







self-attention来自nlp的研究中,在深度学习视觉领域有不少新的attention版本,为了解各种attention机制。博主汇集了6篇视觉领域中attention相关的论文,分别涉及DAnet(位置注意+通道注意)、CBAM(通道注意+空间注意)、Attention U-Net(注意Gate)、SAGAN(self-attention)、CCNet(交叉self-attention)、ISSA(Long-range self-Attention + Short-range self-Attention )、Efficient Attention、spatial-reduction attention。并简单描述了这些attenton的运算流程,总结了其在论文中的有益效果。
2022.9.22:补充segformer中的Efficient Self-Attention
self-attention的简单描述
包含Q K V 三个映射集,attention-map为 s o f t m a x ( K ( x ) T ∗ V ( x ) ) softmax(K(x)^T*V(x)) softmax(K(x)T∗V(x))
k.shape: (B,C,N)
V.shape: (B,C,N)
attention-map: (B,N,N),其中(N=W*H)
计算结果为 attention-map*Q(x)。
Dual Attention Network for Scene Segmentation
2018年 论文地址:https://arxiv.org/abs/1809.02983.pdf
csdn论文简读地址: https://blog.csdn.net/MJ17709005513/article/details/123774860
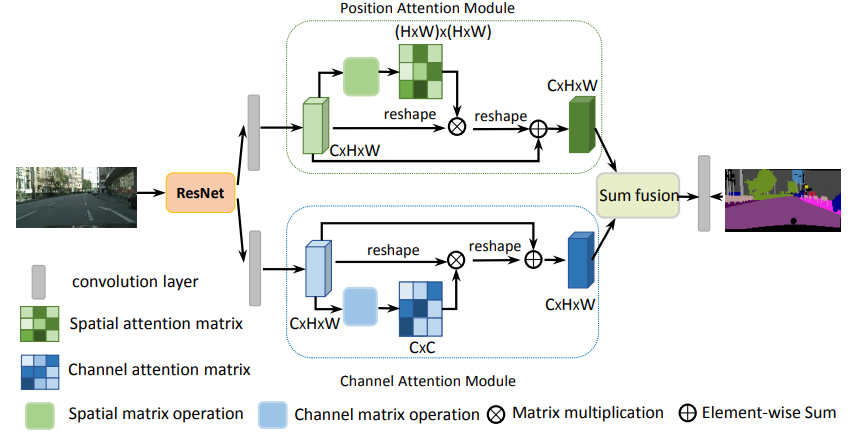
位置注意模块
BCD均为CBR模块
计算方法:
初始化各个block的weight
W
b
=
c
o
n
v
_
b
n
_
r
e
l
u
W
c
=
c
o
n
v
_
b
n
_
r
e
l
u
W
d
=
c
o
n
v
_
b
n
_
r
e
l
u
W_b=conv\_bn\_relu \\ W_c=conv\_bn\_relu \\ W_d=conv\_bn\_relu
Wb=conv_bn_reluWc=conv_bn_reluWd=conv_bn_relu
计算过程,输入为x,输出为out
b
=
W
b
(
x
)
;
(b,c,w,h)
c
=
W
c
(
x
)
;
(b,c,w,h)
d
=
W
d
(
x
)
;
(b,c,w,h)
b
=
r
e
s
h
a
p
e
(
b
)
;
(b,c,n)
c
=
r
e
s
h
a
p
e
(
c
)
;
(b,c,n)
d
=
r
e
s
h
a
p
e
(
d
)
;
(b,c,n)
b
c
=
b
m
m
(
b
T
,
c
)
;
(b,n,n)
s
=
s
o
f
t
m
a
x
(
b
c
)
a
t
t
n
_
v
a
l
=
b
m
m
(
s
,
d
)
;
(b,c,n)
a
t
t
n
_
v
a
l
=
r
e
s
h
a
p
e
(
a
t
t
n
_
v
a
l
)
;
(b,c,w,h)
o
u
t
=
a
t
t
n
_
v
a
l
+
x
;
(b,c,w,h)
b=W_b(x) ;\text{ (b,c,w,h)} \\ c=W_c(x) ;\text{ (b,c,w,h)} \\ d=W_d(x) ;\text{ (b,c,w,h)} \\ b=reshape(b) ;\text{ (b,c,n)} \\ c=reshape(c) ;\text{ (b,c,n)} \\ d=reshape(d) ;\text{ (b,c,n)} \\ bc=bmm(b^T , c) ;\text{ (b,n,n)} \\ s=softmax(bc) \\ attn\_val=bmm(s,d) ;\text{ (b,c,n)} \\ attn\_val=reshape(attn\_val ) ;\text{ (b,c,w,h)} \\ out=attn\_val+x ;\text{ (b,c,w,h)} \\
