










这篇博客是对论文RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching的阅读笔记。
论文地址位于paper,代码已开源,位于RAFT-Stereo。这篇文章是2021 3DV的best paper。
RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching
本文是一篇将光流算法RAFT迁移至立体匹配领域的文章,基于光流估计网络RAFT,提出了多级卷积GRU实现立体匹配的代价传播。文章对RAFT进行优化,并得到了一个高精度实时模型,能够基本保持精度,而速度很快,适合实时性场景。
1. Introduction
文章首先指出了立体匹配估计深度是计算机视觉的基础问题,而一般的立体匹配工作,重点放在特征提取、构造匹配代价,并对代价进行优化估计视差。文章指出立体匹配与光流估计是具有相似性的,他们都需要预测两张图之间像素的位移,立体匹配针对左右视角的像素偏差,而光流关注前后帧之间的像素位置变化。而二者在目标域的值存在差别,也即校正后的立体匹配图像对只在x水平方向存在便宜,而竖直方向位移均为0。
尽管两个任务具有相似性,但其方法的发展缺有很大差别。立体匹配算法大多用3D卷积神经网络,通过特征提取构造3D cost volume并使用3D卷积从cost volume计算视差图。
而光流算法则更多使用迭代优化的策略。RAFT将图像特征提取后构造cost volume,计算所有像素对之间的correlation,然后通过GRU更新算子,迭代的更新光流。
本文借鉴RAFT估计光流的思路,提出了RAFT-Stereo。考虑到视差估计只考虑水平方向(匹配点在校正图像中处在同一行),因此correlation只计算同一行的可见像素对。此外,本文提出了多级GRU单元,维持隐层在不同分辨率传递,但最终只更新最高分辨率的视差。文章认为这一点提升了更新算子在图像间传播信息的能力,提升了视差估计的全局一致性。
RAFT-Stereo与之前的立体匹配算法从本质上是不同的,跳出了对cost volume的回归得到视差图的框架,采用GRU模块迭代更新的方法从像素间相关性获取视差值。
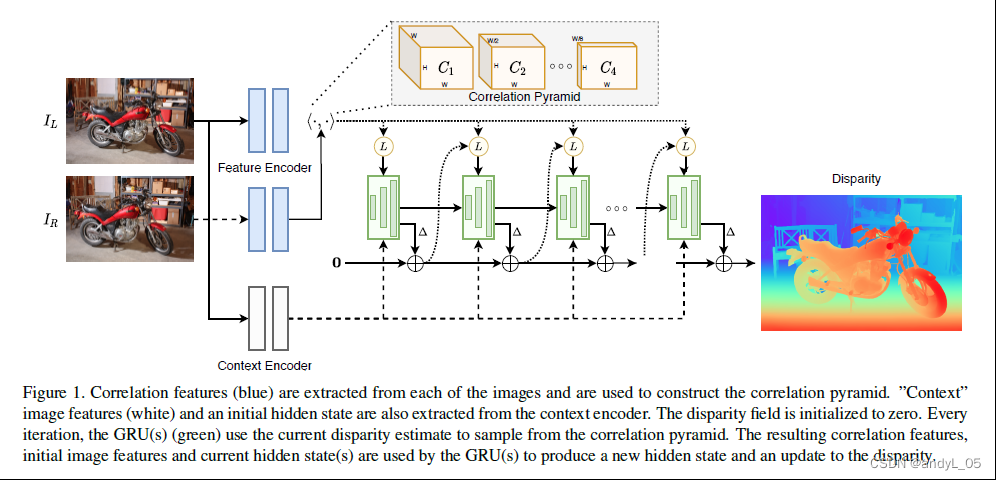
2. Approach
本文算法的目标,是基于输入的左右图像,获取其视差图。RAFT-Stereo的核心模块包括三部分:特征提取模块、相关性金字塔(correlation pyramid)以及基于GRU的更新算子。
特征提取部分:文章提出了相关性特征与语义特征分别处理的思路,因此构造了两个特征提取模块;其中一个对左右图提取特征并用于构造相关性金字塔,另一个语义特征提取模块负责提取左图的语义特征,负责初始化GRU更新算子的隐层并且在每次迭代注入到GRU。
相关性金字塔:通过对左右图逐像素提取特征并对特征向量进行点积,计算像素对之间的相关性。
