






1、书名:Mastering OpenCV with Practical Computer Vision Projects
2、章节:Chapter 3:Marker-less Augmented Reality
3、书中源代码的最新更新可以参考网址:https://github.com/MasteringOpenCV/code
匹配过程中有什么麻烦么?
有,就是有不匹配的问题。是的,这源自于图片大小,旋转角度、光照情况、图片的聚焦等一系列事件引发的匹配事故。如何解决,目前AR/MR的工作者仍在研究,只是已经取得了相对良好的测试结果,达到满足广大普通需求的一种状况。光学和机器视觉方面的研究是技术攻关的瓶颈。
回到上一篇的结尾,我们省略的地方。这里就是通过随机采样一致性(RANSAC)方法对匹配过程中的特征点对进行过滤,找到一个精确的单应性矩阵,这个单应性矩阵可以矫正摄像机实时采集的图片,矫正标记图在虚拟世界中的方向角度,从而确定它的准确位置。在下面的代码中使用了两次refineMatchesWithHomography对单应性的计算,分别得到了粗糙的单应性矩阵和精确的单应性矩阵。精确的单应性矩阵是通过根据粗糙的单应性矩阵对图片进行透视变换,从而得到了辨识度更准确的特征点并检测出精确的单应性矩阵。
//在image中查找模式信息,如果找到返回真 bool PatternDetector::findPattern(const Mat &image, PatternTrackingInfo &info)//查找模式信息 { //转成成灰度图 getGray(image, m_grayImg);//获取灰度图 extractFeatures(m_grayImg, m_queryKeypoints, m_queryDescriptors); //从灰度图中获取关键点和描述信息 getMatches(m_queryDescriptors, m_matches); //获取匹配 Mat tmp = image.clone(); //克隆一张相机图 bool homographyFound = refineMatchesWithHomography( //查找单映射矩阵 m_queryKeypoints, //查询集的关键点 m_pattern.keypoints, //模式图像的关键点 homographyReprojectionThreshold, //阈值3 m_matches, //匹配结果 m_roughHomograhy ); if (homographyFound)//如果找到8个以上的匹配点 { if (enableHomographyRefinement) //如果要进行更加精细的单映射矩阵计算,用户决定 { warpPerspective(m_grayImg, m_warpedImg, m_roughHomograhy, m_pattern.size, cv::WARP_INVERSE_MAP | cv::INTER_CUBIC); //将相机的灰度图根据单映射矩阵进行透视变换 vector<KeyPoint>warpedKeypoints; //透视变换的关键点 vector<DMatch>refinedMatches; //匹配点 //从透视变换图中提取关键点和特征向量描述 extractFeatures(m_warpedImg, warpedKeypoints, m_queryDescriptors); //将这个特征向量和识别图的特征向量做匹配 getMatches(m_queryDescriptors, refinedMatches); homographyFound = refineMatchesWithHomography( warpedKeypoints, //透视变换后图的关键点 m_pattern.keypoints, //识别图的关键 homographyReprojectionThreshold, //阈值3 refinedMatches, //匹配的点集 m_refinedHomography //单映射矩阵 ); info.homography = m_roughHomograhy*m_refinedHomography; // //将粗超的单映射矩阵和精细的单映射矩阵相乘,把这个矩阵作为总的单映射矩阵 perspectiveTransform(m_pattern.points2d, info.points2d, m_roughHomograhy); //使用单应性矩阵透视变换将第一个点集转换为第二点集 cv::perspectiveTransform(m_pattern.points2d, info.points2d, m_roughHomograhy); info.draw2dContour(tmp, CV_RGB(0, 200, 0)); cv::perspectiveTransform(m_pattern.points2d, info.points2d, info.homography); info.draw2dContour(tmp, CV_RGB(200, 0, 0)); } else { info.homography = m_roughHomograhy; //使用粗超变换矩阵 //对识别图的四个顶点做映射变换 cv::perspectiveTransform(m_pattern.points2d, info.points2d, m_roughHomograhy); info.draw2dContour(tmp, CV_RGB(0, 200, 0));//绘制这四个点 } } return homographyFound; //返回能否找到单映射矩阵 }
寻找单应性矩阵就在这里,它通过opencv的findHomography函数计算得到的;
//寻找单应性变换 bool PatternDetector::refineMatchesWithHomography(const vector<KeyPoint>& queryKeypoints, const vector<KeyPoint>&trainKeyPoints, float reprojectionThreshold, vector<DMatch>&matches, Mat &homography) { const int minNumberMatchesAllowed = 8; //允许匹配的最小数量 if (matches.size()<minNumberMatchesAllowed) //数量过小返回 return false; //准备数据存储映射矩阵 vector<Point2f>srcPoints(matches.size()); //保存原图点中和当前动态图匹配的点 vector<Point2f>dstPoints(matches.size()); for (size_t i = 0; i<matches.size(); i++) //将匹配的点找出来 { srcPoints[i] = trainKeyPoints[matches[i].trainIdx].pt; dstPoints[i] = queryKeypoints[matches[i].queryIdx].pt; } vector<unsigned char>inliersMask(srcPoints.size()); //内层mask homography = findHomography(//在原平面和目标平面之间返回一个单映射矩阵(类似仿射变换中变换矩阵) srcPoints, //(识别图)原图中匹配的点集 dstPoints, //相机图中匹配的点集 CV_FM_RANSAC, //采用随机采样一致性算法 3, //最大容忍重投影误差 inliersMask //输出矩阵这里使用无符号char类型数组来保存 ); vector<DMatch>inliers; //匹配 for (size_t i = 0; i<inliersMask.size(); i++) //遍历数组 { if (inliersMask[i]) inliers.push_back(matches[i]); //按照单映射矩阵的大小提取一些匹配点 } matches.swap(inliers); //将两个数组内容交换matche中存储当前的匹配集合 return matches.size()>minNumberMatchesAllowed; //返回时候大于8个点 }
到这里计算出来标记图在虚拟世界中的位置信息,可以在屏幕中显示出来位置信息,也表示知道了标记图在虚拟世界中的坐标系。接下来就可以完成在实时图片上调用opengl绘制三维物体的任务了。
单应性矩阵
参考第一个博文吧,我找不到公式编辑器。。
RANSAC算法步骤:
1. 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出变换矩阵H,记为模型M;
2. 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3. 如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4. 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
注:迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的;
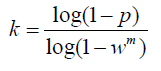
其中,p为置信度,一般取0.995;w为"内点"的比例 ; m为计算模型所需要的最少样本数=4;

RANSAC算法的输入是一组观测数据(往往含有较大的噪声或无效点),一个用于解释观测数据的参数化模型以及一些可信的参数。RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
- 有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
- 用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
- 如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
- 然后,用所有假设的局内点去重新估计模型(譬如使用最小二乘法),因为它仅仅被初始的假设局内点估计过。
- 最后,通过估计局内点与模型的错误率来评估模型。
- 上述过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
RANSAC算法用作配准
模型对应的是空间中一个点云数据到另外一个点云数据的旋转矩阵以及平移向量。
RANSAC算法成立的条件里主要是先要有一个模型和确定的特征,用确定的特征计算模型的具体参数
三维模型的加载,以后弄清再更。
参考博文:
https://www.zhihu.com/question/23310855
http://blog.csdn.net/luoshixian099/article/details/50217655
http://blog.sina.com.cn/s/blog_7a936e3b0102vctz.html















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









