






论文精读-SRFormer: Permuted Self-Attention for Single Image Super-Resolution
SRFormer:用于单图像超分辨率的排列自注意
Params:853K,MACs:236G
优点:
1、参考SwinIR的RSTB提出了新的网络块结构PAB(排列自注意力块),由此构建了新的网络层PSA。
2、通过信道压缩(减少通道数)+重排列(恢复通道数+缩减窗口大小,/r*r)减少了时间复杂度,并解决了大窗口自注意的参数量、计算成本大的问题。
3、将MLP中的普通卷积替换为深度卷积,补偿了缺失的高频信息。
如果图不全:论文精读-SRFormer Permuted Self-Attention for Single Image Super-Resolution
概述
增加基于变压器的图像超分辨率模型(例如SwinIR)的窗口大小可以显着提高模型性能,但计算开销也相当大。在本文中,我们提出了一种简单而新颖的SRFormer方法,它可以享受大窗口自关注的好处,但引入的计算负担更少。我们的SRFormer的核心是排列自注意(PSA),它在自注意的渠道和空间信息之间取得了适当的平衡。我们的PSA简单,可以很容易地应用于现有的基于窗口自关注的超分辨率网络。在没有任何附加功能的情况下,我们的SRFormer在Urban100数据集上实现了33.86dB的PSNR得分,比SwinIR高0.46dB,但使用的参数和计算量更少。我们希望我们的简单而有效的方法可以作为未来超分辨率模型设计研究的有用工具。
背景介绍
单图像超分辨率(SR)是一种从降级的低分辨率图像中恢复高质量图像的方法。基于cnn的方法长期以来一直是图像超分辨率的主流。这些方法大多利用残差学习[26,30,32,38,55,80]、密集连接[58,67,87]或通道关注[72,86]来构建网络架构。在SwinIR中适当地扩大窗口以转移窗口自关注可以带来明显的性能增益(见图1)。然而,随着窗口尺寸变大,计算负担也是一个重要问题。此外,与之前基于cnn的方法相比,基于变压器的方法利用自注意力,需要更大的通道数网络[26,86,87]。为了探索高效且有效的超分辨率算法,一个直截了当的问题应该是:如果我们减少通道数,同时增加窗口大小,性能会如何?
**在大窗口内建立成对关系的有效方法(例如,24 ×24)。其目的是使更多的像素参与到注意图计算中,同时不引入额外的计算负担。**为此,我们建议缩小键和值矩阵的通道维度,并采用置换操作将部分空间信息传递到通道维度中。这样,尽管通道减少了,但没有空间信息的损失,并且每个注意头也被允许保留适当数量的通道来产生表达性的注意图[60]。此外,我们还通过在两个线性层之间添加深度卷积来改进原始前馈网络(FFN),我们发现这有助于高频分量的恢复。
相关工作
CNN SR
自SRCNN[9]首次将CNN引入图像超分辨率(SR)以来,出现了大量基于cnn的SR模型。DRCN[27]和DRRN[55]引入递归卷积网络,在不增加参数的情况下增加了网络的深度。一些早期的基于cnn的方法[9,27,55,56]试图将低分辨率(LR)作为输入进行插值,这导致了计算代价高昂的特征提取。为了加速SR推理过程,FSRCNN[10]在LR尺度上提取特征,并在网络末端进行上采样操作。这种带有像素洗牌上采样[52]的流水线在后来的作品中得到了广泛的应用[37,85,86]。LapSRN[29]和DBPN[19]在提取特征时进行上采样,学习LR和HR之间的相关性。也有一些作品[30,65,67,83]使用GAN[14]在重建中生成逼真的纹理。MemNet[56]、RDN[87]和HAN[49]有效地聚合了中间特征,增强了重建图像的质量。非局部注意力[64]也在SR中得到了广泛的探索,以更好地模拟远程依赖关系。这类方法包括CS-NL[48]、NLSA[47]、SAN[7]、IGNN[89]等。
视觉Transformer SR