b=Wb(x); (b,c,w,h)c=Wc(x); (b,c,w,h)d=Wd(x); (b,c,w,h)b=reshape(b); (b,c,n)c=reshape(c); (b,c,n)d=reshape(d); (b,c,n)bc=bmm(bT,c); (b,n,n)s=softmax(bc)attn_val=bmm(s,d); (b,c,n)attn_val=reshape(attn_val); (b,c,w,h)out=attn_val+x; (b,c,w,h)

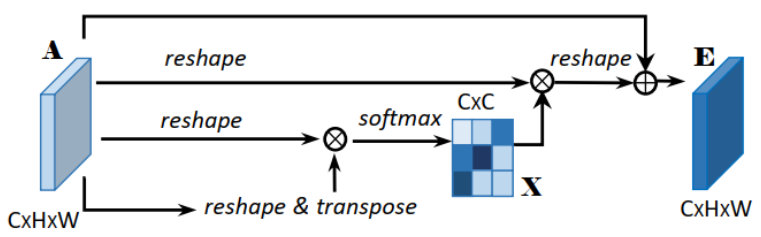
通道注意模块
通道注意模块没有引入新的参数,是直接对数据进行reshape与Efficient Attention存在不同
计算过程,输入为x,输出为out
a
=
r
e
s
h
a
p
e
(
x
)
;
(b,c,n)
a
=
b
m
m
(
a
,
a
T
)
;
(b,c,c)
s
=
s
o
f
t
m
a
x
(
a
)
a
t
t
n
_
v
a
l
=
s
∗
x
;
(b,c,n)
a
t
t
n
_
v
a
l
=
r
e
s
h
a
p
e
(
a
t
t
n
_
v
a
l
)
;
(b,c,w,h)
o
u
t
=
a
t
t
n
_
v
a
l
+
x
;
(b,c,w,h)
a=reshape(x) ;\text{ (b,c,n)} \\ a= bmm(a,a^T) ;\text{ (b,c,c)} \\ s=softmax(a) \\ attn\_val=s*x ;\text{ (b,c,n)} \\ attn\_val=reshape(attn\_val ) ;\text{ (b,c,w,h)} \\ out=attn\_val+x ;\text{ (b,c,w,h)} \\
a=reshape(x); (b,c,n)a=bmm(a,aT); (b,c,c)s=softmax(a)attn_val=s∗x; (b,c,n)attn_val=reshape(attn_val); (b,c,w,h)out=attn_val+x; (b,c,w,h)
具体用法
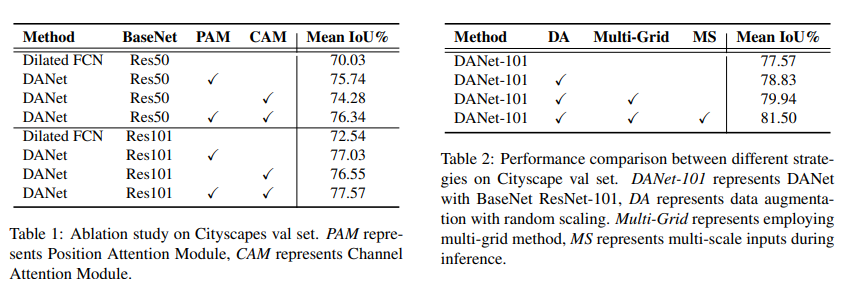
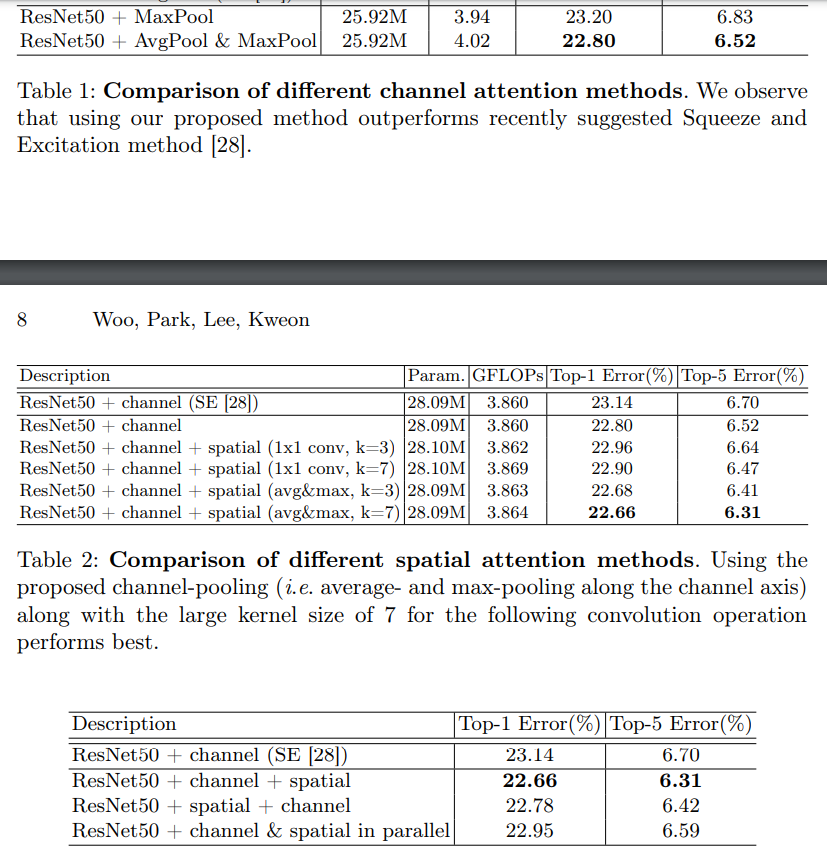
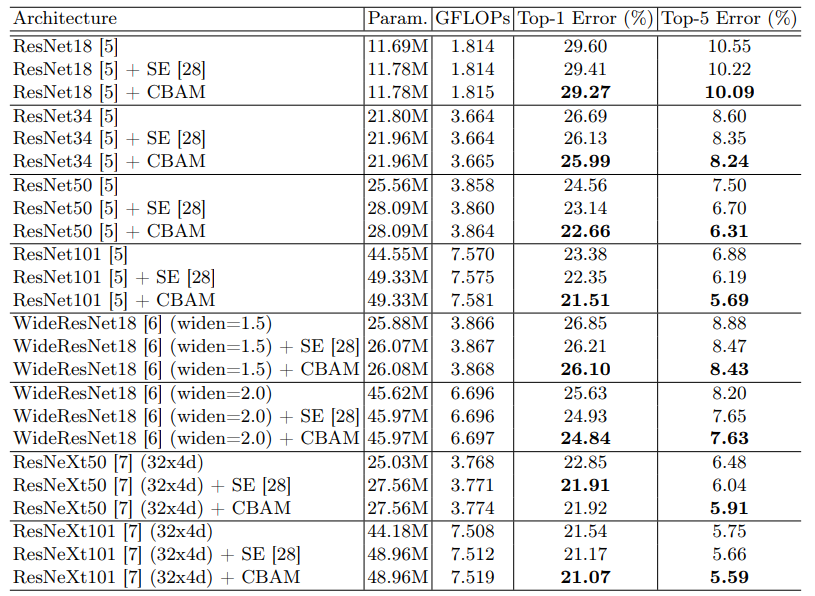
消融实验
CBAM: Convolutional Block Attention Module
2018年 论文地址:https://arxiv.org/abs/1807.06521 csdn论文简读地址:https://blog.csdn.net/ITOMG/article/details/88804936
CBAM block
先对feature map做通道上的attention(将atten_val与feature map相乘),在做空间上的attention(将atten_val与feature map相乘)
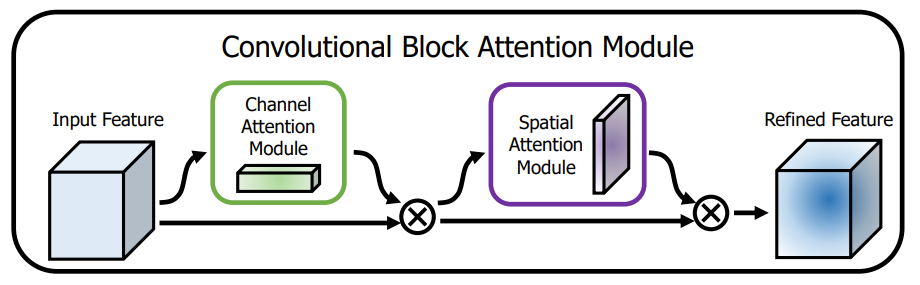
Chanel Attention Module
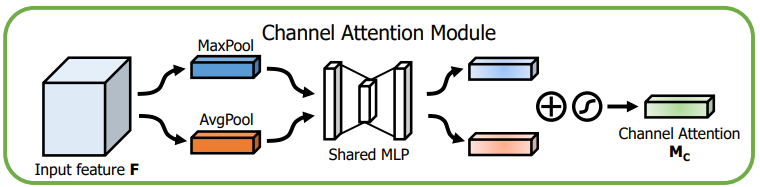
计算方法:
初始化模块weight
M
L
P
=
f
c
1
_
f
c
2
_
f
c
3
MLP=fc1\_fc2\_fc3
MLP=fc1_fc2_fc3
计算过程,输入为x,输出为out。
a
v
g
=
G
l
o
b
a
l
A
v
g
P
o
o
l
(
x
)
