







超分辨中的注意力机制:Attention in Super Resolution - SuperGqq - 博客园
注意力绪论
参考:【计算机视觉】详解 Non-local 模块与 Self-attention (视觉注意力机制 (一))_闻韶-CSDN博客
计算机相关领域主要使用的是soft attention,这些方法的共同之处在于:
利用相关特征学习权重分布,再将学习得到的权重施加于特征上,从而进一步提取相关知识。但 施加权重的方式略有差别,可概括为:
- 加权可作用在 原图 上;
- 加权可作用在 空间尺度 上,给不同空间位置加权,如 PAM;
- 加权可作用在 通道尺度 上,给不同通道特征加权,如 CAM;
- 加权可作用在 不同时刻历史特征 上,结合循环结构添加权重,如机器翻译或视频相关的工作。
视觉应用中的 self-attention 机制
参考:【计算机视觉】详解 Non-local 模块与 Self-attention (视觉注意力机制 (一))_闻韶-CSDN博客
由于 卷积核作用的感受野是局部的,须累积经过许多层后才能将整个图像不同部分的区域关联起来。如何将全局的信息统计起来是一个需要解决的问题。
Self-attention 是借鉴自 NLP 的思想,因此仍保留了 Query,Key 和 Value 等名称。Self-attention 结构 自上而下分为三个分支,分别是 query、key 和 value。
给定一个任务相关的查询向量q,通过计算与key的注意力分布并附加在Value上,从而计算attention value得分 ,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。
计算时通常分为三步:
- 第一步,令 query 和每个 key 进行 相似度计算得到权重,常用的相似度 (similarity) 函数有点积、拼接、感知机等;
- 第二步,通常使用 softmax 归一化这些权重;
- 第三步,将归一化权重和 key 相应的 value 进行 加权求和,得到最后的 attention。

Non-local
Non-local 的通用公式表示: i 代表的是当前位置的响应,j 代表全局响应,通过加权得到一个非局部的响应值。
![]()
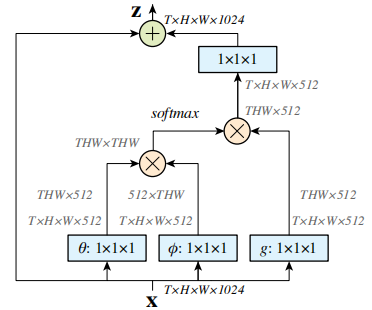
Non-local Neural Networks 模块依然存在以下的不足:
- 只涉及到了位置注意力模块,而 没有涉及常用的通道注意力机制
- 可以看出如果特征图较大,那么两个 (batch, hxw, 512) 矩阵乘是非常耗内存和计算量的,也就是说 当输入特征图很大时存在效率低下的问题,虽然有其他办法解决例如缩放尺度,但是这样会损失信息,不是最佳处理办法。
存在问题:在[PANet](#PANet:Pyramid Attention Networks for Image Restoration)中指出,在自注意力模块中使用的逐像素匹配通常对低级视觉任务很嘈杂(噪声问题),从而降低了性能。 从直觉上讲,扩大搜索空间会增加寻找更好匹配的可能性,但对于现有的自注意模块而言并非如此。 与采用大量降维操作的高级特征图不同,图像重建网络通常会保持输入的空间大小。 因此,特征仅与局部区域高度相关,因此容易受到噪声信号的影响。 这与传统的非局部滤波方法相一致,在传统的非局部滤波方法中,逐像素匹配的效果比块匹配要差得多。
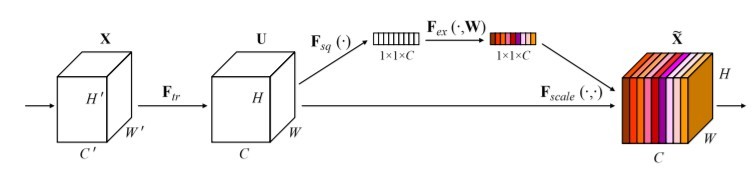
通道注意力机制Squeeze-and-Excitation Networks














 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