变压器最近在各种视觉任务中显示出巨大的潜力,包括图像分类[11,59,62,74,75],目标检测[4,12,16,54,73],图像字幕[33,69,84],语义分割[53,71,88],图像恢复[5,17,37,76]等。其中,最典型的工作应该是Vision Transformer (ViT)[11],它证明了变压器在特征编码上比卷积神经网络有更好的表现。变压器在低层次视觉中的应用主要包括两大类:生成[8,24,31,78]和恢复。进一步,恢复任务也可以分为两类:视频恢复[13、39、40、42、51]和图像恢复[5、18、68、70、76]。作为图像恢复的一项重要任务,图像超分辨率需要保持输入图像的结构信息,这对设计基于变压器的图像模型提出了很大的挑战。IPT[5]是基于Transformer编码器和解码器结构的大型预训练模型,并已应用于超分辨率、去噪和去训练。SwinIR[37]基于SwinTransformer编码器[41],在8 ×8局部窗口上进行特征提取的自关注,实现了极其强大的性能。ELAN[85]简化了SwinIR的架构,并使用在不同窗口大小下计算的自关注来收集远程之间的相关性像素。
SRFormer
SRFormer也是基于Transformer的。与前面提到的直接利用自我关注来构建模型的方法不同,我们的SRFormer主要针对的是自我关注本身。我们的目的是研究如何在不增加参数和计算成本的情况下,在大窗口内计算自注意力,以提高SR模型的性能。
方法
模型架构
SwinIR:
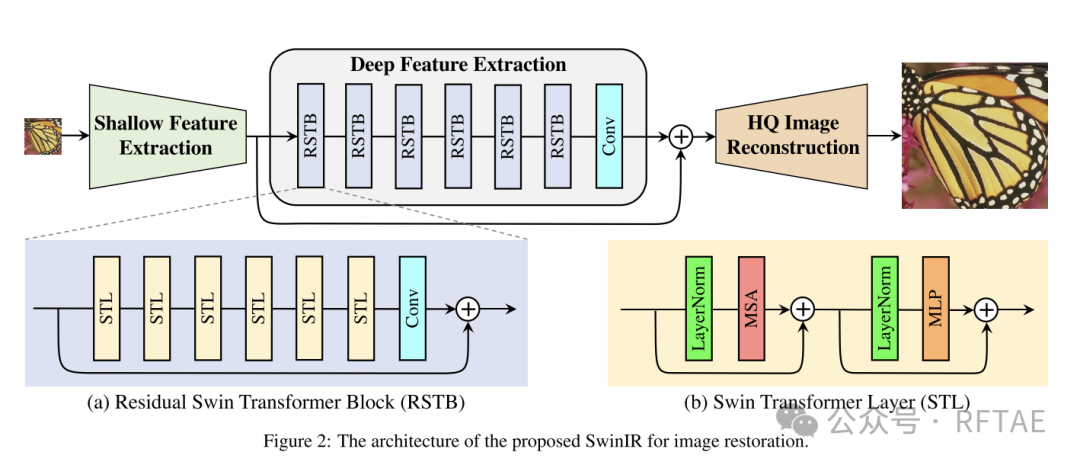
SRFormer(基础架构与SwinIR一致,只是将其中的RSTB块替换为了PAB块):
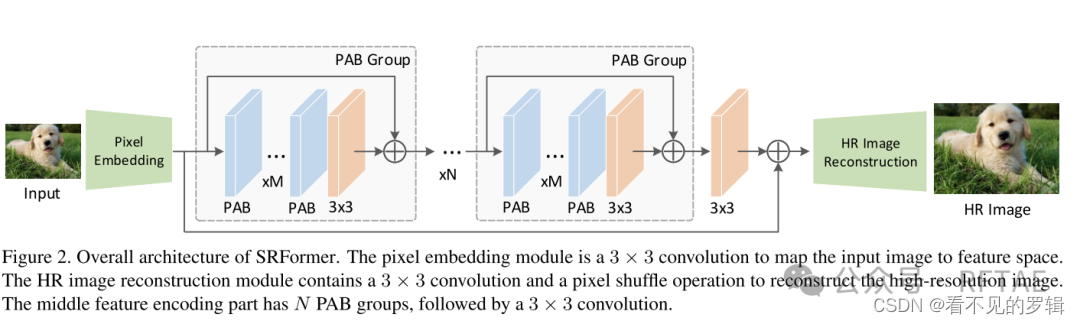
像素嵌入层(低维信息获取):
使用CNN网络 3x3卷积
特征编码器(高维信息获取):
使用新的 基于PAB+CNN的PSA网络
PSA=MxPAB+3x3Conv
整个中间层=NxPSA+3x3Conv
重构模块:
3x3 卷积+亚像素卷积层
损失函数:仍然使用L1像素损失
排列自注意
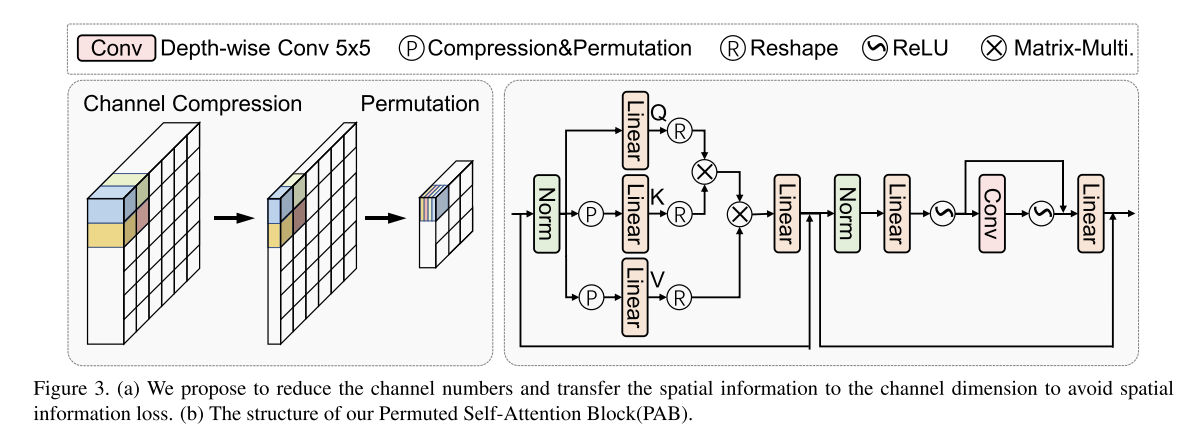
1、Xin ∈ R(H×W×C)
2、拆分窗口=> X ∈ R(N*S^2×C) N个S x S的窗口
3、通道压缩=>
在这里,Q保持与X相同的通道维度,而LK和LV将通道维度压缩为C/r^2,得到
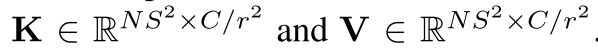
4、线性转换=> 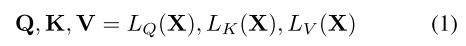
5、通道恢复=>
为了使更多的token参与到自关注计算中,避免计算成本的增加,我们建议将K和V中的空间token置换到通道维度。
(只需要移动数据,不需要计算)
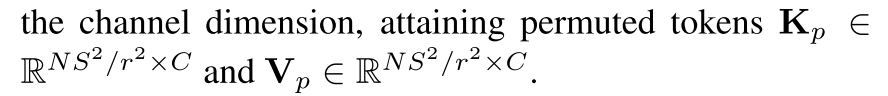
然后我们使用Q和缩小的Kp和Vp来执行自注意操作。
6、自注意力计算=>
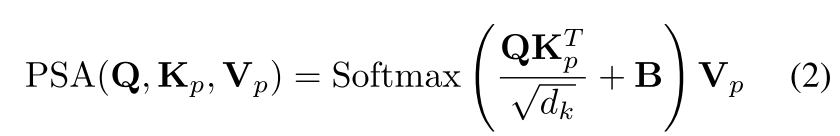
B是对齐的位置嵌入
其中Q:windows size:sxs C个通道
Kp:windows size:s/rxs/r C个通道
Vp:windows size:s/rxs/r C个通道
为了能够计算,需要填充相应的数据,可以填充相同数据,这样相同数据的计算可以避免(only copy)。
所以实际计算就是sxs 与 s/r x s/r进行MatMul的计算量。
计算复杂度
传统Attention计算:
4个线性投影:(Q,K,V,softmax)
=>4hwC^2 而 h*w =(h * w/N) *N
=> N * 4 * (S * S * C^2)其中括号内=S * S * C1、S * S * C2
2个矩阵乘法:(Q*K^T,attention score * V)
=>2W^2 hwC
=>N * 2 * ( S * S * S * S * C)其中括号内=S * S * C、S * S * C
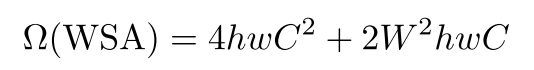
使用排列自注意(PSA)后:
4个线性投影:(Q,K,V,softmax)
其中的Q和softmax仍然和普通attention一致,即2hwC^2,而K和V计算,因为进行了通道压缩,所以
=>2hwC2/r2 而 h*w =(h * w/N) *N
=> N * 2 * (S * S * (C/r) ^2)其中括号内=S * S * C1/r、S * S * C2/r
2个矩阵乘法:(Q*K^T,attention score * V)
=>2W^2 (h/r)(w/r)C
=>N * 2 * ( S * S * S/r * S/r * C)其中括号内=S * S * C、S/r * S/r * C

