







计算机体系结构期末复习
5 流水线技术
5.1 知识点
计算机体系结构在向着多核并行的趋势发展,包括数据级并行(DLP),指令级并行(ILP),线程级并行(TLP),请求级并行(RLP)。本章主要讲解ILP。ILP实现有三种方式,第一种是superpipelining,流水线或超流水线处理机;第二种是super-scalar,多操作部件或超标量处理机;第三种是VLIW,Very Long Instruction Word,超长指令字处理机,还在进一步研究。因此本章涉及到的知识点有先行控制技术、流水线原理与性能分析、非线性流水线的调度方法、局部相关与全局相关、最后是超标量处理机和超流水线处理机。考试重点如下:

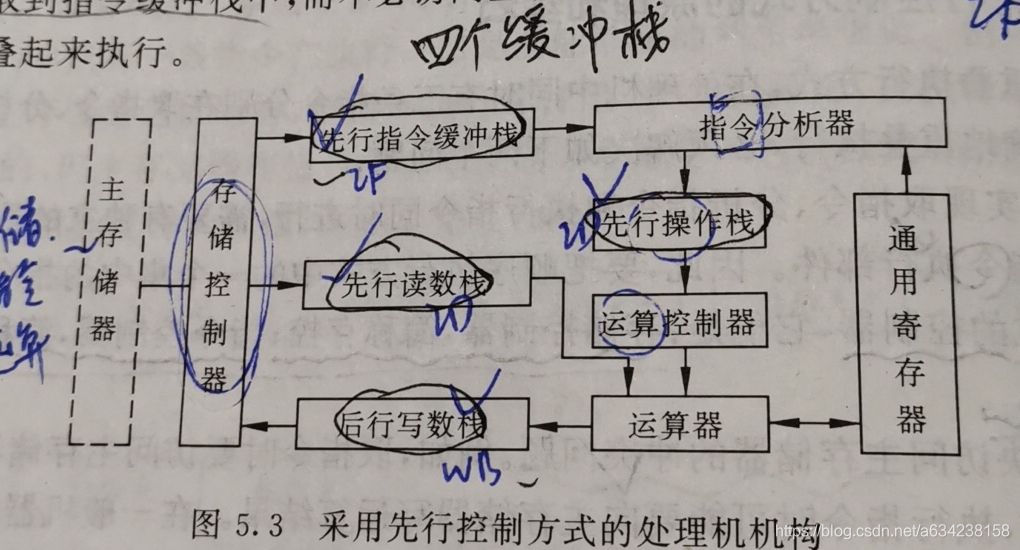
- 要实现流水线,处理机的结构必须采用先行控制方式。先行控制技术的关键是缓冲技术和预处理技术。缓冲技术指的是在工作速度不固定的两个功能之间设置缓冲栈(比如对于功能部件IF-ID-EX-MEM-WB要设置4个缓冲栈缓冲),预处理技术指的是进入ALU的指令都采用RR型指令(这要求采用哈佛结构,以及增添
lw与sw指令将存储器操作数转化为寄存器数)。因此我们增添了3+4,3个独立的控制器:指令控制器,运算控制器,存储控制器,4个缓冲栈:先行指令缓冲栈,先行读数栈,先行操作栈,后行写数栈。因此采用先行控制方式,理想的执行n条指令时间为: T 先 行 ≈ ∑ i = 1 n t 执 行 i T_{先行}\approx\sum_{i=1}^{n}t_{执行i} T先行≈∑i=1nt执行i。
- (记忆位置,了解功能)先行指令缓冲栈用于IF,先行读数栈用和先行操作栈用于ID-EX,主要功能为预处理(将RI或RX转化为RR指令),后行写数栈。
- 流水线技术。包括
superpipelining和super-scalar,分别运用了时间并行性(分时使用同一个部件不同部分)和空间并行性(设置多个独立操作部件)。流水线分为线性流水线和非线性流水线,非线性流水线有前馈回路和反馈回路,由流水线连接图和流水线预约表二者唯一确定一条流水线。对于线性流水线,用时空图表示,时间-空间,横轴时间为指令条数或深度,纵轴空间为功能段个数。一条指令的流水步随着历经的时间和功能段逐步向右上移动,注意数据相关。流水线也分为静态流水线和动态流水线。