







Moielens-1M数据集描述
数据集下载地址:Movielens-1M
下载下来数据集有4个文件,其中1个描述文件,3个数据文件。
1. ratings.dat
文件当中包含了所有的打分数据。
数据的格式如下
| 特征名称 | UserID | MovieID | Rating | Timestamp |
|---|---|---|---|---|
| 描述 | 从1到6040 | 从1到3952 | 最高分为5分,且打分只能为整数 | 打分的时间戳(一般没啥用) |
数据集当中每个用户至少有20个打分记录
2. users.data
- 里面包含贡献这些打分数据的志愿者的人口统计信息。(信息不保证完全准确)
- 所有的用户都包含在内
2.1 数据集的格式如下
| 特征名 | UserID | Gender | Age | Occupation | Zip-Code |
|---|---|---|---|---|---|
| 描述 | 用户id,和ratings.data当中是对应的 | 用户的性别 | 年龄范围 | 职业 | 邮政编码 |
2.2 数据集各个特征的取值描述如下
Gender
- M:代表男性
- F:代表女性
Age
- 1: “18岁以下”
- 18: “18-24”
- 25: “25-34”
- 35: “35-44”
- 45: “45-49”
- 50: “50-55”
- 56: “56以上”
Occupation
- 0: “other” or not specified(其他职业,或没有精确规定)
- 1: “academic/educator”(学术/教育)
- 2: “artist”(艺术家)
- 3: “clerical/admin”
- 4: “college/grad student”(大学生/研究生)
- 5: “customer service”(服务行业)
- 6: “doctor/health care”(医生/卫生保健)
- 7: “executive/managerial”(主管/经理)
- 8: “farmer”(农民)
- 9: “homemaker”(主妇)
- 10: “K-12 student”(可能是12岁以下的学生)
- 11: “lawyer”(律师)
- 12: “programmer”(程序员)
- 13: “retired”(退休的)
- 14: “sales/marketing”(销售/市场营销)
- 15: “scientist”(科学家)
- 16: “self-employed”(个体经营户)
- 17: “technician/engineer”(技术人员/工程师)
- 18: “tradesman/craftsman”(手工艺人)
- 19: “unemployed”(被解雇的人)
- 20: “writer”(作家)
3. movies.dat
包含电影的详细信息
这个文件在读取的时候要注意,这个文件里面有字符串类型的特征,文件的编码是’latin-1’,不是’utf-8’。
movies = pd.read_csv('./data/movies.dat', sep='::', names=['MovieID', 'Title', 'Genres'],encoding='latin-1')
3.1 数据集的格式如下
| 特征名 | MovieID | Title | Genres |
|---|---|---|---|
| 描述 | 电影id | 电影标题(电影年份) | 体裁(一部电影可能包含多种体裁),数据集当中用’|'来分隔不同体裁 |
3.2 数据集各个特征的取值描述如下
MovieID
电影ID很好理解,和ratings里面是对应的
Titles
- 标题信息与IMDB提供的是一致的
- 标题当中还包含电影的发行年
Genres
电影体裁分为下面几种
- Action(动作类)
- Adventure(冒险类)
- Animation(卡通动漫)
- Children’s(子供向)
- Comedy(喜剧片)
- Crime(犯罪片)
- Documentary(纪录片)
- Drama(戏剧)
- Fantasy(奇幻幻想片)
- Film-Noir
- Horror(恐怖片)
- Musical(音乐剧)
- Mystery(解密类)
- Romance(浪漫)
- Sci-Fi(科幻片)
- Thriller(惊悚片)
- War(战争片)
- Western(西方)
注意:
- 由于某些意外,某些电影id没有对应电影
- 信息的录入手工完成,可能包含一些错误
对数据进行探索
1. 读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
ratings = pd.read_csv('./data/ratings.dat', sep='::', names=['UserID', 'MovieID', 'Rating', 'Timestamp'])
ratings.head()
ratings.info()

users = pd.read_csv('./data/users.dat', sep='::', names=['UserID', 'Gender', 'Age', 'Occupation', 'Zip-code'])
users.head()
users.info()


movies = pd.read_csv('./data/movies.dat', sep='::', names=['MovieID', 'Title', 'Genres'],encoding='latin-1')
movies.head()
movies.info()


2. 查看数据集当中包含多少用户
users.dat当中包含的用户数目
users.shape
(6040, 5)
ratings.dat当中包含的用户数目
ratings['UserID'].unique().shape
(6040,)
两个文件当中的用户数目相同,可以对的上
3. 查看数据集当中包含多少电影
movies.shape
(3883, 3)
ratings['MovieID'].unique().shape
(3706,)
两边数据对不上,根据数据集提供者的描述可以知道,movies里面有部分电影是ratings当中没有出现的. 应当以ratings当中的电影数为准 电影总数为3206
4. 3. 平均每个用户对多少电影进行类评分
Average_user_ratingt = ratings['UserID'].value_counts().sort_index()
Average_user_ratingt = Average_user_ratingt.to_frame().reset_index()
Average_user_ratingt.columns = ['UserID', 'Count']
Average_user_ratingt.head()
Average_user_ratingt.describe()
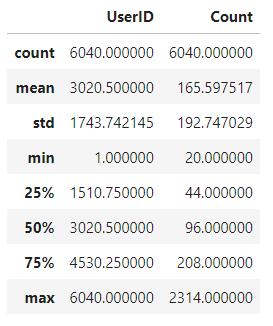
每个用户至少看了20部电影,最多的用户看了2314部, 平均每个用户看了165.6部电影
Average_user_ratingt['Count'].plot(kind='hist', bins=20)

5. 每个用户的平均评分和每部电影的平均评分
User_Rating_avg = ratings.drop(['MovieID', 'Timestamp'], axis=1).groupby('UserID').mean()
User_Rating_avg.head(10)
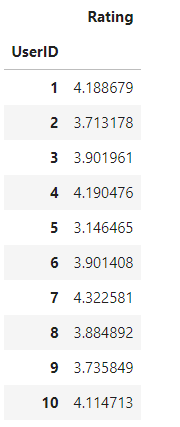 每个用户给电影打分的平均分如上表所示
每个用户给电影打分的平均分如上表所示
Movie_Rating_sum = ratings.drop(['UserID', 'Timestamp'], axis=1).groupby('MovieID').mean()
Movie_Rating_sum.head(10)
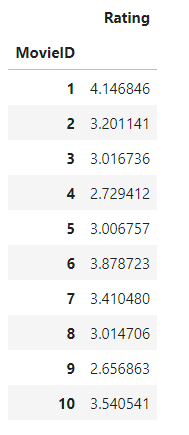
每部电影的平均分如上所示
3. 训练集和测试集的划分方式
我认为训练集和测试集的划分可以考虑下面几个问题
- 是否所有用户都出现在训练集当中
- 是否所有电影都出现在训练集当中
根据上面几种问题可以有下面几种划分方式
-
把所有打分数据放在一起,按照一定的比例进行划分训练集和测试集
这样划分可能会造成这么一种情况:有部分用户或者电影没有出现在训练集当中。有一些模型可能不能使用这种方式划分。
-
保证每个用户都出现在训练集当中,对每一个用户的打分数据,按比例划分训练集和测试集
-
保证每部电影都出现在训练集当中:对每一部电影的打分数据,按照比例进行划分训练集和测试集
-
保证每一部电影和用户都出现在训练集当中,这种划分方式相较于上面的两种划分方式稍微有些复杂。















 1025
1025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









