







简介
提出了可端到端训练的音视语音识别模型,输入waveform和唇部的每一帧,音视各通过一个conformer encoder后concat并FC得到融合特征,最后是transformer decoder。端到端训练比分开训练好;当信噪比较低时,waveform比fbank效果好
论文的任务/贡献
提出了端到端的音视语音识别模型,从waveform和图像接受收入进行训练。
所提方法
网络结构
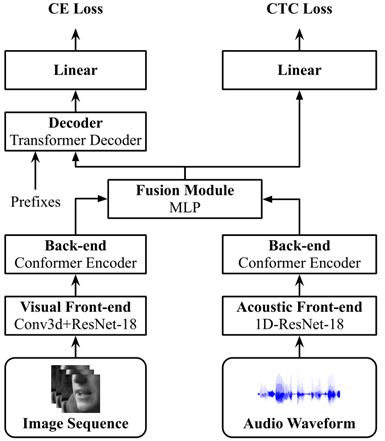
包含front-end、back-end和fusion modules。
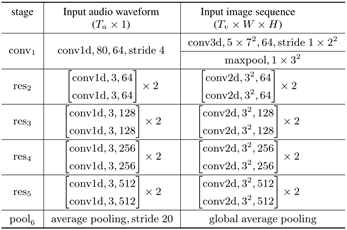
Front-end:视觉使用了将第一卷积层替换为核大小为5×7×7的3D卷积的ResNet18网络,最后使用了GAP;音频使用了基于1D卷积的ResNet18的网络,第一层滤波器尺寸为80(5ms),第一个block下采样4倍,随后每个block下采样2倍。最后声学特征下采样至每秒25帧以匹配视觉特征。
Back-end:将resnet特征投影到dk维空间,使用相对位置信息(Transformer-XL: Attentive language models beyond a fixed-length context)编码后送入conformer encoder
融合层:串接back-end输出的声学和视觉特征通过MLP投影到
d
k
d_k
dk维空间。MLP是一层线性投影层,输出
4
×
d
k
4×d_k
4×dk维特征,随后是BN、ReLU和最终线性层,输出维度
d
k
d_k
dk。
解码器:有embedding模块和一组MHSA组成。embedding模块中,一串从1到l-1的索引前缀被投影到embedding向量,l是目标长度索引。为embedding添加了绝对位置编码(sin)。随后是两个注意力模块和FFN模块,将来位置上的注意力矩阵被盖上了掩膜,第一个自注意力模块是Q=K=V,第二个是之前自注意力模块的输出作为Q,encoder输出的表征作为K和V。
语言模型:基于transformer的语言模型,epoch=10,把数据集transcription中的一千六百二十万个词用来训练。通过浅层融合合并来自语言模型的加权先验分数,如下所示。
y
^
\hat{y}
y^是目标符号的一组预测值。λ是在解码阶段的相对CTC权重,
β
β
β是语言模型的相对权重。在本文中,
λ
=
0.1
λ=0.1
λ=0.1,
β
=
0.6
β=0.6
β=0.6
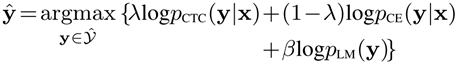
损失函数
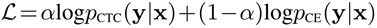
实施
数据
预处理:使用dlib检测并跟踪了68个脸部landmark,使用相似变换将脸对齐到一个参考帧中。使用96×96的框来裁取嘴部RoI,转灰度图并依照训练集均值和方差进行正则化。waveform也进行了正则化。
数据增强:图像进行88×88范围的随机裁剪,0.5概率的水平翻转,音频添加了噪声、时间掩膜、时域上带阻滤波(band reject filtering)。添加了NOISEX中的低语噪声,信噪比从-5到20dB。通过均匀分布选择噪音水平或使用干净waveform。将最大长度为0.4秒的2组连续音频样本设置为零,并拒绝最大宽度为150 Hz的2组连续频带。在纯音频实验中,将速度设置在0.9到1.1之间来增加速度扰动。
训练
音视编解码器:除encoder的front-end模块外随机初始化,front-end模块使用了LRW预训练模型。back-end模块使用了e= 12,dff= 2048,dk= 256,dv= 256这组超参数,e代表conformer块,仅视觉模型的head=4,纯音频或音视模型为8,每个卷积层的核尺寸为31。transformer解码器使用了6个自注意力块。
Adam:β1= 0.9,β2= 0.98,ϵ= 10−9,batch-size是8。学习率在前25000步线性增加,到达1e-4后与步数成平方根倒数成比例减小。epoch=50
结果
纯视觉:从头训练时,端到端训练比先提取视觉特征然后送入back-end训练提升了12.6%;使用视觉预训练模型又提升了4.7%,将LSTM编解码器替换为conformer编码器transformer解码器提升了3.8%,将RNN语言模型替换为transformer提升了4.5%

纯语音:LRS2使用FBank与waveform的结果相似。当加入噪声后,随着信噪比降低,waveform好于FBank,且差距逐渐增大,在-5dB时达到7.5%的提升。
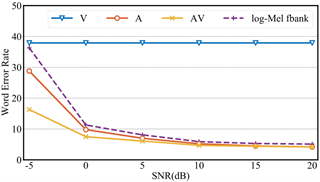
音视:LRS2无噪音时比纯语音略好,但是随着信噪比降低,音视与纯音频的差距逐渐增大。















 2279
2279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









