







Yann LeCun - Self-Supervised Learning: The Dark Matter of Intelligence
https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/
1、自监督学习试图从数据集自身构建监督任务并自动生成对应任务的标注数据,从而解决有监督学习需要大量人工标注的问题。
2、在自然语言处理中,
- GPT3 采用基于之前语句的文字预测未来语句文字的方式构建监督任务,并原始语句中后续的文字作为监督信号
- BERT 采用擦除语句中某个文字(mask 掩码)的方式构建监督任务,并通过 masked 的原始文字作为监督信号
3、而对于视觉任务,有别于 NLP 的 uncertainty less,dim low,discrete,自然的思路是构建隐式双塔模型,希望两个模型基于两张图片得到相似的特征或不相似的特征。不过这里面有个根本性的问题:框架存在一个普适解,即将所有输入映射为同一特征,从而偏离原始初衷。
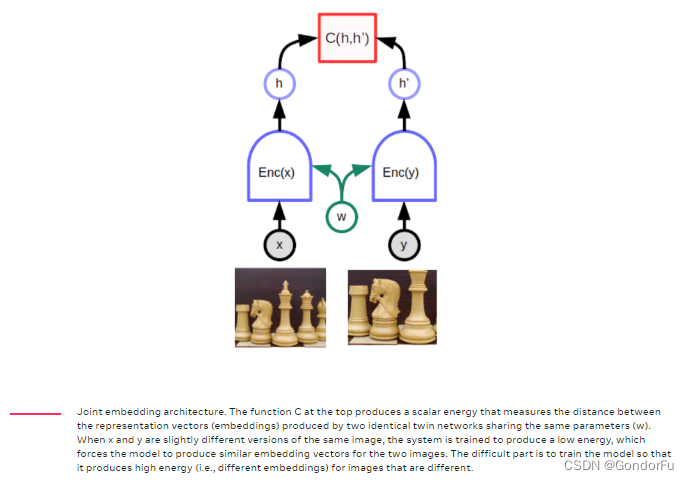
4、为解决这一问题,一个常见的思路是对比学习,即通过构建负例来避免上述问题。
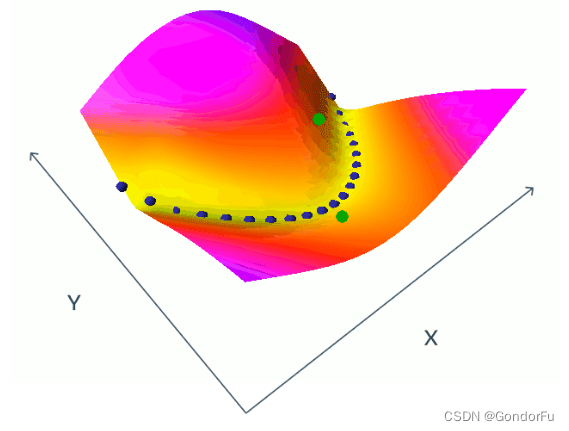
像上图中显示的那样,蓝色的点类似于锚点的作用,强制要求像素不同但是语义相同的样本具有相同的特征;同时要求其他语义不同的点具有不同的特征;而通过随机采样负例(绿点)的方式提升不同语义下提取特征的差异。但负例的选取同样困难,简单的负例作用不大,难的负例又需要附加的逻辑进行挖掘;且需要更长的训练时间。
SimCLRv2: Big Self-Supervised Models are Strong Semi-Supervised Learners
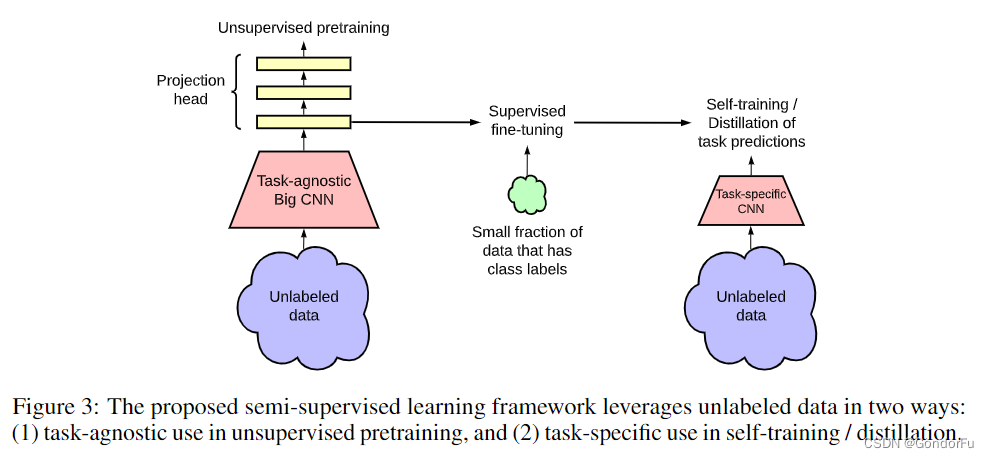
这篇文章比较早,仍然使用了类似的思路:首先使用无标注数据基于不同的数据增强获取不同但语义相同的图像并通过对比学习进行自监督训练;然后通过少量标注数据对自监督结果进行监督训练;最后通过知识蒸馏或者自学习的方法得到最终的部署模型。