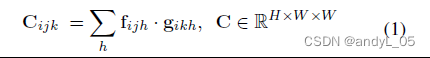
构造相关性立方体,correlation volume,实际上类似cost volume,但大家普遍将通过特征向量拼接得到的DxCxHxW的4D块称为cost volume,而通过相关性得到的DxHxW的3D块称为correlation volume。简而言之,我们需要每个像素在每个视差的匹配代价,如果这个代价表示为一个向量,就会多一个特征维度,此时一般称为cost;如果这个代价用标量表示,一般称为correlation。
本文在correlation volume基础上构造了correlation pyramid,即相关性金字塔。本文构造了4级金字塔,第k级的维度是

也即金字塔只缩减了最后一个维度。
Correlation查找模块:这部分用于从现有估计的视差图为correlation建立索引

通过现有的视差图,寻找在correlation金字塔每一层相关性的位置,并基于线性插值,得到当前视差图在每一层金字塔对应的的相关性值,这一值被用于在GRU模块更新。
多级更新算子:
模型通过迭代从初始视差(全0)预测一系列的视差图。在一次迭代中,根据当前估计的视差图从correlation volume中采样得到一系列相关性特征,经过2层卷积,当前的视差图也经过2层卷积,相关性特征、视差图(卷积后)结合语义特征,都被送入到GRU中。GRU更新隐层,隐层用来预测视差图的更新。这里与RAFT一样,GRU输出的是视差的增量(残差,delta-disp)
采用残差可能的原因是:1.残差学习,类似boost,充分发挥迭代更新的优势;2.更新模块在每一次迭代是同一个(参数共享的)如果设置为学习绝对数值可能影响参数学习,学习残差更易于更新
多隐层状态:原始raft更新是整体的,高分辨率。这会导致感受野增长缓慢,对纹理稀疏区域不利。本文提出了多分辨率更新算子,同步更新1/8, 1/16, 1/32。 GRU采用交叉连接来使用其他的隐层,查表操作和更新视差图只在最高分辨率进行。
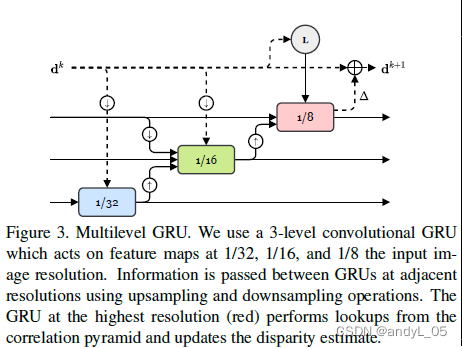
如图所示,dk表示第k次迭代得到视差图d。一次迭代分别进行小中大三个分辨率的更新,隐层也包含三个分辨率,信息在三种分辨率(3个GRU模块)的传递经过上下采样,先从小分辨率开始,得到的结果输入到中分辨率,最后到大分辨率,大分辨率同时输入了查表得到的相关性特征,并在最大分辨率更新视差增量,从而得到新一次迭代的视差图。
