






文章目录
论文精读-ReMoNet: Recurrent Multi-Output Network for Efficient Video Denoising
优势
- 多输入多输出(MIMO)范式:ReMoNet提出了一种新颖的架构,可以在一次前向传播中处理连续的视频帧。这种方法利用了视频帧之间通常具有的时间一致性,通过减少重复计算来提高效率。
- 循环时序融合和多输出聚合块:相比传统的单帧处理模型,由于其使用了多帧输入输出,在减少计算量的同时,也增加了模型的考验。ReMoNet通过RTF提取潜在的特征帧(隐藏帧Zt),并通过MOA聚合相邻时间信息。
- 基于相似性的相互蒸馏:ReMoNet类似使用知识蒸馏的方法,通过同伴学习到的知识进一步增强了网络的性能。
方法
概述

1)应用单帧图像去噪算法,不使用任何时间信息yi=f(xi)。这属于传统的视频去噪方法,其通常将图像去噪方法推广到其视频处理对应部分。e.g.VBM4D
2)使用显式的时间建模。yi = f(wi(xi−T),…, xi,…, wi(xi+T))))
3)使用隐式时间建模。 yi = f(xi−T,…, xi+T)
其中,wi(xj)使用显式运动估计(如光流)去噪从第j帧到第i帧的扭曲,f表示深度神经网络参数化的去噪函数。
第3点区别第2点在于没有使用显示建模中的流量估计wi
而2、3点实际是利用时间相干性和帧间关系即视频中的时间一致性,这是与第1点的明显区别。
本文提出了一种新的方法,其为多输入多输出结构,简单来说就是同时处理多帧数据。同时,结合RTF与MOA结构,相似性互蒸馏训练策略,提高了整体性能。
动机与观察
1、连续视频帧通常共享相似的内容,并包含视觉冗余 (我们可以在中间压缩一部分帧数据,减少计算量的同时,也不会影响性能 => RTF+MOA)
2、神经网络通常是过度参数化的。当超过70%的参数被修剪时,神经网络甚至可以保持其性能 (很多网络是不需要那么复杂的,我们可以使用当前网络处理更多的数据,类似做模型与数据的正则化。 => MIMO+基于相似性的相互蒸馏)