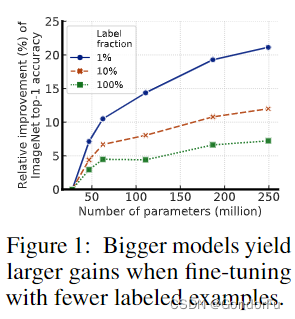
文中的这张图很有意思,图中内容并不是说使用相同的训练方式但是更少的标注数据能够获取更好的性能。而是说基于更少的标注数据,如果使用更大的模型将带来更大的性能增长,比如使用1%的标注数据,如果模型大小从ResNet50到ResNet101,性能将从0.5提升到0.55;但是使用5%的标注数据,性能只能从0.6提升到0.62。
不过上述方法难例的挖掘始终是个绕不过的问题。因此就有了不基于负例(对比学习)的自监督探索。
BYOL: Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
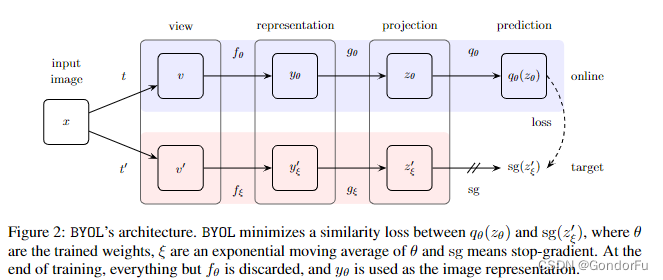
文章的整体逻辑十分简单,通过对同一张图像施加两个不同的数据增强,之后分别输入两个结构相同,参数 EMA 的孪生网络中,得到高度特征后通过两个结构相同但是参数不同的全连接网络进行降维,最后通过一个映射将某个降维后的特征与另一个降维后的特征进行对齐。
网络并不需要负例,也没有针对模式坍塌做特殊处理,整体结果及其简洁但十分有效,work 的原因暂没有一个很好的解释,只能说 EMA 让模型更容易去收敛到一个有效的特征表示。
DINO: Emerging Properties in Self-Supervised Vision Transformers
DINO 与 BYOL 的思想很类似,同样使用孪生网络,不用于 BYOL 使用 MLP 对齐两个特征,DINO 借鉴知识蒸馏的方法,对提取的特征使用不同的温度进行蒸馏,然后 softmax 后直接对齐,也获得了很好的图像特征,并通过注意力可视化进行了解释。
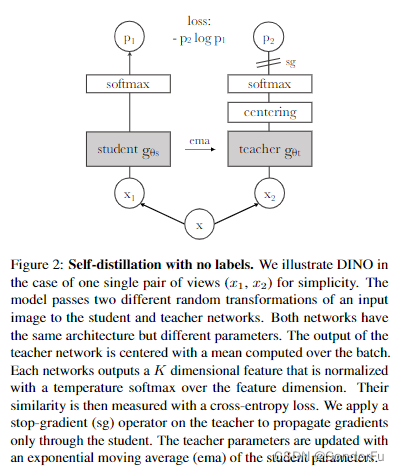
同时随着 MAE 的出现,基于掩码图像建模(Masked Image modeling, MIM)的方式慢慢成为当前自监督学习的主流。