;
(b,c,1,1)
m
a
x
=
G
l
o
b
a
l
M
a
x
P
o
o
l
(
x
)
;
(b,c,1,1)
a
v
g
=
M
L
P
(
a
v
g
)
;
(b,c,1,1)
m
a
x
=
M
L
P
(
m
a
x
)
;
(b,c,1,1)
o
u
t
=
s
i
g
m
o
i
d
(
m
a
x
+
a
v
g
)
;
(b,c,1,1)
avg=GlobalAvgPool(x) ;\text{ (b,c,1,1)} \\ max=GlobalMaxPool(x) ;\text{ (b,c,1,1)} \\ avg=MLP(avg) ;\text{ (b,c,1,1)} \\ max=MLP(max) ;\text{ (b,c,1,1)} \\ out=sigmoid(max+avg) ;\text{ (b,c,1,1)} \\
avg=GlobalAvgPool(x); (b,c,1,1)max=GlobalMaxPool(x); (b,c,1,1)avg=MLP(avg); (b,c,1,1)max=MLP(max); (b,c,1,1)out=sigmoid(max+avg); (b,c,1,1)
这里输出的只是一个attention map,并不是做完attention后输出的值。
Spatial Attention Module
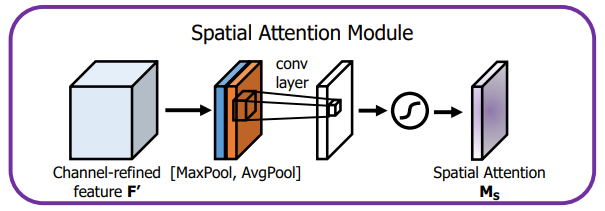
计算方法:
初始化模块weight
C
o
n
v
=
c
o
n
v
(
2
,
1
,
k
s
i
z
e
=
3
,
p
a
d
d
i
n
g
=
1
,
b
i
a
s
=
N
o
n
e
)
Conv=conv(2,1,ksize=3,padding=1,bias=None)
Conv=conv(2,1,ksize=3,padding=1,bias=None)
计算过程,输入为x,输出为out。
a
v
g
=
A
v
g
P
o
o
l
(
x
,
d
i
m
=
1
)
;
(b,1,w,h)
m
a
x
=
M
a
x
P
o
o
l
(
x
,
d
i
m
=
1
)
;
(b,1,w,h)
c
a
t
=
c
o
n
c
a
t
(
[
a
v
g
,
m
a
x
]
,
d
i
m
=
1
)
;
(b,2,w,h)
c
a
t
=
C
o
n
v
(
c
a
t
)
;
(b,1,w,h)
o
u
t
=
s
i
g
m
o
i
d
(
c
a
t
)
;
(b,1,w,h)
avg=AvgPool(x,dim=1) ;\text{ (b,1,w,h)} \\ max=MaxPool(x,dim=1) ;\text{ (b,1,w,h)} \\ cat=concat([avg,max],dim=1) ;\text{ (b,2,w,h)} \\ cat=Conv(cat) ;\text{ (b,1,w,h)} \\ out=sigmoid(cat) ;\text{ (b,1,w,h)} \\
avg=AvgPool(x,dim=1); (b,1,w,h)max=MaxPool(x,dim=1); (b,1,w,h)cat=concat([avg,max],dim=1); (b,2,w,h)cat=Conv(cat); (b,1,w,h)out=sigmoid(cat); (b,1,w,h)
这里输出的只是一个attention map,并不是做完attention后输出的值。
实施效果
Attention U-Net: Learning Where to Look for the Pancreas
2019年 论文地址:https://arxiv.org/pdf/1804.03999.pdf
csdn论文简读地址:https://blog.csdn.net/yumaomi/article/details/124866235
