







在Python提供了正则表达式的模块re,这里针对re模块进行一个小总结
1.re.match
匹配字符串的开头,如果匹配成功,就会返回match 对象,使用group接受打印
test ="qilixiang=jay&shuangjiegun=jay&wanku=panweibo"
m = re.match(r"\w+=\w+&",test)
if m:
print 're.match:',m.group(0)
else:
print '没有匹配到!'输出结果:re.match: qilixiang=jay&
2.re.search
匹配整个字符串,直到匹配成功,返回一个match,却别re.match
test ="qilixiang=jay&shuangjiegun=jay&wanku=panweibo"
m = re.search(r"\w+=\w+&",test)
if m:
print "re.search:",m.group(0)
else:
print '没有匹配到!'输出结果:re.search: qilixiang=jay&
3.re.findall
匹配所有的字符,如果又符合的返回所有匹配到的,并且返回一个list
test ="qilixiang=jay&shuangjiegun=jay&wanku=panweibo"
m = re.findall(r"\w+=\w+&",test)
print "re.findall:",m输出结果:re.findall: [‘qilixiang=jay&’, ‘shuangjiegun=jay&’]
4.re.sub
通过正则,匹配进行替换
test ="qilixiang=jay&shuangjiegun=jay&wanku=panweibo"
m = re.sub(r"\w+=\w+&",'%',test,1)
print "re.sub:",m输出结果:re.sub: %shuangjiegun=jay&wanku=panweibo
5.re.split
根据正则表达式,对字符串进行分割,结果返回一个list
test ="qilixiang=jay&shuangjiegun=jay&wanku=panweibo"
m = re.split(r"&+",test)
print "re.split:",m输出结果:re.split: [‘qilixiang=jay’, ‘shuangjiegun=jay’, ‘wanku=panweibo’]
6.re.compile
对正则表达式,进行编译,生成新的正则表达式,并且可以设定正则的规则
test ="qilixiang=jay&shuangjiegun=jay&wanku=panweibo"
res = re.compile(r"\w+=\w+&")
m = res.findall(test)
print "compile re.findall:",m输出结果:compile re.findall: [‘qilixiang=jay&’, ‘shuangjiegun=jay&’]
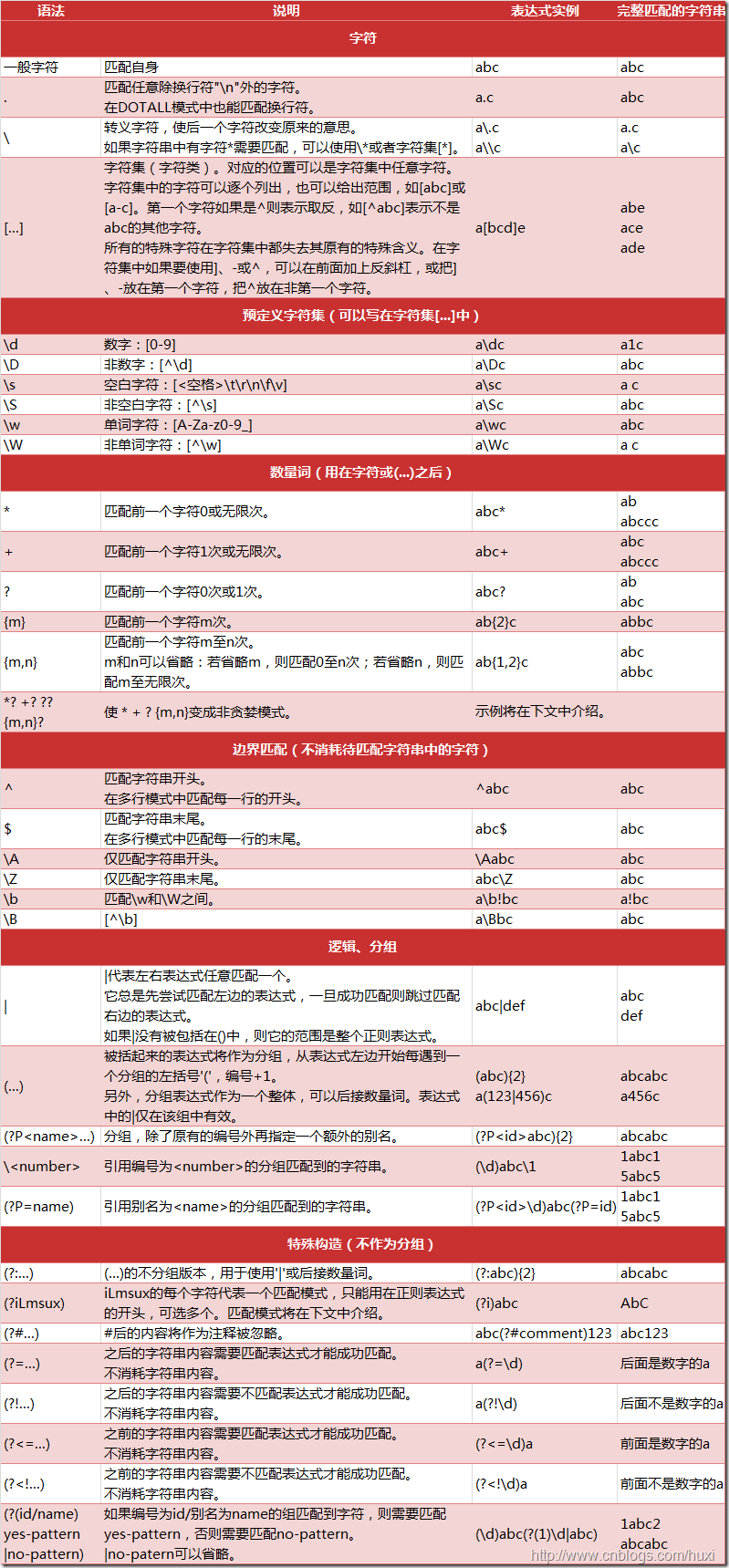
关于正则表达式的讲解参考网图:















 3610
3610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