PSA将K、V的线性投影计算和注意力计算减少到1/r^2。
深度卷积
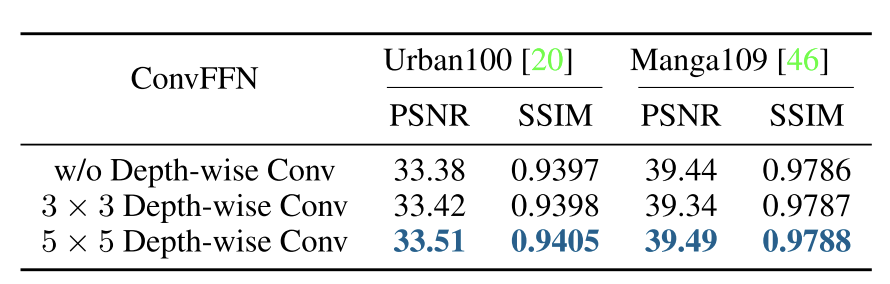
注意力可以被视为一个低通滤波器[50,61]。为了更好地恢复高频信息,通常在每组transformer的末尾添加3 ×3卷积。
在PAB中,我们建议在FFN块的两个线性层之间添加一个局部深度卷积分支,以帮助编码更多细节。我们将新块命名为ConvFFN。经验上看,几乎不增加计算量,但可以补偿自注
意引起的高频信息损失。