Attention U-Net结果如下图所示,与正常的unet网络相比,多了一个Attention Gate结构,同时用Attention Gate的输出替代了skip_connet的原始输出

Attention Gate
用于unet结构中skip_connet输出和encodeer_conv输出间的attention,用其结果替代skip_connet的输出。其中g为skip_connet的输出,
x
l
x^l
xl为encodeer_conv的输出。
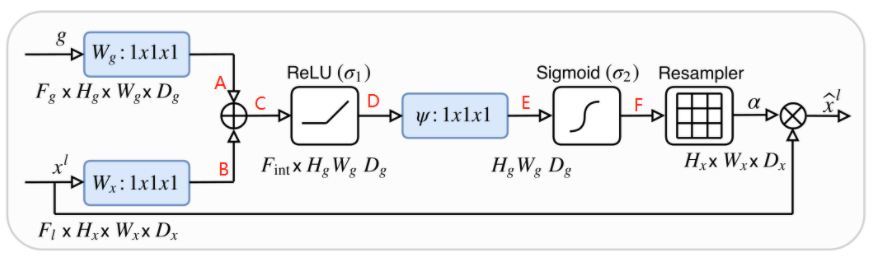
计算方法:
初始化各个block的weight
W
g
=
c
o
n
v
_
b
n
W
x
=
c
o
n
v
_
b
n
A
T
s
=
c
o
n
v
_
b
n
_
s
i
g
m
o
i
d
W_g=conv\_bn \\ W_x=conv\_bn \\ ATs=conv\_bn\_sigmoid \\
Wg=conv_bnWx=conv_bnATs=conv_bn_sigmoid
计算过程
g
=
W
g
(
g
)
;
(b,c,w,h)
x
=
W
x
(
x
l
)
;
(b,c,w,h)
a
t
s
=
A
T
s
(
r
e
l
u
(
g
+
x
)
)
;
(b,c,w,h)
o
u
t
=
a
t
s
∗
x
l
;
(b,c,w,h)
g=W_g(g) ;\text{ (b,c,w,h)} \\ x=W_x(x^l) ;\text{ (b,c,w,h)} \\ ats=ATs(relu(g+x)) ;\text{ (b,c,w,h)} \\ out=ats*x^l ;\text{ (b,c,w,h)} \\
g=Wg(g); (b,c,w,h)x=Wx(xl); (b,c,w,h)ats=ATs(relu(g+x)); (b,c,w,h)out=ats∗xl; (b,c,w,h)
实时效果
Self-Attention Generative Adversarial Networks
2019年 论文地址:https://arxiv.org/abs/1805.08318 csdn简读地址 https://hpg123.blog.csdn.net/article/details/126417621
Self-Attention
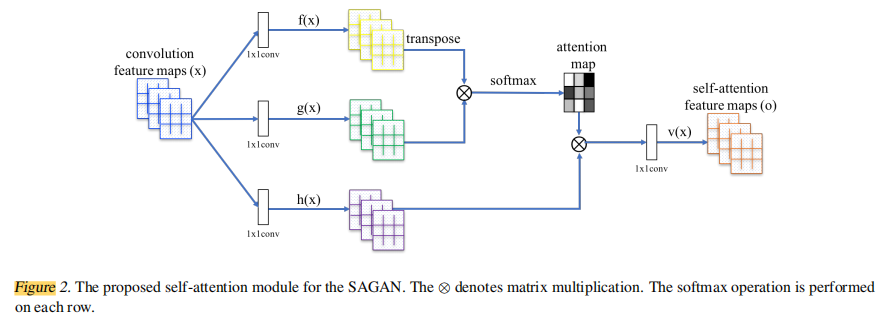
计算方法:
初始化模块weight
F
=
c
o
n
v
(
k
s
i
z
e
=
1
)
G
=
c
o
n
v
(
k
s
i
z
e
=
1
)
H
=
c
o
n
v
(
k
s
i
z
e
=
1
)
g
a
m
m
a
=
z
e
r
o
s
(
1
)
F=conv(ksize=1) \\ G=conv(ksize=1) \\ H=conv(ksize=1) \\ gamma=zeros(1) \\
F=conv(ksize=1)G=conv(ksize=1)H=conv(ksize=1)gamma=zeros(1)
计算过程,输入为x,输出为out。
f
=
F
(
x
)
;
(b,c,w,h)
g
=
G
(
x
)
;
(b,c,w,h)
h
=
H
(
a
v
g
)
;
(b,c,w,h)
f
=
r
e
s
h
a
p
e
(
f
)
;
(b,c,n)
g
=
r
e
s
h
a
p
e
(
g
)
;
(b,c,n)
h
=
r
e
s
h
a
p
e
(
h
)
;
(b,c,n)
a
t
t
n
_
m
a
p
=
s
o
f
t
m
a
x
(
b
m
m
(
f
T
,
g
)
)
;
(b,n,n)
a
t
t
n
_
v
a
l
u
e
=
h
∗
a
t
t
n
_
m
a
p
;
(b,c,n)
o
u
t
=
a
t
t
n
_
v
a
l
u
e
∗
h
o
u
t
=
o
u
t
∗
g
a
m
a
+
x