静态流水线指流水线各个功能段在同一时间只能实现一种功能,指令全部排空后,才可实现下一步功能。流水线的性能分析,吞吐率: T P = n / T k TP=n/T_{k} TP=n/Tk,加速比: S = T 0 / T k S=T_{0}/T_{k} S=T0/Tk,效率: E = T 0 / ( k ∗ T k ) E=T_{0}/(k*T_{k}) E=T0/(k∗Tk)。其中, T P m a x = 1 / Δ t ( Δ t 为 流 水 线 横 轴 的 单 位 时 间 ) TP_{max}=1/\Delta{t}(\Delta{t}为流水线横轴的单位时间) TPmax=1/Δt(Δt为流水线横轴的单位时间), S m a x = k S_{max}=k Smax=k, E m a x = 1 E_{max}=1 Emax=1。 - 非线性流水线的预约表。因为一个指令可能在多个功能段重复多次,因此要寻找延迟输入新任务使之不冲突的最小启动循环。我们通过一组二进制数(如001100)记录当前流水线的冲突状态,称为冲突向量(1为冲突位),代表着若流水线右移的步数为冲突向量二进制位为1所在的下标(如001100的3和4),则发生冲突。这个冲突向量可以进行
右移或运算,对当前状态的冲突向量A右移m步(m只可为二进制位0的索引下标)并进行或操作,或的另一个对象自然是当前冲突向量A本身,可以产生该流水段的新冲突向量。若有两次右移(m,n)使冲突向量A可以回到原点。称(m,n)为不冲突的启动循环。通常已知预约表,求状态图。因此完成状态图的目标就是要得到全部的冲突向量以及全部的(m,n)。这里遍历即可:对初始冲突向量S,进行右移或操作,产生冲突向量;对每个新的冲突向量S进行右移或操作,直至遍历完成。 - 非线性流水线的优化调度方法。由定理,最小平均启动距离的下限是预约表中一行X最多的个数N。此行/功能段被称为瓶颈流水段。优化调度的目标是将N作为流水线的最小启动距离,使得瓶颈流水功能段始终处于忙碌状态,此时性能达到峰值。因此预约表中对于每隔N的流水步,若产生冲突,要相应向后移位。若后面的流水步需要前面流水步的结果,前面流水步移位,也要跟着移位。由此完成优化调度后的预约表。
