








由于矩阵乘法是关联的,将顺序从![]() 切换到
切换到![]() 对效果没有什么影响,但可以将复杂度从O(n^2)到O(dk*dv),使其复杂度成为线性。在实际情况下,dk*dv明显小于n^2。
对效果没有什么影响,但可以将复杂度从O(n^2)到O(dk*dv),使其复杂度成为线性。在实际情况下,dk*dv明显小于n^2。
这种方法被文章称为”efficient attention“。
新机制在数学上等价于尺度归一化的点乘注意力,近似于softmax归一化的点乘注意力。实验证明,当近似相等时并不影响准确率。另外,实验表明它的效率允许将更多的注意力模块集成到网络中,并集成到网络的高分辨率部分中,这将导致更高的准确率。此外,实验还表明,有效的注意力可以将注意力大众化到由于资源限制而不适用点积注意力的任务上。
Efficient attention机制对注意力机制带来了新的解释。(此处不写)
Key可以看作dk个模板关注图,每一个都对应于输入的语义方面。每个像素上的query分别表示dk个模板关注图的dk个系数。注意力使用这些特征图中的每一个作为所有位置上的权重,并通过加权求和来聚集值特征以形成全局上下文向量。
Efficient attention首先通过模板关注图聚合value形成模板输出,即全局上下文向量。然后让每个像素聚合模板输出。
相关工作
1.点乘注意力
本文比较了efficient attention模块与non-local模块在相同性能下的资源效率,以及在相同资源约束下的性能。
2.尺度注意力
SE、CBAM等。尽管这两个名称都包含注意力,但点积注意力和扩大注意力是两套截然不同的技术,目标截然不同。
3.高效的非局部操作
LatentGNN提出用三个低秩矩阵的乘积近似非局部模块中的单个n×n亲和矩阵。相比之下,有效注意力不是非局部模块的近似值,而是数学上等价的(使用比例归一化)。
CGNL建议将高度、宽度和通道维度展平为HWC-维向量,应用核函数将维度扩展到HWC×(p+1),其中p是泰勒展开的次数,并在该空间中模拟全局依赖关系。然而,在将输入平整成矢量后,每个位置的特征就变成了标量,这就编码了有限的信息用于交互建模。
方法
(1)A revisit of dot-product attention
![]() 归一化函数有两种常见选择:
归一化函数有两种常见选择:
 表示将SoftMax函数应用于矩阵Y的每行。
表示将SoftMax函数应用于矩阵Y的每行。
这一机制的关键缺点是它的资源需求。
(2)Efficient attention
![]()
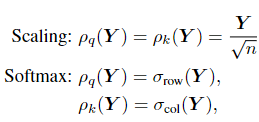
(3) Equivalence between dot-product and efficientattention等价性
(4)Interpretation of efficient attention
(5) Efficiency advantage

推导了有效注意模型和非局部模型(使用点积注意)的复杂度公式。

实验

将键的维数从128降低到32只会导致最小的精度变化。 大多数关注度图都可以表示为有限的模板关注度图的线性组合。因此,研究人员可以降低高效注意模块中关键字和查询的维数,从而进一步节省资源。














 1445
1445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









