







 本文详细介绍了Java中的并发容器ConcurrentHashMap,特别是其内部的Copy-On-Write(COW)策略。ConcurrentHashMap通过Segment结构实现高并发,每个Segment维护一个链表数组,使得写操作只需锁定对应Segment。文章详细讲解了Segment和HashEntry的数据结构,以及ConcurrentHashMap的初始化、get、put和remove操作。此外,还探讨了CopyOnWriteArrayList的实现原理和应用场景,指出COW容器适用于读多写少的场景,但需要注意内存占用和数据一致性问题。
本文详细介绍了Java中的并发容器ConcurrentHashMap,特别是其内部的Copy-On-Write(COW)策略。ConcurrentHashMap通过Segment结构实现高并发,每个Segment维护一个链表数组,使得写操作只需锁定对应Segment。文章详细讲解了Segment和HashEntry的数据结构,以及ConcurrentHashMap的初始化、get、put和remove操作。此外,还探讨了CopyOnWriteArrayList的实现原理和应用场景,指出COW容器适用于读多写少的场景,但需要注意内存占用和数据一致性问题。
ConcurrentHashMap并发容器
ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
ConcurrentHashMap的内部结构
ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类Hash Table的结构,Segment内部维护了一个链表数组,我们用下面这一幅图来看下ConcurrentHashMap的内部结构:
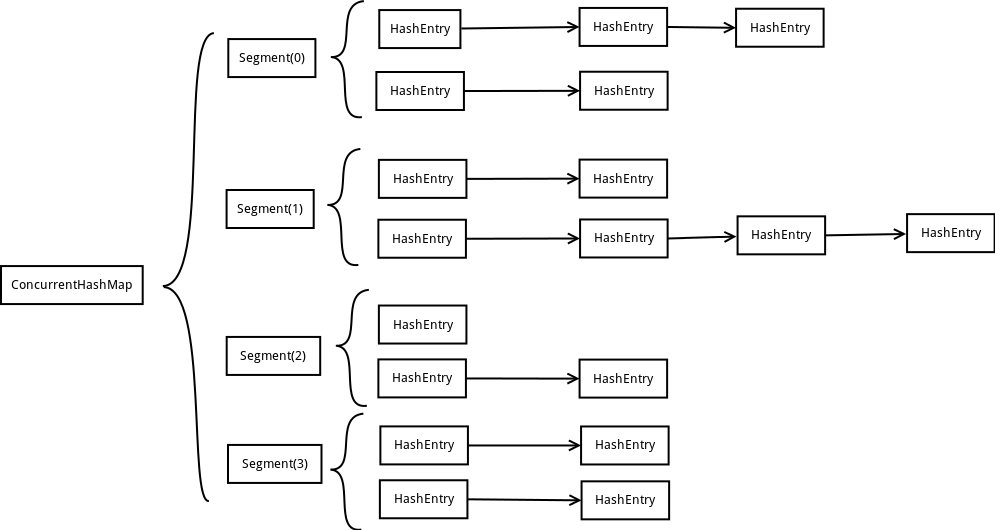
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
Segment
我们再来具体了解一下Segment的数据结构:
详细解释一下Segment里面的成员变量的意义:
- count:Segment中元素的数量
- modCount:对table的大小造成影响的操作的数量(比如put或者remove操作)
- threshold:阈值,Segment里面元素的数量超过这个值依旧就会对Segment进行扩容
- table:链表数组,数组中的每一个元素代表了一个链表的头部
- loadFactor:负载因子,用于确定threshold
HashEntry
Segment中的元素是以HashEntry的形式存放在链表数组中的,看一下HashEntry的结构:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}可以看到HashEntry的一个特点,除了value以外,其他的几个变量都是final的,这样做是为了防止链表结构被破坏,出现ConcurrentModification的情况。
ConcurrentHashMap的初始化
下面我们来结合源代码来具体分析一下ConcurrentHashMap的实现,先看下初始化方法:
CurrentHashMap的初始化一共有三个参数,一个initialCapacity,表示初始的容量,一个loadFactor,表示负载参数,最后一个是concurrentLevel,代表ConcurrentHashMap内部的Segment的数量,ConcurrentLevel一经指定,不可改变,后续如果ConcurrentHashMap的元素数量增加导致ConrruentHashMap需要扩容,ConcurrentHashMap不会增加Segment的数量,而只会增加Segment中链表数组的容量大小,这样的好处是扩容过程不需要对整个ConcurrentHashMap做rehash,而只需要对Segment里面的元素做一次rehash就可以了。
整个ConcurrentHashMap的初始化方法还是非常简单的,先是根据concurrentLevel来new出Segment,这里Segment的数量是不大于concurrentLevel的最大的2的指数,就是说Segment的数量永远是2的指数个,这样的好处是方便采用移位操作来进行hash,加快hash的过程。接下来就是根据intialCapacity确定Segment的容量的大小,每一个Segment的容量大小也是2的指数,同样使为了加快hash的过程。
这边需要特别注意一下两个变量,分别是segmentShift和segmentMask,这两个变量在后面将会起到很大的作用,假设构造函数确定了Segment的数量是2的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