- 相关性分析。包括数据相关(在执行本条指令用到的变量是前面指令的执行结果)和控制相关(由条件分支指令、无条件/一般条件/符合条件转移指令、中断等引起的相关),二者前后也被称为局部相关和全局相关。解决数据相关的方法:推后处理和设置专用路径。解决控制相关的方法:1.延迟转移技术和指令取消技术(由编译器调度无关指令),2.静态/动态分支预测技术(软件:通过编译器降低转移Y的概率,硬件:增加指令分析器提前取PC1,再增加一个先行目标缓冲栈;动态:在指令cache中设置转移的历史信息(设置转移历史表字段)/设置转移目标地址缓冲栈),3.提前形成条件码。条件分支对流水线性能的影响: T K − I F = ( n + k − 1 ) Δ t + n p q ( k − 1 ) Δ t T_{K-IF}=(n+k-1)\Delta{t}+npq(k-1)\Delta{t} TK−IF=(n+k−1)Δt+npq(k−1)Δt, n p q npq npq为n条指令中转移成功的指令条数。则流水线吞吐率下降的百分比为 D = ( T P M A X − T P M A X − I F ) / ( T P M A X ) = p q ( k − 1 ) / ( 1 + p q ( k − 1 ) ) D=(TP_{MAX}-TP_{MAX-IF})/(TP_{MAX})=pq(k-1)/(1+pq(k-1)) D=(TPMAX−TPMAX−IF)/(TPMAX)=pq(k−1)/(1+pq(k−1))。
- 动态调度技术。流水线有顺序和乱序三种调度方式:顺序发射顺序完成,顺序发射乱序完成,乱序发射乱序完成。值得警醒的是,在乱序流动中,可能发生3种数据相关。WR相关(写读相关),RW相关,WW相关。变量换名可以消除RW相关和WW相关,其规则是一个变量只允许定值一次。然而对于WR相关,无法换名,只能推后处理或设置专用路径。
- 超标量处理机( 1 < I L P < m 1<ILP<m 1<ILP<m)。首先引入单发射与多发射处理机这一概念,单发射处理机每个周期内只进行一次IF/ID/EX/WB。多发射处理机每个周期内可同时进行多个IF/ID/EX/WB。因此,超标量处理机的概念是,有两条或两条以上能同时工作的指令流水线。实现,先行指令窗口,从指令cache中预测多条指令,并分析是否存在相关和部件资源冲突。对于资源冲突,假定每周期发射m条指令,部件延迟时间k个周期,如果操作部件不采用流水线结构,使用同一部件的两条指令应至少相差m*k,若采用k段流水线结构,只需差m以上即可。总结一下,超标量处理机,不同于普通标量处理机,希望相同操作不要连续出现。性能: T ( m , 1 ) = ( k + N − m m ) Δ t T(m,1)=(k +\frac{N-m}{m})\Delta{t} T(m,1)=(k+mN−m)Δt,最大加速比为m。