大窗口自注意
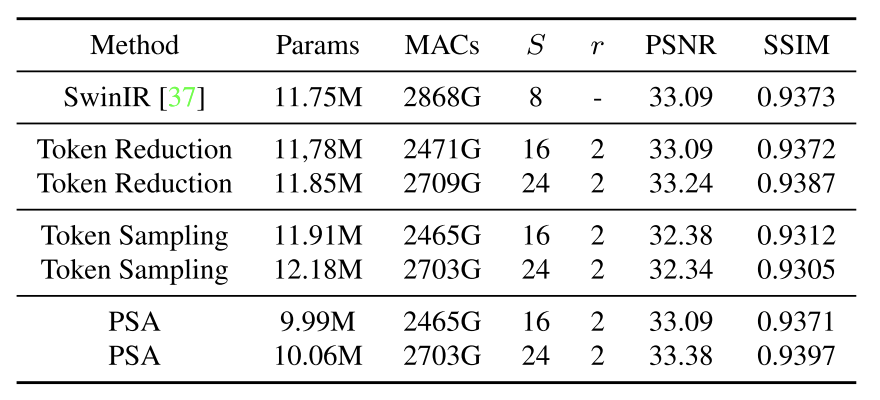
1、token reduction

使用一个深度卷积,直接将窗口大小缩小为S/r x S/r,从而减少计算量,它与PSA的通道恢复后进行MatMul类似。
2、token 采样
为了避免大窗口导致的计算成本增加,并想使用大窗口的带来的性能提升。token reduction采用从大窗口中随机抽取窗口大小为T的小窗口T^2 (0 ≤ T ≤ S),从而减少计算。NT^2 ×C。但是这样需要每次计算前,先进行令牌采样。且随机选择一部分令牌会丢失内容的结构信息,而这是图像SR所需要的。
计算成本:随窗口大小线性增加。
3、PSA方法
实验
1、深度卷积
2、大窗口自注意
3、大窗口下模型性能:

4、经典图像SR:

5、典型图像SR:

6、轻量级图像SR:

7、真实世界图像SR:

8、可解释性:

