







 本文详细剖析了Redis的启动流程以及两种核心的数据持久化方案——RDB和AOF,帮助读者深入理解如何确保Redis在故障后能恢复数据。
本文详细剖析了Redis的启动流程以及两种核心的数据持久化方案——RDB和AOF,帮助读者深入理解如何确保Redis在故障后能恢复数据。
一、前言
因为近期项目中开始使用Redis,为了更好的理解Redis并应用在适合的业务场景,需要对Redis设计与实现深入的理解。
我分析流程是按照从main进入,逐步深入分析Redis的启动流程。同时根据Redis初始化的流程,理解Redis各个模块的功能及原理。
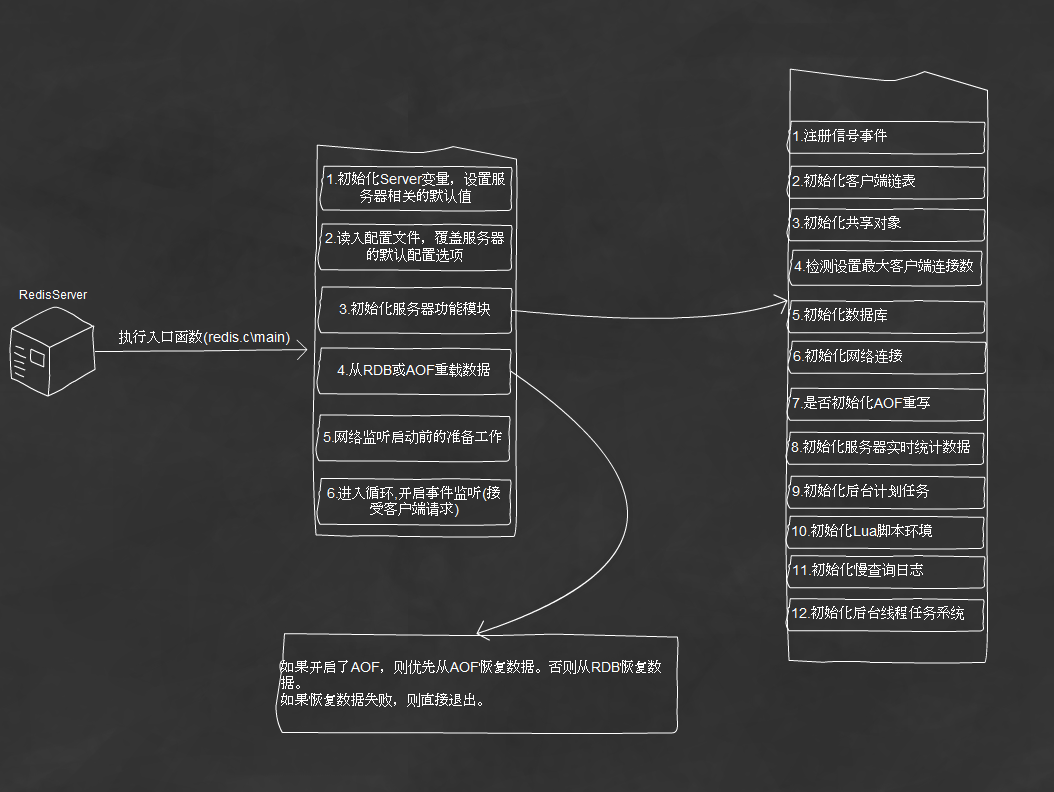
二、redis启动流程
1.初始化server变量,设置redis相关的默认值
2.读入配置文件,同时接收命令行中传入的参数,替换服务器设置的默认值
3.初始化服务器功能模块。在这一步初始化了包括进程信号处理、客户端链表、共享对象、初始化数据、初始化网络连接等
4.从RDB或AOF重载数据
5.网络监听服务启动前的准备工作
6.开启事件监听,开始接受客户端的请求
启动的部分过程通过查看下图,会更直观。
下面是针对启动过程中,对各个模块的详细理解。(目前只分析了后台线程系统与慢查询日志系统)

三、Redis数据持久化方案
在使用redis时不少人都说一个问题,就是说redis宕机了怎么办?会不会数据丢失等等的问题。
现在来看看Redis提供的数据持久化解决方案,并通过原理分析优缺点。最终能得出Redis适合使用的应用场景。
1.RDB持久化方案
在Redis运行时,RDB程序将当前内存中的数据库快照保存到磁盘中,当Redis需要重启时,RDB程序会通过重载RDB文件来还原数据库。
从上述描述可以看出,RDB主要包括两个功能:
关于rdb的实现可以见src/rdb.c
a)保存(rdbSave)
rdbSave负责将内存中的数据库数据以RDB格式保存到磁盘中,如果RDB文件已经存在将会替换已有的RDB文件。保存RDB文件期间会阻塞主进程,这段时间期间将不能处理新的客户端请求,直到保存完成为止。为避免主进程阻塞,Redis提供了rdbSaveBackground函数。在新建的子进程中调用rdbSave,保存完成后会向主进程发送信号,同时主进程可以继续处理新的客户端请求。
b)读取(rdbLoad)
当Redis启动时,会
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









