







一、svm是什么?
支持向量机(Support Vector Machine,SVM)首先是由Vapnik提出的,可用于模式分类和非线性回归问题。
svm的基本思想:
寻找一个分类超平面作为决策面,使得正、反例之间的隔离边缘被最大化。
svm的理论基础:统计学习理论(结构风险最小化的近似实现)。
二、libsvm
libsvm是台湾大学Lin Chih-Jen教授等开发设计的一个简单、便于使用且高效的svm软件包,提供了Java、MATLAB、python等环境下的执行文件,开源了代码,方便改进和修改。
1.libsvm在MATLAB下的安装
在安装包..\matlab\README中有详细的步骤,如下:
On Windows systems, pre-built binary files are already in the directory
`..\windows', so no need to conduct installation. Now we include both
32bit binary files and 64bit binary files, but in future releases, we
will provide binary files only for 64bit MATLAB on Windows. If you have
modified the sources and would like to re-build the package, type
'mex -setup' in MATLAB to choose a compiler for mex first. Then type
'make' to start the installation.
Example:
matlab> mex -setup
(ps: MATLAB will show the following messages to setup default compiler.)
Please choose your compiler for building external interface (MEX) files:
Would you like mex to locate installed compilers [y]/n? y
Select a compiler:
[1] Microsoft Visual C/C++ version 7.1 in C:\Program Files\Microsoft Visual Studio
[0] None
Compiler: 1
Please verify your choices:
Compiler: Microsoft Visual C/C++ 7.1
Location: C:\Program Files\Microsoft Visual Studio
Are these correct?([y]/n): y
matlab> make
2.libsvm小试牛刀
从libsvm数据库http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/下载heart数据,用libsvm对数据进行分类。
由于下载到的数据是C++格式的数据,所以用libsvmread()导入数据,具体代码如下:
>> libsvmread('heart_scale');
>> model=svmtrain(heart_scale_label,heart_scale_inst);
>> [predict_label,accuracy,dec_value]=svmpredict(heart_scale_label,heart_scale_inst,model);
Accuracy = 86.6667% (234/270) (classification)
3.训练、预测函数对应的参数:
matlab> model = svmtrain(training_label_vector, training_instance_matrix [, 'libsvm_options']);
-training_label_vector:
An m by 1 vector of training labels (type must be double).
-training_instance_matrix:
An m by n matrix of m training instances with n features.
It can be dense or sparse (type must be double).
-libsvm_options:
A string of training options in the same format as that of LIBSVM.
matlab> [predicted_label, accuracy, decision_values/prob_estimates] = svmpredict(testing_label_vector, testing_instance_matrix, model [, 'libsvm_options']);
-testing_label_vector:
An m by 1 vector of prediction labels. If labels of test
data are unknown, simply use any random values. (type must be double)
-testing_instance_matrix:
An m by n matrix of m testing instances with n features.
It can be dense or sparse. (type must be double)
-model:
The output of svmtrain.
-libsvm_options:
A string of testing options in the same format as that of LIBSVM.
4.多分类svm
svm算法最开始是解决二分类问题的,libsvm的多分类方法是通过的多个二分类器构造而成:
(1)一对多(one-versus-rest):训练时依次吧某个类别的样本归为一类,剩余的样本归为另一类,k个类别的样便可构造k个分类器。测试时将未知样本划分到具有最大分类函数值的那类。该方法会产生“分类重叠”和“不可分”两种尴尬情况。
参考:http://www.matlabsky.com/thread-10316-1-1.html
(2)一对一(one-versus-one):任意两类样本之间设计一个SVM二分类器,若有k个类别的样本就需要设计k(k-1)/2个二分类器。测试时通过投票的方法将被测试的未知样本归为所得票数最多的哪一类。
(3)层次SVM(H-SVMs):所有类别的样本划分成两个子类,再将子类进一步划分成次子类,如此循环。
(4)有向无环图SVM(DAG-SVMs)。
5.svmtrain中的option参数的选择(参考:http://www.matlabsky.com/thread-12380-1-1.html)
Options:可用的选项即表示的涵义如下
-s svm类型:SVM设置类型(默认0)
0 -- C-SVC
1 --v-SVC
2 – 一类SVM
3 -- e -SVR
4 -- v-SVR
-t 核函数类型:核函数设置类型(默认2)
0 – 线性:u'v
1 – 多项式:(r*u'v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(r*u'v + coef0)
-d degree:核函数中的degree设置(针对多项式核函数)(默认3)
-g r(gama):核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数)(默认1/ k)
-r coef0:核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
-c cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1)
-n nu:设置v-SVC,一类SVM和v- SVR的参数(默认0.5)
-p p:设置e -SVR 中损失函数p的值(默认0.1)
-m cachesize:设置cache内存大小,以MB为单位(默认40)
-e eps:设置允许的终止判据(默认0.001)
-h shrinking:是否使用启发式,0或1(默认1)
-wi weight:设置第几类的参数C为weight*C(C-SVC中的C)(默认1)
-v n: n-fold交互检验模式,n为fold的个数,必须大于等于2
其中-g选项中的k是指输入数据中的属性数。option -v 随机地将数据剖分为n部分并计算交互检验准确度和均方根误差。
6.svm的常用核函数(转自:http://blog.csdn.net/xiaowei_cqu/article/details/35993729)
线性核(Linear Kernel)
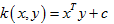
多项式核(Polynomial Kernel)
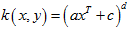
径向基核函数(Radial Basis Function)
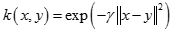
也叫高斯核(Gaussian Kernel),因为可以看成如下核函数的领一个种形式:
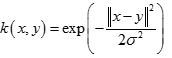
径向基函数是指取值仅仅依赖于特定点距离的实值函数,也就是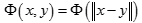
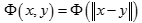
幂指数核(Exponential Kernel)
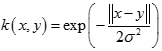
拉普拉斯核(Laplacian Kernel)
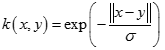
ANOVA核(ANOVA Kernel)
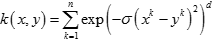
二次有理核(Rational Quadratic Kernel)
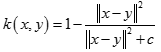
多元二次核(Multiquadric Kernel)
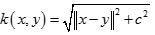
逆多元二次核(Inverse Multiquadric Kernel)
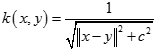
另外一个简单实用的是Sigmoid核(Sigmoid Kernel)

以上几种是比较常用的,大部分在SVM,SVM-light以及RankSVM中可用参数直接设置。还有其他一些不常用的,如小波核,贝叶斯核,可以需要通过代码自己指定。
7.交叉验证的方法选取参数c、g:
常常使用的是K-fold Cross Validation(K-CV):
将训练集划分为k组,取每一组作为测试集,其余k-1组为训练集,得到k个模型,分别进行分类验证得到的accuracy的均值为性能指标。遍历一定范围的c/g值取指标值最高的一组数据。















 2756
2756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