MAE: Masked Autoencoders Are Scalable Vision Learners
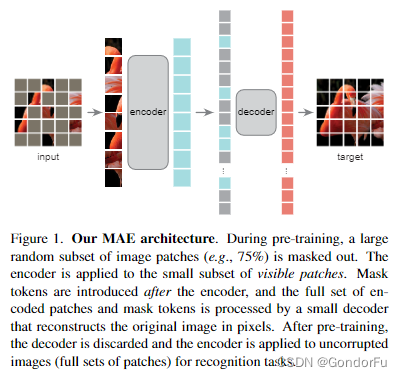
论文整体的思想十分简单:首先将图像分块并 mask 75% 的块,之后将保留的块输入的 ViT 类似的编码其中得到对应的特征,之后结合 mask 的特征将所有块的特征送入 decoder 中进行原始图像的恢复,从而构建自监督学习任务进行自监督训练。
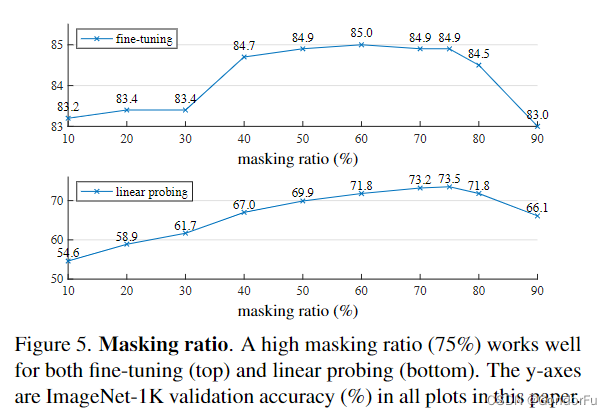
其中 mask 的比例作为一个重要的超参数在上图中给出了对比实验结果。
CAE: Context AutoEncoder for Self-Supervised Representation Learning
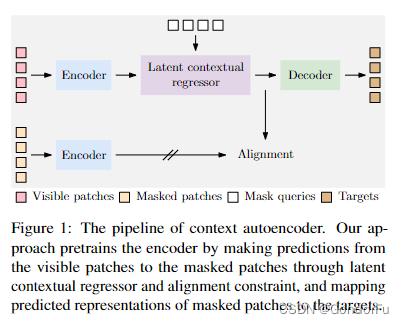
CAE 的方法与 MAE 极其类似, CAE 设计的核心思想是对 “表征学习” 和 “解决 pretext task” 这两个功能做分离。通过将 masked patches 直接经过 encoder 得到的特征对齐由 visible patches 得到的特征从而使两者的输出在同一个编码空间中;同时,decoder 只对输入 masked patches 并对齐进行恢复;两方面保证了表征学习的任务全部落到了 encoder 的身上,从而得到更好的表征学习结果。
Dr. ISHAN MISRA - Self-Supervised Vision Models: https://www.youtube.com/watch?v=EXJmodhu4_4&t=1013s
Yann LeCun - Self Supervised Learning | ICLR 2020: https://www.youtube.com/watch?v=8TTK-Dd0H9U















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