f=F(x) ;\text{ (b,c,w,h)} \\ g=G(x) ;\text{ (b,c,w,h)} \\ h=H(avg) ;\text{ (b,c,w,h)} \\ f=reshape(f) ;\text{ (b,c,n)} \\ g=reshape(g) ;\text{ (b,c,n)} \\ h=reshape(h) ;\text{ (b,c,n)} \\ attn\_map=softmax(bmm(f^T,g)) ;\text{ (b,n,n)} \\ attn\_value=h*attn\_map ;\text{ (b,c,n)} \\ out=attn\_value*h \\ out=out*gama+x
f=F(x); (b,c,w,h)g=G(x); (b,c,w,h)h=H(avg); (b,c,w,h)f=reshape(f); (b,c,n)g=reshape(g); (b,c,n)h=reshape(h); (b,c,n)attn_map=softmax(bmm(fT,g)); (b,n,n)attn_value=h∗attn_map; (b,c,n)out=attn_value∗hout=out∗gama+x
在这里gama是一个可训练的权重,一开始为0,表示对于attention阶段结果的采用率为0,随着训练过程的变化gaam会不断发生变化。
实施效果

CCNet:Criss-Cross Attention for semantic Segmentation
针对self-attention内存计算庞大提出的结构,以两次十字架结构的attention取代全局attention。
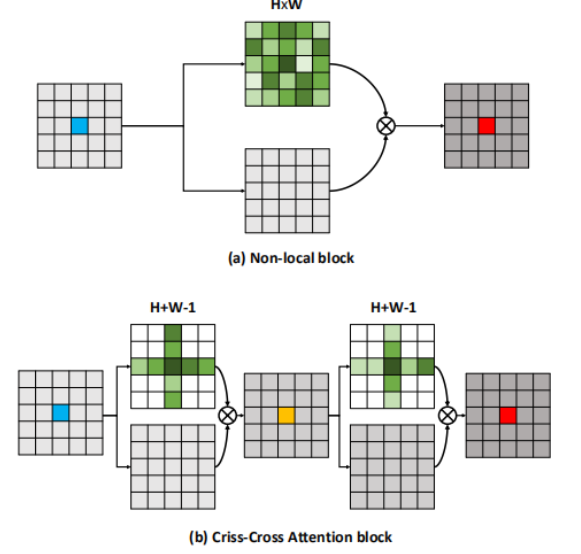
Criss-Cross Attention
发表时间:2018 论文地址:https://arxiv.org/abs/1811.11721 csdn简读地址:https://blog.csdn.net/qq_37935516/article/details/99691994
一种十字交叉提取self-attention的结构,是针对non-local block结构(经典的self-attention结构)太占内存所提出的。经典的self-attention结构中,attention-map的shape为(b,n,n), 这样的矩阵直接与x相乘会导致空间占用暴涨。因此提出先进行height的self-attention,在进行width的self-attention,这样子可以将attention-map的shape减小hight或width倍。
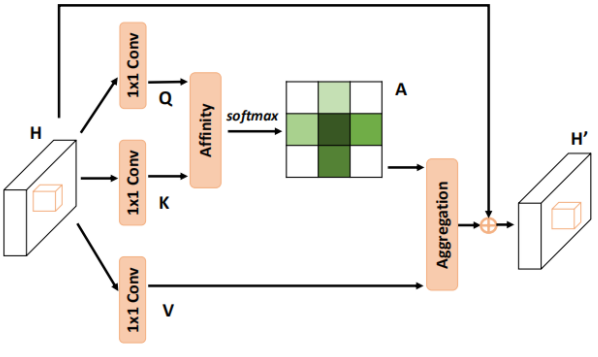
在使用过程中需要连续的两个Criss-Cross Attention才能将十字架结构的attention-map作用到全局,因为一次Criss-Cross Attention只能将注意力按照水平或者垂直方向传递,两次之后它就可以斜向传递。
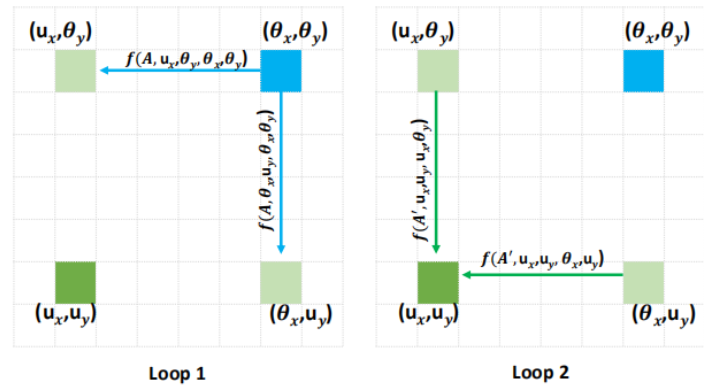
实现代码
代码中INF函数好像没有其他作用,个人认为是可以删除的。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
def INF(B,H,W):
return -torch.diag(torch.tensor(float("inf")).cuda().repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
#print(concate)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + x
if __name__ == '__main__':
model = CrissCrossAttention(64)
x = torch.randn(2, 64, 5, 6)
out = model(x)
print(out.shape)
实施效果
