







在看这张之前,最好看看我写的动态规划详解,里面都是讲理论基础,我下面的分析都是在此基础上进展的。
给定一个由n个互异的关键字组成的序列K = (k1, k2, ……, kn),且关键字有序(因此有k1 < k2 < …… < kn),从这些关键字中构造一棵二叉查找树。对每个关键字ki, 一次搜索为ki的概率是pi。某些搜索的值可能不在K内,因此还有n + 1个“虚拟键”d0, d1, d2, ……dn代表不在K内的值,且ki ≤ di ≤ k(i+1),di概率为qi。
因为搜索每个关键字的概率不同,因此最优二叉查找树即一棵期望搜索代价最小的二叉查找树。
从下图a), b)中可以看出,最优二叉查找树并不是高度最低的树,因为第一棵树期望是2.80,而第二棵是2.75。公式(15.10)显而易见。
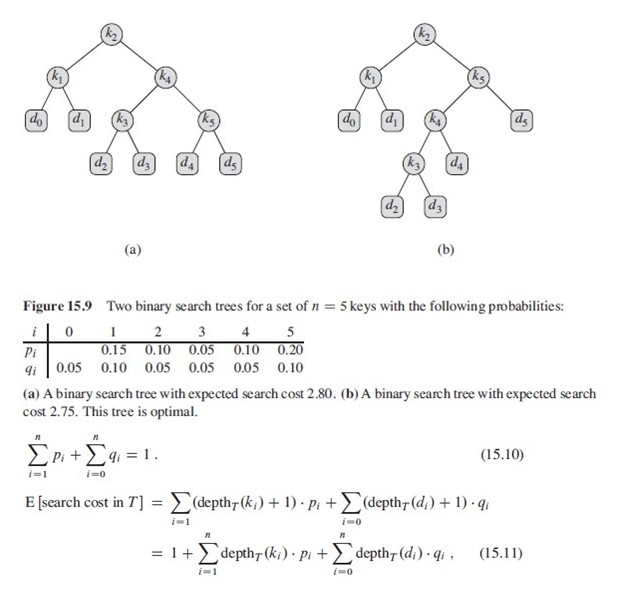
假设一次搜索的实际代价为检查的结点个数,亦即,在T内搜索所发现的结点的深度加上1(这里深度从0开始算), 所以一次搜索的期望代价为公式(15.11),期望 = 深度 * 概率。
下面依旧用DP的四个步骤来分析:
①.描述最优解的结构。
基本原则:从n下手
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