- 超流水线处理机( 1 < I L P < n 1<ILP<n 1<ILP<n)。超流水线处理机,在一个周期内分时发射多条指令的处理机。性能: T ( 1 , n ) = ( k + N − 1 n ) Δ t T(1,n)=(k+\frac{N-1}{n})\Delta{t} T(1,n)=(k+nN−1)Δt,最大加速比为n。
- 超标量超流水线处理机( 1 < I L P < m n 1<ILP<mn 1<ILP<mn)。一个时钟周期发射m次,每次发射n条指令。性能: T ( m , n ) = ( k + N − m m n ) Δ t T(m,n)=(k+\frac{N-m}{mn})\Delta{t} T(m,n)=(k+mnN−m)Δt,最大加速比为m*n。经比较,我们得到结论。超标量处理机的相对性能最高,其次是超标量超流水线处理机,超流水线处理机的相对性能最低。条件转移等操作造成的损失,超流水线处理机要比超标量处理机大,由于超流水线处理机采用深度流水线结构,对条件转移等操作比超标量处理机敏感。超流水线处理机的启动延迟通常要比超标量处理机大。超标量处理机在每个时钟周期的一开始就同时发射多条指令。
5.2 大题
-
已知一条线性静态流水线k个功能段,以及各个操作所使用的功能段。求流水线的时空图,实际吞吐率,加速比,效率等
- 考点:时空图,静态,数据相关
- 题目:

- 解答:

-
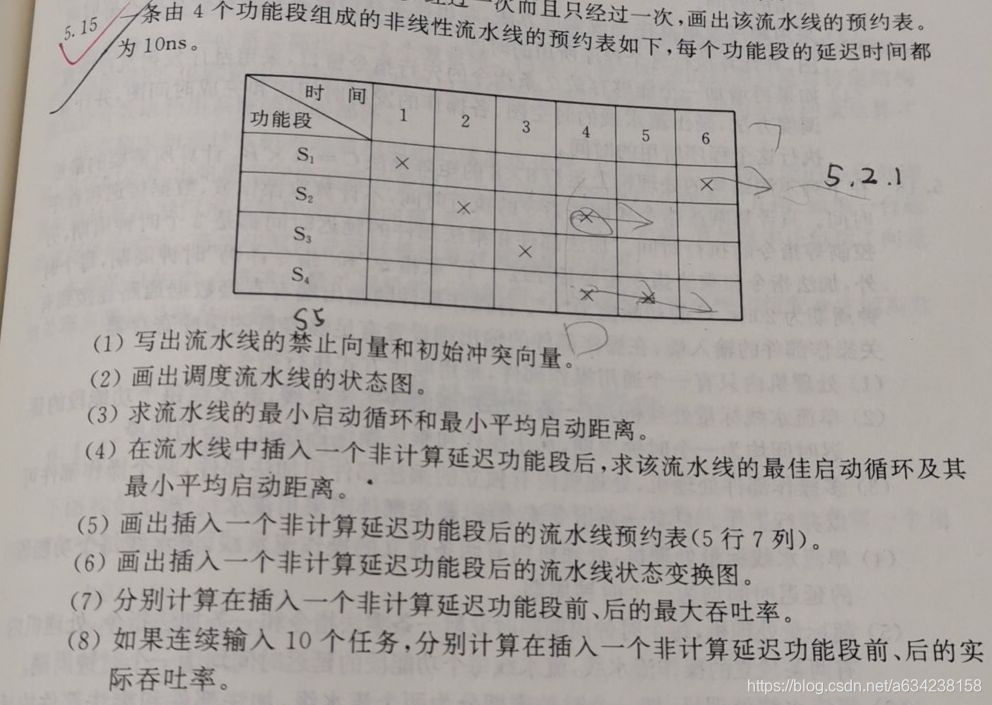
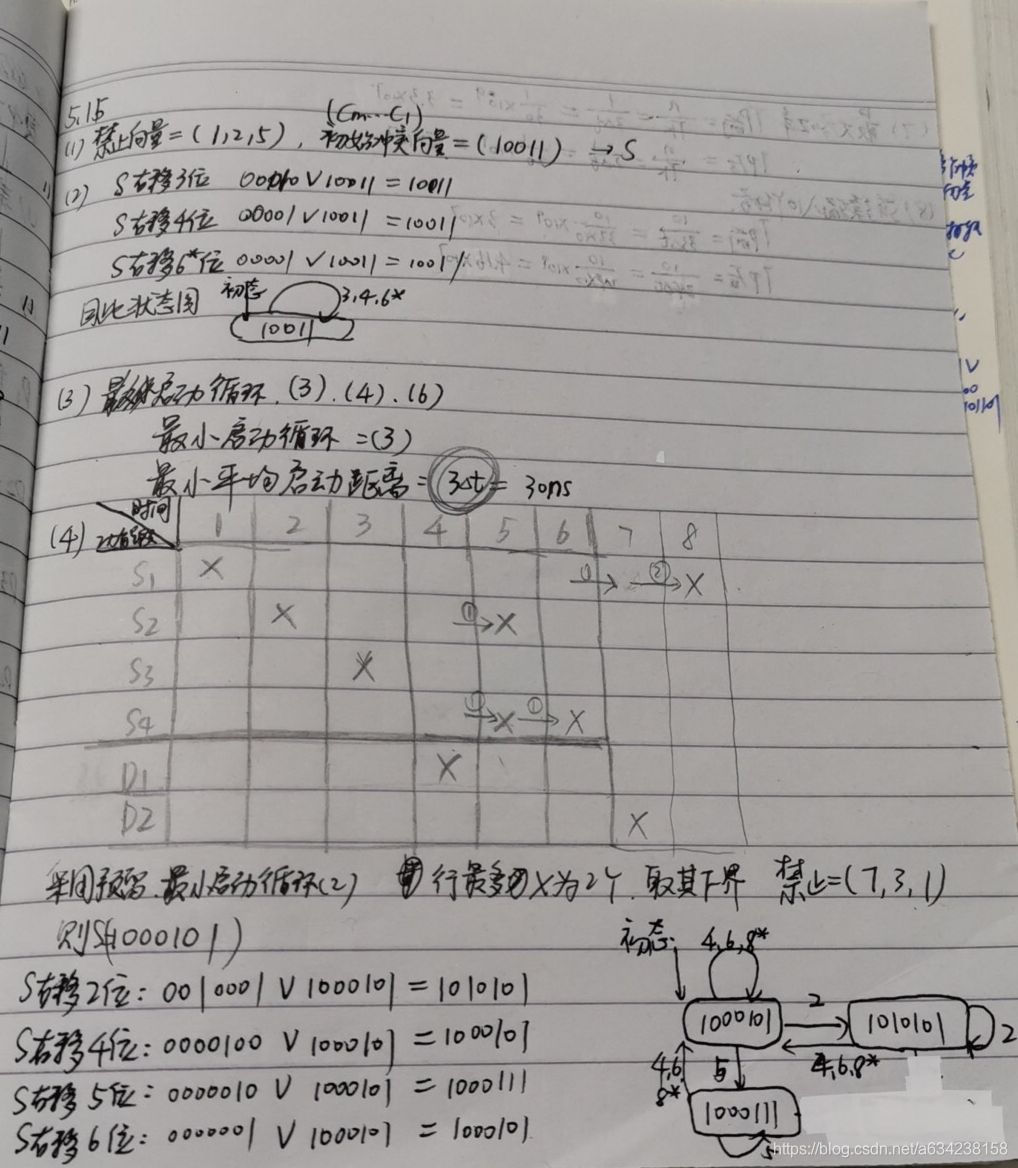
已知一条k个功能段的非线性流水线预约表。求调度流水线状态图,最小启动循环与最小平均启动距离。插入一个非计算延迟功能段后,求该流水线的最佳启动循环及最小平均启动距离,预约表,状态图。最大吞吐率与实际吞吐率。
-
考点:预约表,状态图,优化调度方法
-
题:
-
解答:
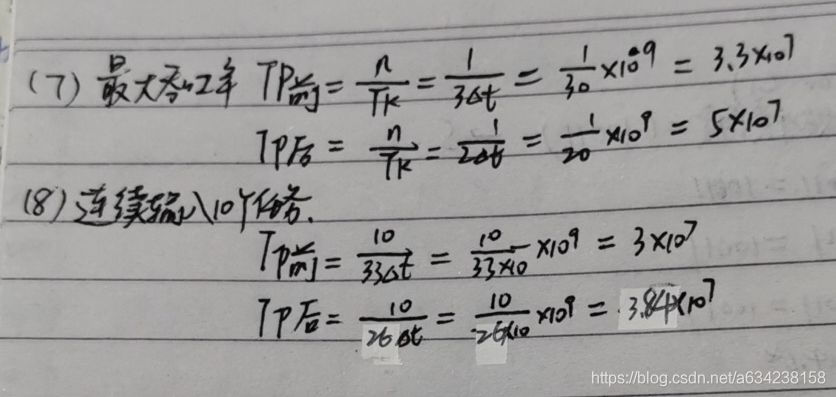
-














 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