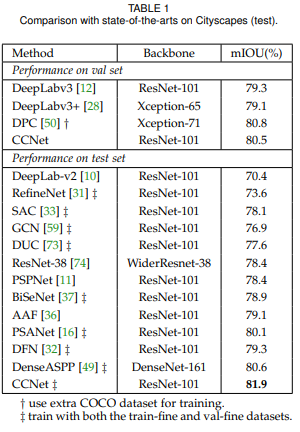
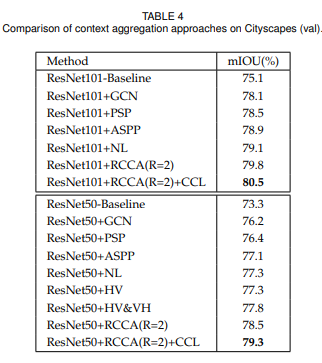
循环次数探索
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0RwKqQTw-1661480735273)(2022-08-25-17-30-29.png)]
Interlaced Sparse Self-Attention for Semantic Segmentation
发表时间:2019
论文链接:https://arxiv.org/abs/1907.12273
csdn简读地址:https://blog.csdn.net/weixin_43578873/article/details/105556655
提出了一种基于自注意力机制的称为交叉稀疏自注意力方法(interlaced sparse self-attention)来提升语义分割中的效率。该方法的主要思想是将密集相似矩阵分解为两个稀疏相似矩阵的乘积。用两个连续的注意模块,每个模块估算一个稀疏的相似矩阵。第一个注意模块用来估计有着较长空间间距距离的position子集的相似性,第二个注意模块用来估计有着较短空间间隔距离的position子集的相似性。设计这两个注意模块使得每个位置都能接收到来自其他所有位置的信息。与一些原始的自注意力模型相比,我们的方法减少了计算力和内存复杂度,特别是处理高分辨率特征图时。我们通过实验验证了该方法在六个具有挑战性的语义分割基准上的有效性。
Interlaced Sparse Self-Attention
交错稀疏自注意力的核心是将密集相似矩阵X分解两次,得到稀疏相似矩阵 X L X^L XL和 X S X^S XS,每次针对稀疏近似矩阵进行self-attention
Long-range Attention 的重点是在具有较长空间距离的子集上应用Self-attention。
Short-range Attention 的重点是在具有较短空间距离的子集上应用Self-attention。
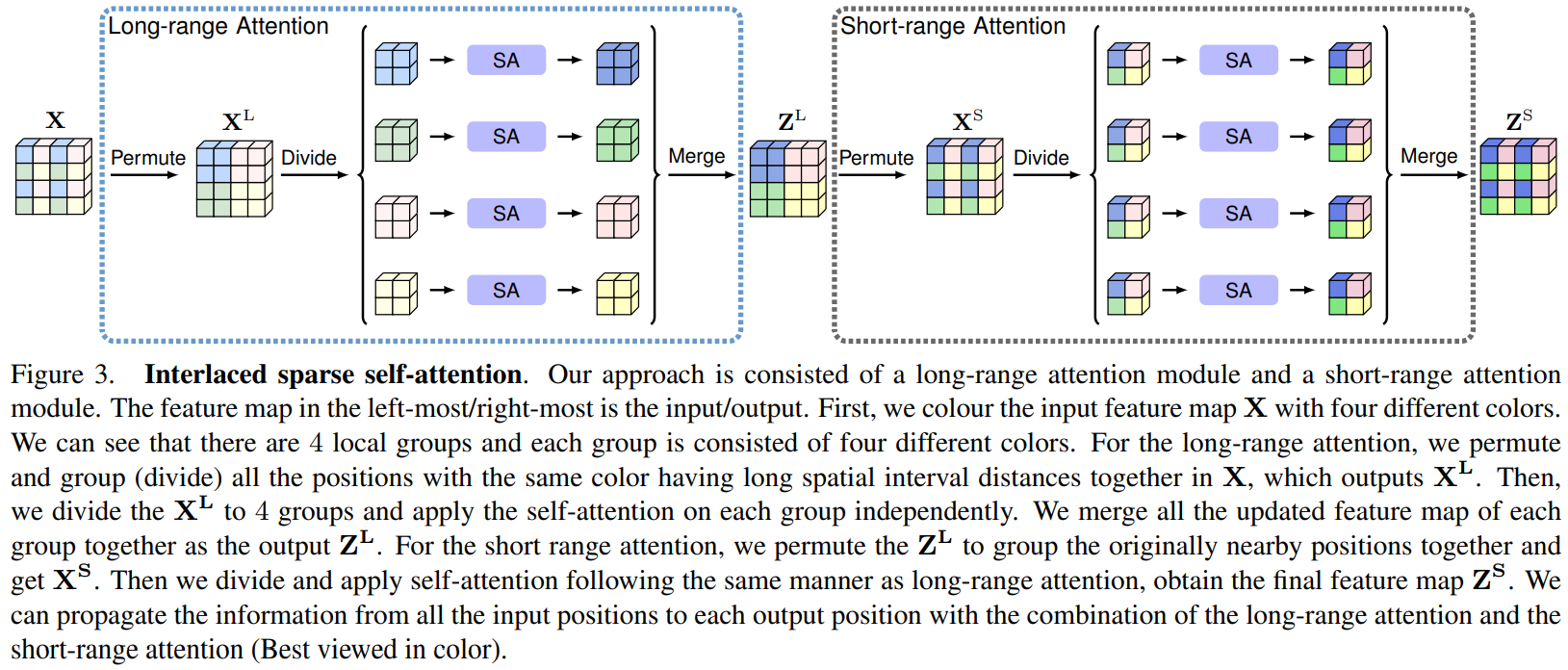
实现过程
其实现过程的代码如下所示,其本质就是对数据进行reshape操作,减小Self-attention做矩阵乘法时的attention-map的大小。通过对数据的重排列,得到长距离的Self-attention和短距离的Self-attention。

实施效果
语义分割
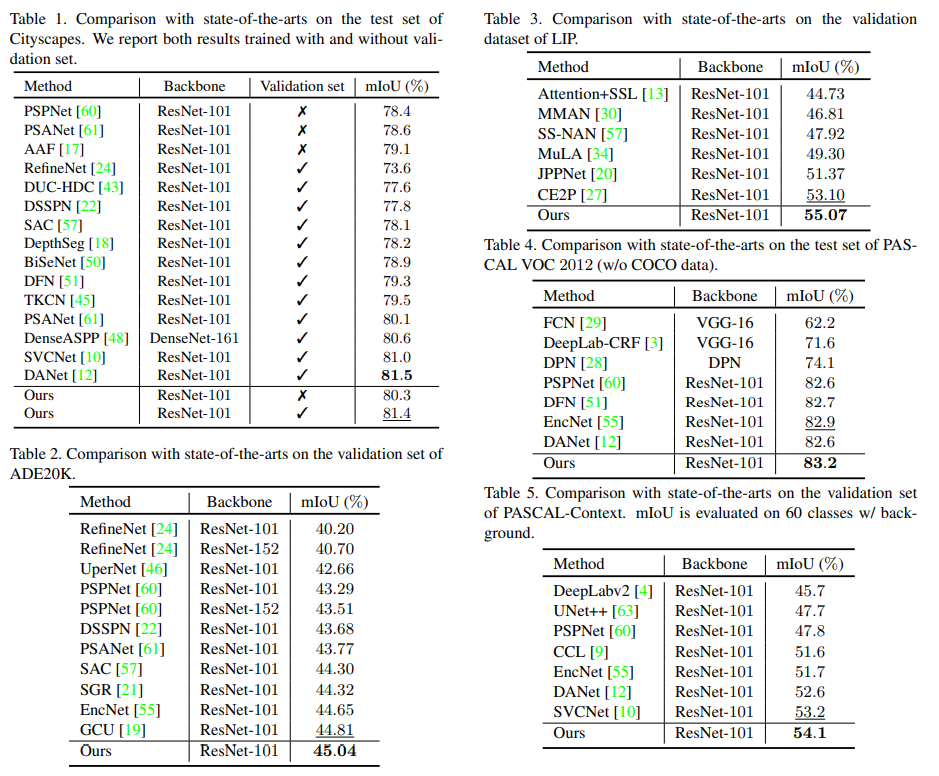
实例分割
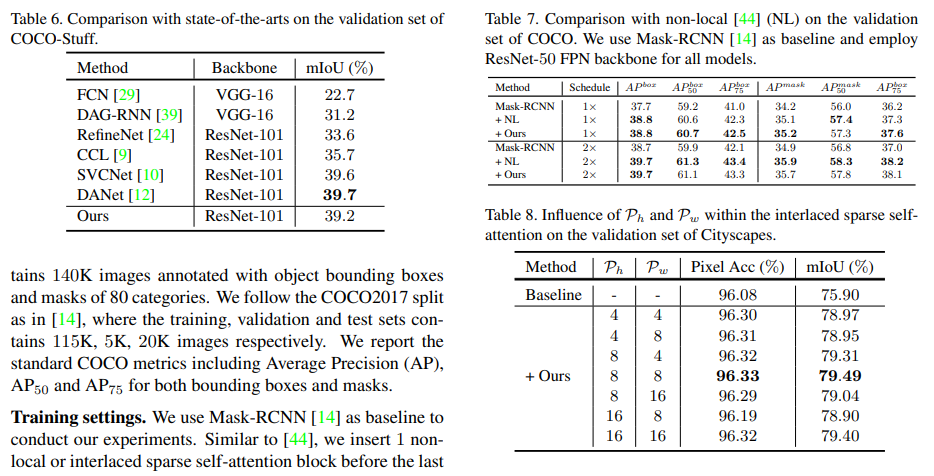
扩展研究
主要研究做attention的顺序和patch size,作者没有上patch size的效果表,只是简单说明patch size为8时性能较好
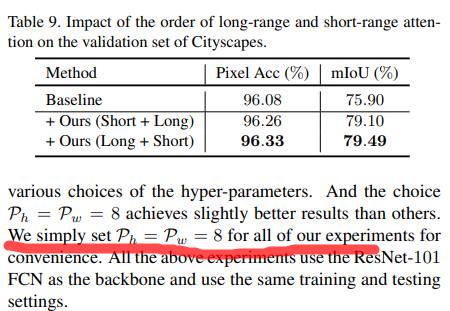
同类对比
结果显示ISSA比普通的self-attention更加优秀,同时也比PPM模块效果更好
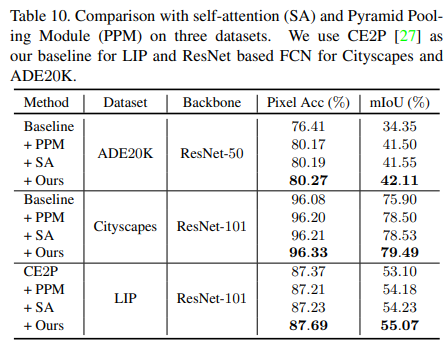
Efficient Attention: Attention with Linear Complexities
发表时间:2020
论文链接:https://arxiv.org/pdf/1812.01243.pdf
csdn简读地址:https://blog.csdn.net/gesshoo/article/details/123582284
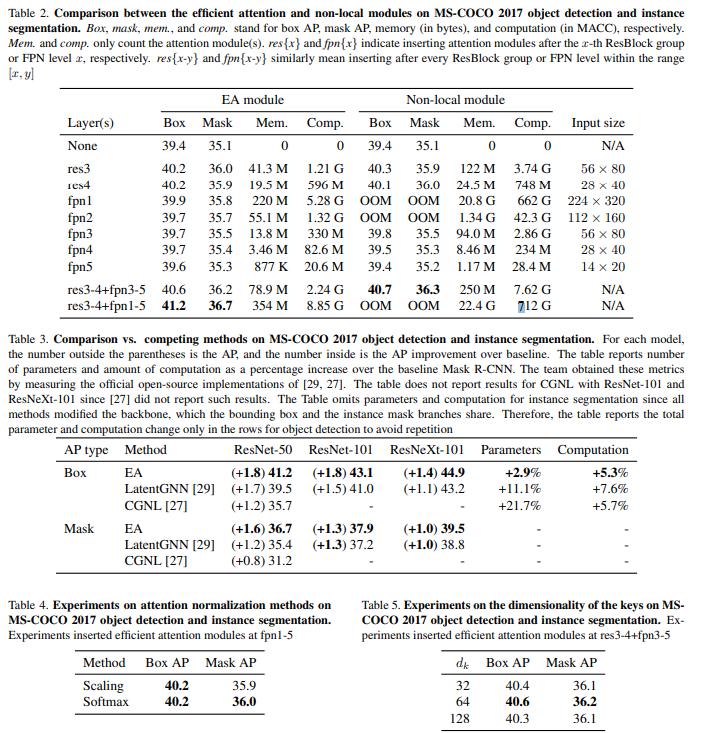