3、在视频编码等其他视频应用中,通常在输入空间中进行冗余减少,其中连续的相似帧被压缩为(或预测为)一个代表性帧(Sousa 2000;Wiegand et al. 2003)。然而,这并不适用于我们的像素到像素去噪任务。(直接减少输入是不好的,我们使用多输入多输出MIMO )
基于观察提出通过多输入多输出策略来减少输出空间中的冗余计算。多输入多输出(MIMO)公式:
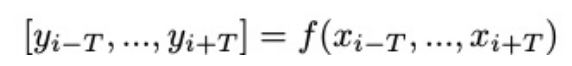
核心思想是:利用神经网络中的过度参数化,并在一次前向传递中处理连续帧,则可以大大减少对这些冗余视觉内容的计算。
利用2T+1时间输入的去噪网络(改变最后一卷积层的通道数量)可以在一次前向传播中对2T+1帧的数据进行降噪,所以理论上性能提升2T+1倍。
但这存在一个问题,网络是否有足够的容量处理这么多信息?->通过实验判断;最终选择的是2T+1=5,2K+1=3。
模型
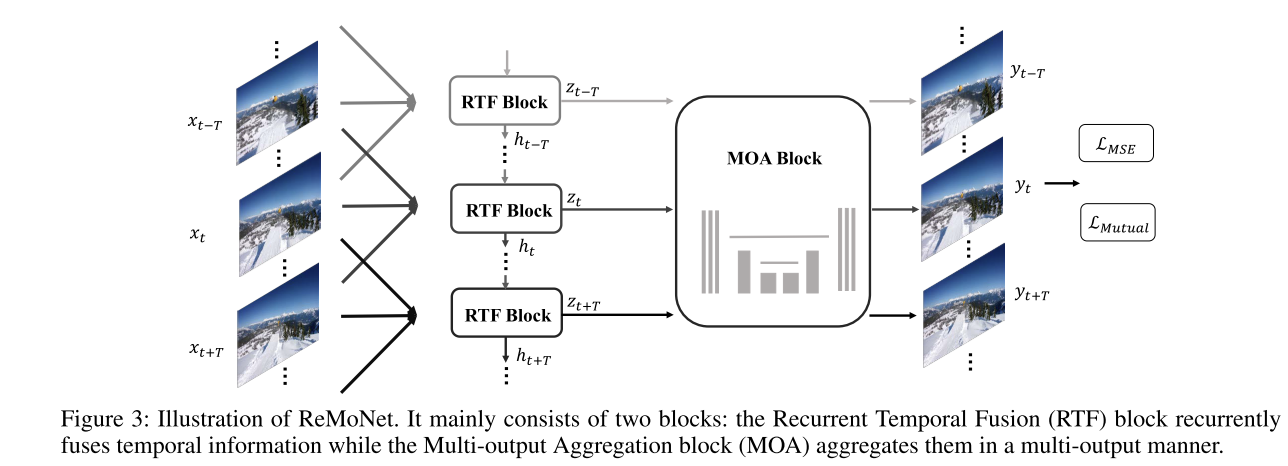
循环时间融合RTF
用于提取潜在的特征帧。其具有轻量级的微型UNet结构
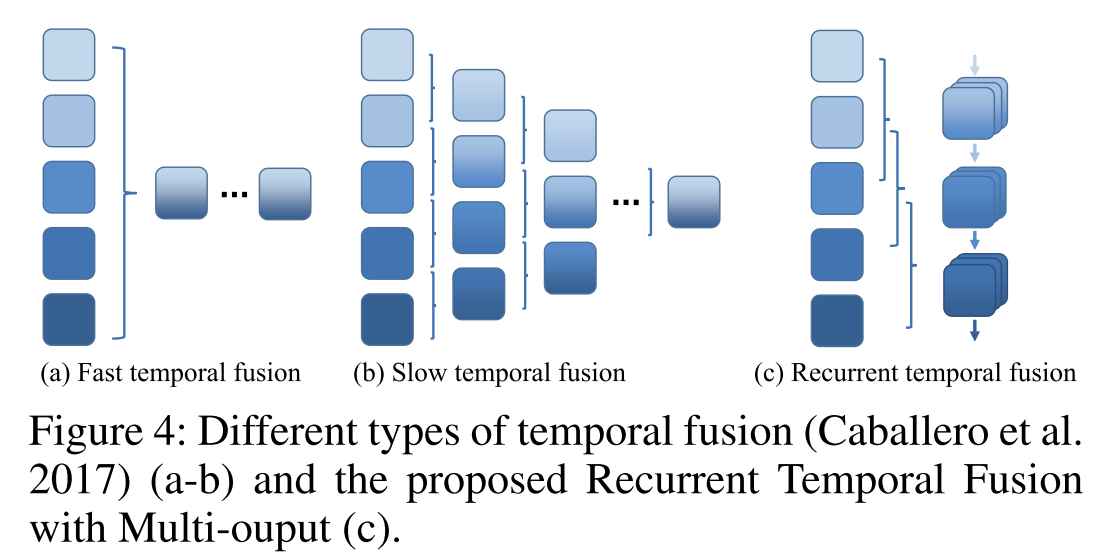
1)快时间融合
沿着信道维度将所有输入帧连接在一起,所以时间信息在第一层之后不存在
2)慢时间融合
将2K + 1帧合并成小于输入帧数2T + 1的组,并沿着时间轴逐渐融合。
效果:慢时间融合>快时间融合
在此基础上,本文提出了周期性融合策略。除了逐渐融合滑动窗口大小2K+1的时间信息外,我们还使用简单的循环结构来跟踪时间视觉关系。 (滑动窗口显而易见。而循环结构实际就是对应的轻量级unet网络,其包含上下采样,同一信息会被重复使用)
从结果来说,每个step是以2K+1帧作为输入,并输出2K+1的 “隐藏帧Zt” R(2K+1)CxHxW (隐藏帧Zt,每个z都是由时间核大小2K+1产生的,它小于整个序列长度2T+1)