QA
(待补充…)
Q:PSA?排列自注意力
Q:残差连接,密集连接(一般指全连接层),通道关注?
Q:x2 SR x4 SR ?
Q:注意力可以被视为一个低通滤波器[50,61]。为了更好地
恢复高频信息,通常在末尾添加一个conv?
A:在图像超分辨率(Super-Resolution, SR)领域,“x2 SR” 和 “x4 SR” 指的是将输入图像的分辨率分别提高到原来的2倍和4倍。具体来说:
-
x2 SR:
- x2 SR表示超分辨率技术将图像的水平和垂直分辨率都提高到原来的2倍。
- 这通常意味着图像的每个维度(宽度和高度)都增加到原来的2倍,因此整个图像的像素数量增加到原来的4倍(因为 (2 \times 2 = 4))。
- x2 SR技术可以用于改善图像细节,使图像看起来更清晰。
-
x4 SR:
- x4 SR表示超分辨率技术将图像的分辨率提高到原来的4倍。
- 这意味着图像的每个维度(宽度和高度)都增加到原来的4倍,整个图像的像素数量增加到原来的16倍(因为 (4 \times 4 = 16))。
- x4 SR是一个更具挑战性的任务,因为需要从较低分辨率的图像中恢复出更多的细节信息。
这些技术可以应用于不同类型的图像超分辨率方法中,包括基于插值的方法、基于重建的方法以及基于深度学习的方法。随着深度学习技术的发展,基于深度学习的超分辨率方法,如使用卷积神经网络(CNN)、生成对抗网络(GAN)等,已经成为提高图像分辨率的有效手段。
在实际应用中,选择合适的放大倍数(如x2、x4或其他倍数)取决于目标应用的需求和可用的计算资源。更高的放大倍数虽然可以提供更多的细节,但同时也需要更复杂的算法和更多的计算资源。此外,过高的放大倍数可能会导致图像质量下降,因此需要仔细平衡放大倍数和图像质量。
Q:非局部注意力?
Q:SwinIR[37]基于SwinTransformer编码器[41],在8 ×8局部窗口上进行特征提取的自关注,实现了极其强大的性能
Q:深度方向(depth-wise)卷积?
Q:单令牌计算量?
Q:类似多头,但不是多头,因为Q使用的是全通道信息。而K,V使用的也是通道压缩后的全通道信息,并不是部分通道。
Q:transformer远程依赖,WMSA,SWMSA?令牌采样?
Q:经典图像SR,轻量级图像SR,真实世界图像SR?
A:图像超分辨率(Super-Resolution, SR)是一种图像处理技术,旨在提高图像的分辨率,使其看起来更清晰。根据实现的复杂度和应用场景的不同,图像超分辨率技术可以分为几个不同的类别:
-
经典图像SR:
- 经典图像超分辨率技术通常指的是早期的基于插值、重建或者学习的方法。
- 这些方法可能包括最近邻插值、双线性插值、双三次插值等传统的图像放大技术。
- 经典方法也可能涉及更复杂的重建技术,如基于稀疏表示的SR,它们通过学习图像的稀疏编码来恢复高分辨率图像。
- 这些技术在理论上较为成熟,但在处理速度和效率上可能不如现代的深度学习方法。
-
轻量级图像SR:
- 轻量级图像超分辨率技术是为了在资源受限的环境中(如移动设备或嵌入式系统)实现快速且有效的图像放大。
- 这些方法通常使用深度学习模型,但模型结构设计得更为简单,参数更少,以减少计算复杂度和提高运行速度。
- 轻量级模型可能采用如ShuffleNet、MobileNet等轻量级网络结构,或者通过知识蒸馏等技术将大型模型的知识迁移到小型模型中。
-
真实世界图像SR:
- 真实世界图像超分辨率技术关注于处理实际场景中拍摄的图像,这些图像可能包含噪声、模糊、光照不均等问题。
- 这类技术不仅需要放大图像,还需要处理和纠正图像中的各种退化问题,以获得更自然和高质量的结果。
- 真实世界SR技术可能会集成多种图像处理技术,如去噪、去模糊、颜色校正等,以及使用深度学习模型来学习复杂的图像先验和退化模型。
在实际应用中,选择哪种类型的图像超分辨率技术取决于具体的应用需求、可用的计算资源以及图像的质量要求。例如,对于需要快速处理大量图像的移动应用,可能会选择轻量级图像SR技术;而对于需要极高图像质量的专业图像编辑或医学成像,可能会采用更为复杂和精细的经典或真实世界图像SR技术。随着深度学习技术的发展,基于深度学习的图像超分辨率方法已经成为研究和应用的热点。
Q:深度卷积和点卷积?
Q:通道压缩计算量没有考虑??通道压缩,使用点卷积。没有计算量???
压缩完,计算K,Q,然后执行重排列,还原通道数。再进行矩阵乘法。。。
[Ref:Zhou Y, Li Z, Guo C L, et al. Srformer: Permuted self-attention for single image super-resolution[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 12780-12791.]
















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











