







简介
使用唇部图像、音频进行音视融合语音识别任务。其中图像使用了3D卷积提取的特征,语音使用了语谱图。使用了相同的transformer encoder,decoder方面比较了seq2seq和CTC两种方案,结果显示在无噪音情况下seq2seq表现更佳,有噪音时CTC表现更佳。使用额外的语言模型也有助于提升WER
论文的任务/贡献
(1)比较了使用Connectionist Temporal Classification(CTC)损失和使用序列对序列(seq2seq)损失的两种唇读模型。这两个模型都建立在transformer自注意力架构之上;
(2)研究唇读与语音识别在多大程度上是互补的,尤其是在音频信号有噪声的情况下
背景
CTC
该方法将声音序列输入神经网络并输出各个token的概率,随后送入HMM中用来解码,CTC是其变种,模型预测帧级标签并寻找帧级预测和输出序列之间的最优对齐。缺点:1.输出标签相互独立,需要语言模型做后处理;2.它假设输入和输出序列是单调的。
在语音识别任务中,由于每个人的语速不一致,如果训练时不进行对齐(对齐有时十分困难的),则模型难以收敛。给定训练集,语音序列X=[x1, x2, …, xT]和标签Y=[y1, y2, …,yU], X和Y的长度会变化且不相等,CTC主要解决该问题。对于一个给定的输入序列X,CTC给出所有可能的Y的输出分布,根据该分布给出某个输出的概率。
损失函数:给定输入序列X,最大化Y的后验概率P(Y|X)
测试:
Y
∗
=
a
r
g
m
a
x
Y
P
(
Y
∣
X
)
Y^* = argmax_YP(Y|X)
Y∗=argmaxYP(Y∣X)
seq2seq
首先读完整个输入序列再预测句子。其当前输出是根据之前的输出来确定的。模型根据token隐式的学习了语言模型,无需后处理,结合外部语言模型仍有助于模型解码。
所提方法
网络结构
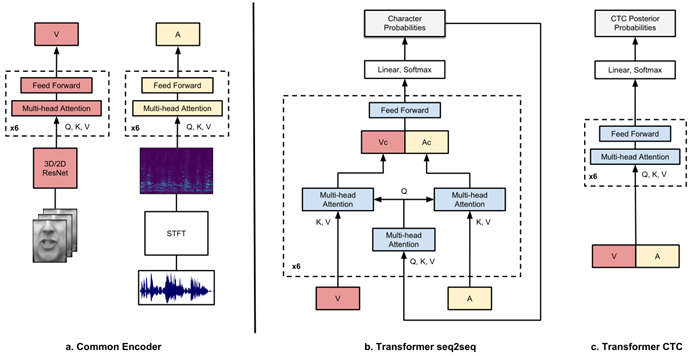
seq2seq transformer
使用不同的注意力头来关注视频和音频embedding,在每个解码层,沿通道维度串接结果视频和音频上下文,送入FFN中。两种模态的注意力将前一个解码层的输出(在第一层时,以解码器的input作为输入)作为query来接收。解码器输出每个字的概率,可以与GT标签直接匹配,使用CE loss来训练。使用了额外的[sos] token
CTC-Transformer
将视频和音频concatenate,与encoder一样。网络输出是每个输入帧的CTC posterior 概率,使用CTC损失来训练。使用了额外的[blank] token
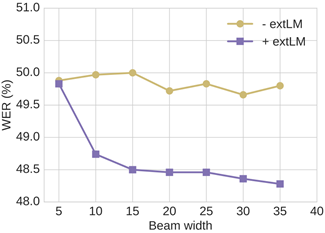
额外语言模型
为了解码,使用了4层LSTM,每层1024个单元。将LM对数概率通过浅融合与模型输出相结合,最后使用从左到右的beam搜索对两个模型进行解码
损失函数
seq2seq使用CE loss,CTC使用CTC loss
实施
训练
四个训练阶段:1.训练视觉前端模块;2.使用视觉模块为训练数据生成视觉特征;3.在冻结的视觉特征上训练序列处理模块;4.对网络端到端训练
课程训练
当时间步数较大时,seq2seq学习收敛非常缓慢,因为解码器最初很难从所有输入步中提取相关信息。提出一种新策略,开始只训练单个词语,然后让序列长度随着网络的训练而增长。这些短序列是数据集中较长的句子的一部分。收敛快,减少了过拟合,大概是因为它作为一种自然的数据增强方式工作。
测试
使用了9种随机变换(对视频帧水平翻转,最大±5像素的空间位移)
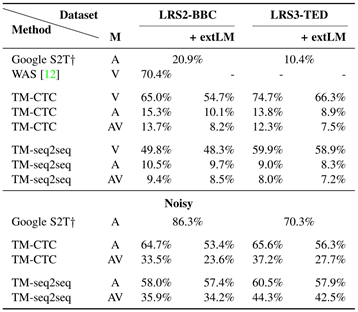
结果
在安静环境下seq2seq效果更好,但是在嘈杂的情况下CTC要优于seq2seq。
CTC比seq2seq要更容易训练,且推理速度更快
语言模型对两种模型都有增益,其中CTC增益更高















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









