
for i in range(len(instance) - 1):
key = str()
if i < 55:
if float(instance[i]) > 0:
key = "freq" + "|" + str(i + 1) + "|" + "1"
else:
key = "freq" + "|" + str(i + 1) + "|" + "0"
else:
key = "length" + "|" + str(i + 1) + "|" + instance[i]
if key not in self.termfreq:
self.termfreq[key] = [0, 0]
if int(instance[-1]) == 1:
self.termfreq[key][1] += 1
else:
self.termfreq[key][0] += 1
# prior_prob = p(y = 1)
self.prior_prob = self.sumPosInstance / (self.sumPosInstance + self.sumNegInstance)
# prior_ratio = p(y=1) / p(y=0)
self.prior_ratio = self.sumPosInstance / self.sumNegInstance
# the function should be called before predict()
def set_testfile(self, testFile):
self.testing_data = self.read_data(testFile)
def predict(self):
self.testingY = []
self.predict_result = []
for instance in self.testing_data:
self.predict_result.append(self.predict_instance_with_Bernoulli(instance))
self.testingY.append(instance[-1])
def get_statistics(self):
true_classify_count = 0.
false_classify_count = 0.
for instance in self.testing_data:
post_prob = self.predict_instance_with_Bernoulli(instance)
if post_prob >= 0.5 and instance[-1] == 1:
true_classify_count += 1
elif post_prob >= 0.5 and instance[-1] == 0:
false_classify_count += 1
elif post_prob < 0.5 and instance[-1] == 1:
false_classify_count += 1
elif post_prob < 0.5 and instance[-1] == 0:
true_classify_count += 1
return true_classify_count, false_classify_count
def predict_instance_with_Bernoulli(self, instance):
f = 0.
for i in range(len(instance) - 1):
key = str()
if i < 55:
if float(instance[i]) > 0:
key = "freq" + "|" + str(i + 1) + "|" + "1"
else:
key = "freq" + "|" + str(i + 1) + "|" + "0"
else:
key = "length" + "|" + str(i + 1) + "|" + instance[i]
if key in self.termfreq:
f += math.log( (self.termfreq[key][1] + 1) / ((self.termfreq[key][0] + 2) * self.prior_ratio) )
posterior_ratio = self.prior_ratio * math.exp(f)
# posterior probability
prob = posterior_ratio / (1. + posterior_ratio)
return prob
def getAUC(self):
y = np.array(self.testingY)
pred = np.array(self.predict_result)
fpr, tpr, thresholds = metrics.roc_curve(y, pred) # metrics.roc_curve(y, pred, pos_label=1)
auc = metrics.auc(fpr, tpr)
return auc
def main(trainFile, testFile):
nb = NaiveBayes(trainFile)
nb.train_model_with_Bernoulli()
nb.set_testfile(testFile)
nb.predict()
print("the value of AUC: " % nb.getAUC())
print("the value of priori probability:" % nb.priorProb)
if __name__ == "__main__":
if len(argv) != 3:
print "Usage: python %s trainFile(in) testFile(out)" % __file__
sys.exit(0)
main(argv[1], argv[2])#!/usr/bin/python
# Partitioning a file into training(80%) and testing file(20%)
# lming_08 2014.07.06
from random import randint
def partition_file(file, train_file, test_file):
ltest = []
ltrain = []
fd = open(file, "r")
train_fd = open(train_file, "w")
test_fd = open(test_file, "w")
test_index = 0
train_index = 0
for line in fd:
rnum = randint(1, 10)
if rnum == 5 or rnum == 6:
test_index += 1
ltest.extend(line)
if test_index == 100:
test_fd.writelines(ltest)
ltest = []
test_index = 0
else:
train_index += 1
ltrain.extend(line)
if train_index == 100:
train_fd.writelines(ltrain)
ltrain = []
train_index = 0
if len(ltest) > 0:
test_fd.writelines(ltest)
if len(ltrain) > 0:
train_fd.writelines(ltrain)
train_fd.close()
test_fd.close()
fd.close()
Classify.py 执行文件
#!/usr/bin/python%
# main execute file
# lming_08 2014.07.06
import sys
from sys import argv
from NaiveBayes import NaiveBayes
from PartitionFile import partition_file
def main(srcFile, trainFile, testFile):
partition_file(srcFile, trainFile, testFile)
nb = NaiveBayes(trainFile)
nb.train_model_with_Bernoulli()
nb.set_testfile(testFile)
nb.predict()
print("the value of AUC: %f" % nb.getAUC())
print("the value of priori probability: %f" % nb.prior_prob)
true_classify_count, false_classify_count = nb.get_statistics()
error_rate = false_classify_count/(true_classify_count + false_classify_count)
print("the error rate : %f" % error_rate)
if __name__ == "__main__":
if len(argv) != 4:
print "Usage: python %s srcFile(in) trainFile(out) testFile(out)" % __file__
sys.exit(0)
main(argv[1], argv[2], argv[3])执行结果为:

参考文献
http://blog.csdn.net/kongying168/article/details/7026389 http://cn.soulmachine.me/blog/20100528/
http://www.chepoo.com/naive-bayesian-text-classification-algorithm-to-learn.html
http://blog.csdn.net/chjjunking/article/details/5933105















 2678
2678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