点积注意在计算机视觉和自然语言处理中有着广泛的应用。然而,其内存和计算成本随输入大小呈二次增长。这种增长阻碍了其在高分辨率输入上的应用。为了弥补这一缺陷,本文提出了一种新的高效注意机制,该机制相当于点积注意,但其内存和计算成本大大降低。其资源效率允许将注意力模块更广泛、更灵活地集成到网络中,从而提高准确性。实证评估证明了其优势的有效性。高效的注意力模块为MS-COCO 2017上的对象检测器和实例分段器带来了显著的性能提升。此外,资源效率使对复杂模型的注意力民主化,在复杂模型中,高成本禁止使用点积注意力。作为一个例子,一个高效的模型在场景流数据集上实现了最先进的立体深度估计精度。
Efficient Attention
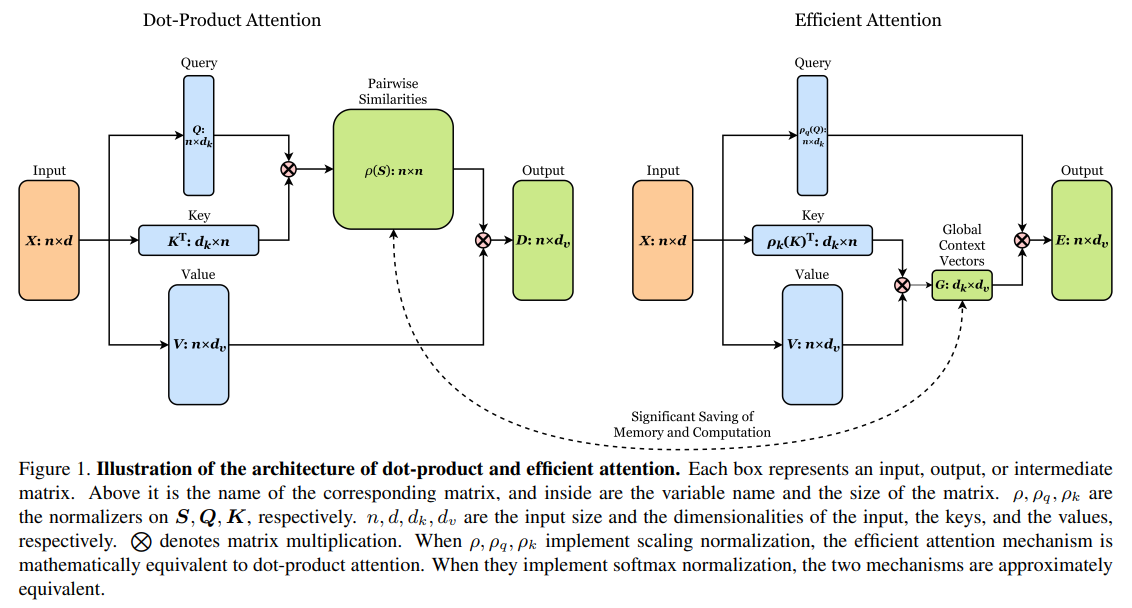
演变过程

基本对比
内存消耗对比
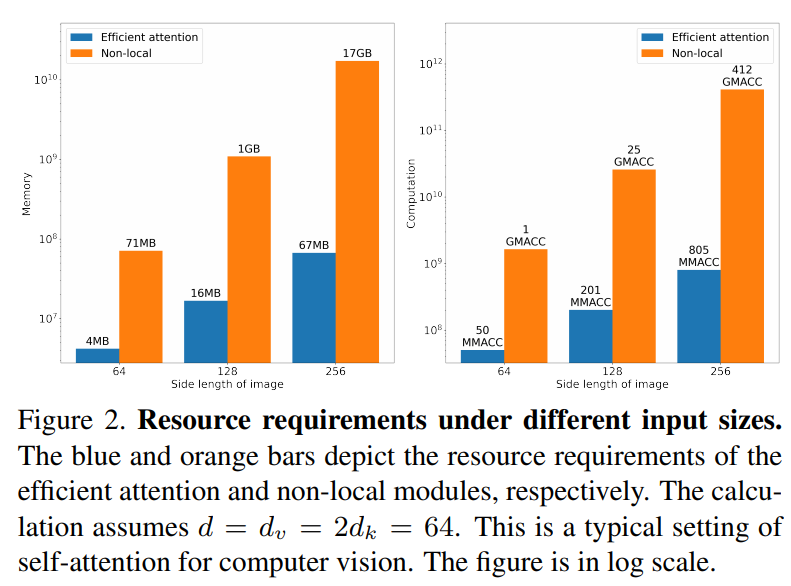
资源消耗对比
实施效果
spatial-reduction attention
PVT中的spatial-reduction attention与segformer中的Efficient Self-Attention基本上是一模一样的
spatial-reduction Attention
编码器的主要计算瓶颈是Self-Attention层。在原始的多头自注意过程中,每个头Q、K、V具有相同的维度N×C,其中N=H×W为序列的长度,自注意估计为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
K
T
d
h
e
a
d
)
V
(1)
Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_{head}}})V \tag{1}
Attention(Q,K,V)=Softmax(dheadQKT)V(1)
该过程的计算复杂度为
O
(
n
2
)
O(n^2)
O(n2),这对于大的图像分辨率是禁止的。相反,我们使用了在[8]中引入的序列缩减过程。此过程使用还原比R来减少序列的长度如下:
K
′
=
R
e
s
h
a
p
e
(
N
R
,
C
⋅
R
)
(
K
)
K
=
L
i
n
e
a
r
(
C
⋅
R
,
C
)
(
K
′
)
V
′
=
R
e
s
h
a
p
e
(
N
R
,
C
⋅
R
)
(
V
)
V
=
L
i
n
e
a
r
(
C
⋅
R
,
C
)
(
V
′
)
(2)
K'=Reshape(\frac{N}{R},C·R)(K) \\ \tag{2} K=Linear(C·R,C)(K') \\ \\ V'=Reshape(\frac{N}{R},C·R)(V) \\ V=Linear(C·R,C)(V')
K′=Reshape(RN,C⋅R)(K)K=Linear(C⋅R,C)(K′)V′=Reshape(RN,C⋅R)(V)V=Linear(C⋅R,C)(V′)(2)
其中K与V是要减少的序列,
K
′
=
R
e
s
h
a
p
e
(
N
R
,
C
⋅
R
)
(
K
)
K'=Reshape(\frac{N}{R},C·R)(K)
K′=Reshape(RN,C⋅R)(K)表示重塑K为形状为
N
R
×
(
C
⋅
R
)
\frac{N}{R}×(C·R)
RN×(C⋅R),
L
i
n
e
a
r
(
C
i
n
,
C
o
u
t
)
(
⋅
)
Linear(C_{in},C_{out})(·)
Linear(Cin,Cout)(⋅)表示线性层,以一个顺维张量作为输入,生成一个
C
o
u
t
C_{out}
Cout维张量作为输出。因此,新的K的维数为
(
N
R
,
C
)
(\frac{N}{R},C)
(RN,C),因此,自注意机制的复杂性从
O
(
n
2
)
O(n^2)
O(n2)降低到
O
(
n
2
R
)
O(\frac{n^2}{R})
O(Rn2)。在我们的实验中,我们从第一阶段到第四阶段将R设置为[64,16,4,1]。
具体实现代码
PVT中 spatial-reduction Attention的实现方式可以参考,https://blog.csdn.net/xiaohu2022/article/details/115445923。