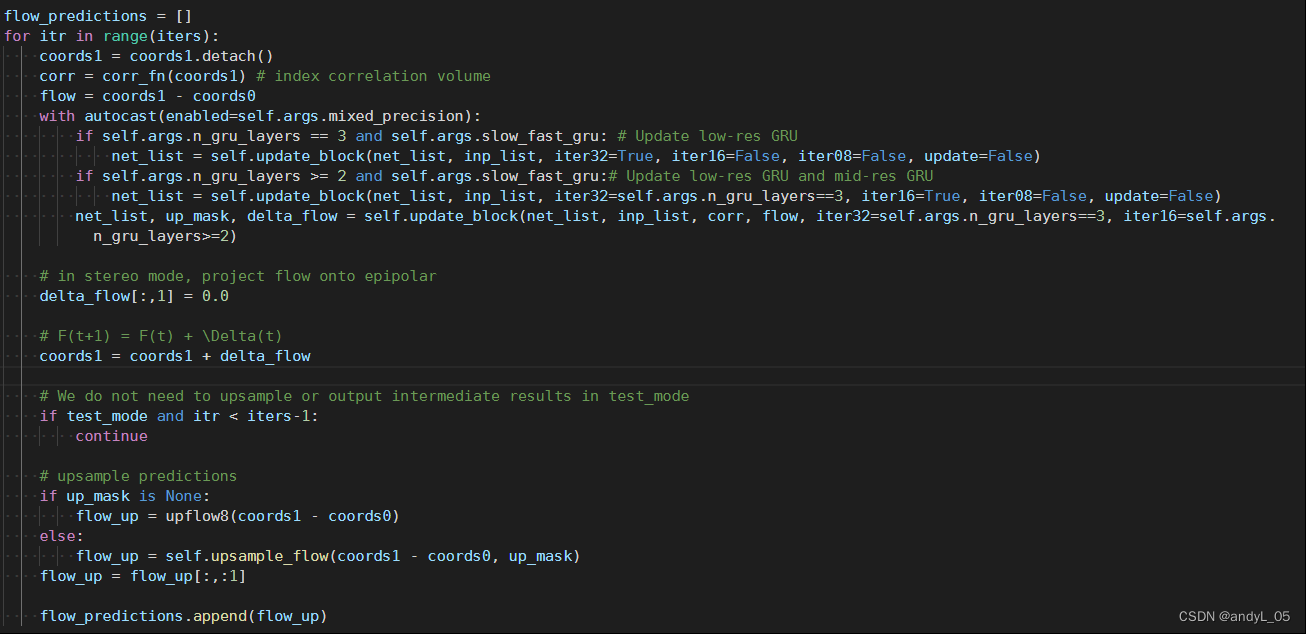 结合这部分代码来看,此处输出一个预测序列(这里仍然使用了flow,是由于代码复用未经改动,实际上本文代码是把视差当光流处理的,额外增加了一个全是0的y方向光流,其实不影响视差估计),首先基于预测结果coords1和左图基准坐标计算光流,并查表得到相关性特征corr,接下来分别进行三次更新操作,第一次1/32,第二次1/32和1/16,第三次1/32,1/16,1/8,注意corr和flow只在第三次才被使用到。实际上前两次更新是否进行是由超参数控制的,为了跑得快可以设置n_gru_layers少一些以减少低分辨率更新次数来加速,默认参数下(n_gru_layers==3)进行上述三次操作。
结合这部分代码来看,此处输出一个预测序列(这里仍然使用了flow,是由于代码复用未经改动,实际上本文代码是把视差当光流处理的,额外增加了一个全是0的y方向光流,其实不影响视差估计),首先基于预测结果coords1和左图基准坐标计算光流,并查表得到相关性特征corr,接下来分别进行三次更新操作,第一次1/32,第二次1/32和1/16,第三次1/32,1/16,1/8,注意corr和flow只在第三次才被使用到。实际上前两次更新是否进行是由超参数控制的,为了跑得快可以设置n_gru_layers少一些以减少低分辨率更新次数来加速,默认参数下(n_gru_layers==3)进行上述三次操作。
更新后的delta_flow在y方向全部置0,因为视差估计不需要这个,然后基于delta_flow更新flow。flow_up是上采样到原始尺寸,方便与GT计算loss,每一轮迭代的结果在训练阶段都输出,都计算loss并加权求和。
Slow-Fast GRU: 为了平衡时间,选择小分辨率更新多次再更新一次大分辨率,这一点代码里体现的比较清楚。如果不设置这个,根据上图的代码,只会进行三个分辨率一起更新的操作,那么三个分辨率更新次数一样。这个trick是为了保持精度下尽可能减少高分辨更新次数。
损失函数:
预测的光流序列分别计算L1loss并加权,权重取决于所在迭代的次数
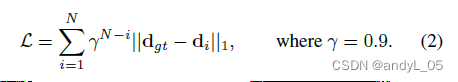
实验
实验部分不在此详述,简单来说,精度达到了SOTA,而且提供了一些超参调整策略,实现了在KITTI数据集上的26FPS(实时)且精度下降不多。
文中的GRU迭代更新次数,在训练和测试阶段是可以分别设置的,参考源码github的readme提供的样例,训练阶段设置更新32次,而测试阶段设为7,依然可以保持比较好的精度,而提高预测速度。
小结
整体而言,本文将光流估计采用较多的迭代更新方法应用于视差估计,通过卷积GRU模块以及多分辨率的设置,迭代更新预测的视差结果,从而达到高精度的效果。文章提出的多尺度GRU更新策略,对于算法的加速非常有意义,通过使用小分辨多更新、大分辨率少更新的策略,保持精度的同时提升了速度。
这种迭代更新的方法应用于立体匹配与视差估计,与主流的立体匹配方法有显著的区别,让人眼前一亮,也是一种非常好的思路。

















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