实验观察到,MIMO风格的递归时间融合将有利于恢复。与非mimo RTF块相比,RTF- mimo隐含地学习了更多样化的信息。
多输出聚合MOA
用于聚合相邻的时间信息。
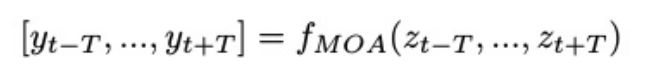
yi∈RCxHxW。它取多个zi∈R(2K+1)×H×W, i∈[t−t, t + t]作为输入,输出[yt−t,…, yt+T]
通过RTF作为快速提取,和MOA聚合信息,带来了两个好处:
1、通过每个step处理2T+1时间帧数据,很大程度加快了处理速度;=>MIMO与RTF的优点
2、提高了去噪性能,因为每个隐藏帧Zt中的局部融合的时间信息被聚合和细化。=>MOA的优点
基于相似性的互蒸馏训练
类似知识蒸馏,教师-学生模型。区别在于,这个是相互之间蒸馏而非单向。
动机:希望充分利用网络容量,让它们吸收更多的信息。基于相似性的相互蒸馏提供了一个额外的监督信号,迫使网络不仅要从基础事实中学习,还要从它们的同伴中学习。(其主要体现在loss函数中)

其中||·||F是Frobenius范数,范数表示逐行L2归一化,gi表示每个mini-batch内帧之间的视觉相似性图。直观地说,由于神经网络的训练轨迹是随机的,每个学生网络可能学习到不同的信息,并且相互补充。
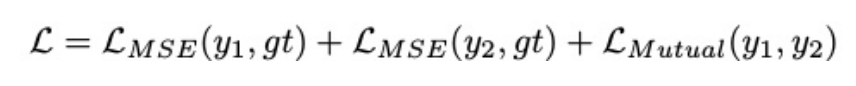
其中LMSE表示ReMoNet的输出yi与ground-truth帧gt之间的均方误差。在测试期间,我们随机选择一个ReMoNet进行推理,这不会带来额外的计算成本。
实验
训练集:DAVIS-train
测试集:set8、DAVIS-test
加入的噪声:1、高斯噪声(AWGN)2、模拟ISP处理噪声
RTF中输入帧为5(即T=2),隐藏帧为3(即K=1)。隐藏维数dim=32。
实验结果
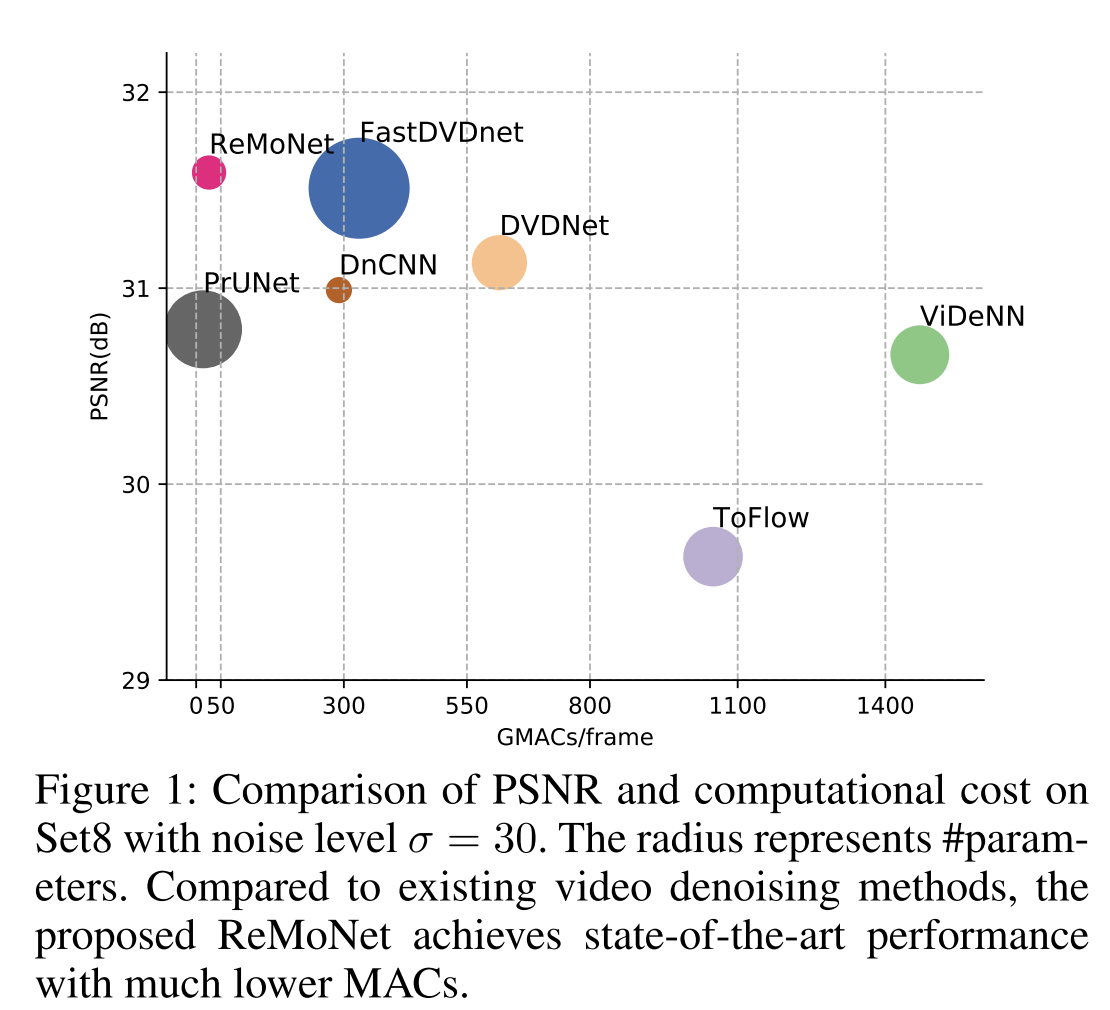
1、总体效果。 计算量、PSNR与最佳模型对比:
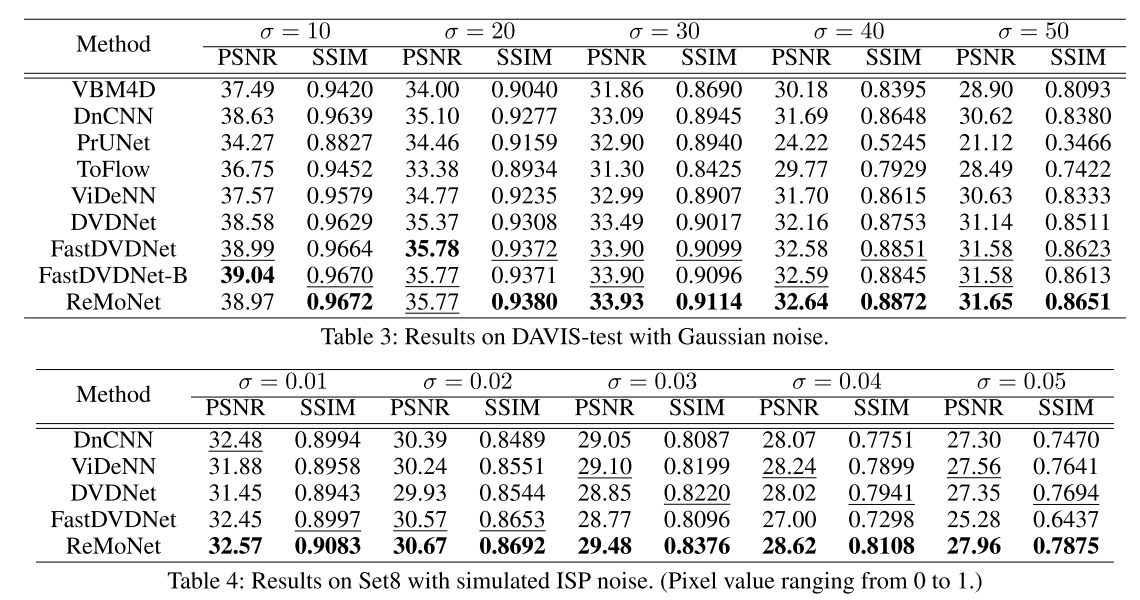