下面参考了mmseg中segformer中Efficient Self-Attention的实现方式,这与原文中描述存在不同(与PVT中 spatial-reduction Attention中实现方式一模一样)。这里是通过控制卷积的stride来进行维度缩减。
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = Conv2d(
in_channels=embed_dims,
out_channels=embed_dims,
kernel_size=sr_ratio,
stride=sr_ratio)
#将W*H的数据通过卷积变为(W/sr_ratio)*(H/sr_ratio)
# The ret[0] of build_norm_layer is norm name.
self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
# handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
from mmseg import digit_version, mmcv_version
if mmcv_version < digit_version('1.3.17'):
warnings.warn('The legacy version of forward function in'
'EfficientMultiheadAttention is deprecated in'
'mmcv>=1.3.17 and will no longer support in the'
'future. Please upgrade your mmcv.')
self.forward = self.legacy_forward
def forward(self, x, hw_shape, identity=None):
x_q = x
if self.sr_ratio > 1:
x_kv = nlc_to_nchw(x, hw_shape)
x_kv = self.sr(x_kv)
x_kv = nchw_to_nlc(x_kv)
x_kv = self.norm(x_kv)
else:
x_kv = x
if identity is None:
identity = x_q
# Because the dataflow('key', 'query', 'value') of
# ``torch.nn.MultiheadAttention`` is (num_query, batch,
# embed_dims), We should adjust the shape of dataflow from
# batch_first (batch, num_query, embed_dims) to num_query_first
# (num_query ,batch, embed_dims), and recover ``attn_output``
# from num_query_first to batch_first.
if self.batch_first:
x_q = x_q.transpose(0, 1)
x_kv = x_kv.transpose(0, 1)
out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
if self.batch_first:
out = out.transpose(0, 1)
return identity + self.dropout_layer(self.proj_drop(out))















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