2、量化效果。 噪声水平越高,ReMoNet得到的改进越大,证明了其在复杂的现实世界噪声分布具有很好的泛化能力,而且在高水平噪声损坏下具有更强的鲁棒性。
3、高斯噪声效果。 考虑高斯噪声,噪声级σ= 40的GOPRO单板上的结果。结果表明,ReMoNet产生的结果比基线更干净、更自然。放大可以获得更好的视角。

大多数方法仍然会产生不相干的天空,其中一些天空充满了严重的噪声。而Re-MoNet能够还原一个清晰而连贯的天空,这更加自然。
4、ISP模型噪声效果。 模拟ISP噪声的Derf拖拉机试验结果,噪声水平σ= 0.05。我们观察到,在真实的噪声分布下,ReMoNet恢复的细节比基线方法更清晰(见黄色边界框)。放大可以获得更好的视图。

从牵引结果中,我们观察到只有ReMoNet清楚地回收了蓝色机械装置中的两个黑色成分。所有基线方法都无法恢复轮胎的复杂纹理,而ReMoNet恢复的纹理更接近原始的ground-truth(左侧的黄色边界框)。
5、速度。 在高通骁龙888移动平台上进行,其GPU用于推理。输入分辨率为360 ×640。结果表明,FastDVDNet处理一帧需要927ms。同时,ReMoNet处理5帧只需要446ms,即每帧89.2ms,比FastDVDNet快11倍。
QA
相似性的相互蒸馏加强? 利用同伴的知识相互进步。
Non-Local Net搜索相似的相邻图像补丁进行训练?
时间核,3D卷积?
在深度学习中,3D卷积(三维卷积)是一种常用的时间核,它能够处理具有时间维度的数据,如视频。3D卷积核在三个维度(宽度、高度、时间)上进行滑动,以捕捉空间和时间上的特征。
深度相互学习?GAN 判别器和生成器?
类似,但不完全。主要体现在相似性的相互蒸馏。
逐行L2归一化?
确保每个样本在空间中具有相同的尺度,从而使得算法更加公平地对待每个特征。

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











