







支持向量机SVM
支持向量机(support vector machine,SVM)是由Cortes和Vapnik在1995年提出的,由于其在文本分类和高维数据中强大的性能,很快就成为机器学习的主流技术,并直接掀起了“统计学习”在2000年前后的高潮,是迄今为止使用的最广的学习算法。
本篇将要简要的介绍一下SVM,如有错误请批评指正,共同学习。本文主要分为以下几个部分:
- SVM的优化目标(代价函数)
- SVM最大间隔超平面 large margin(决策边界)
- SVM最大间隔中的数学原理(mathematics behind large margin classification)
- 核函数 kernels
- 实践中使用SVM
一、SVM的代价函数(cost function)
先来看下SVM的代价函数,即SVM的优化目标。SVM的代价函数和logistic regression有几分相似。SVM的代价函数为:
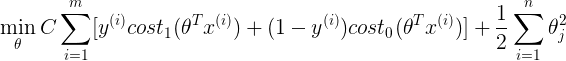
其中  为正则化系数。其中函数
为正则化系数。其中函数 和函数
和函数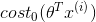 的图像如下图所示:
的图像如下图所示:
为正则化系数。其中函数和函数的图像如下图所示:
从上图中可以看出,要想最小化代价函数,则:
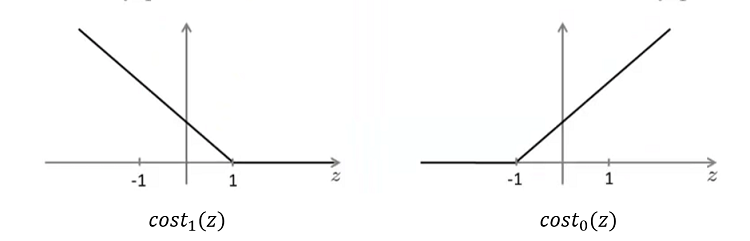
当一个正样本y=1时,我们希望 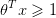 。
。
。
当一个负样本y=0时,我们希望 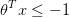 。
。
。
===关于上面大于等于1,小于等于-1解释下,其实大于等于0,小于等于0就能够正确分类了,但是如果设置1,-1这样相当于把间隔又放大了,这样的话相当于对分类更加严格了,效果泛化能力相对较好些。===
二、
SVM最大间隔超平面 large margin(决策边界)
在给定的样本空间中,SVM主要通过划分超平面(决策边界)来实现样本分类,但是存在多个能划分训练样本的超平面(决策边界)如下图所示:
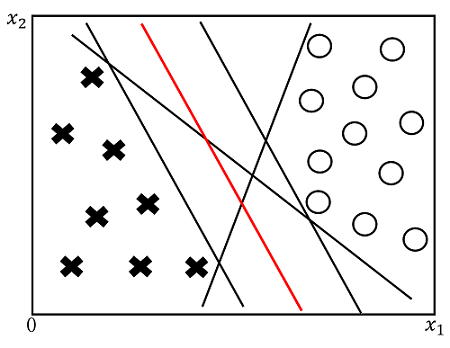
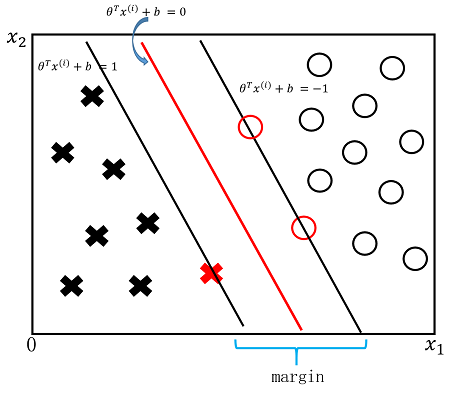
那么SVM会选择哪一个超平面呢?SVM会选择具有最大间隔(margin)的超平面即上图中红色的超平面,因为它和样本之间具有最大的margin,因此意味着这个超平面具有最强的泛化能力(鲁棒性)。
SVM的目的就是为了最大的margin,那么该如何找到这个margin呢?超平面(决策边界)可以用方程来表示: .其中
.其中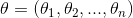 是超平面的法向量,
是超平面的法向量,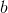 是位移项。在上一节SVM代价函数部分讲到了为了使超平面能够正确分类,需要有如下的约束条件:
是位移项。在上一节SVM代价函数部分讲到了为了使超平面能够正确分类,需要有如下的约束条件:
.其中是超平面的法向量, 是位移项。在上一节SVM代价函数部分讲到了为了使超平面能够正确分类,需要有如下的约束条件:
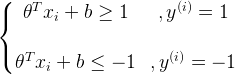
所谓支持向量就是距离超平面最近的样本点并且使上式等号成立(在下图中用红色标出)。而两个异类的支持向量到超平面的距离之和即为间隔(margin):
因此,从上图中能够得到间隔(margin)为:
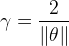
而SVM的任务则是找到间隔最大的超平面,并且要满足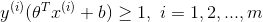 (这个约束条件是从上面的那个大括号那两个约束得来的,只不过把两个合写成了一个)的约束条件,即:
(这个约束条件是从上面的那个大括号那两个约束得来的,只不过把两个合写成了一个)的约束条件,即:
(这个约束条件是从上面的那个大括号那两个约束得来的,只不过把两个合写成了一个)的约束条件,即:
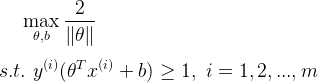
为了计算的方便,可以把上式改写为:
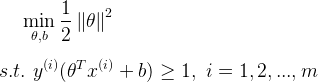
因此上式变成了在约束条件下的最值问题,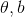 可以用拉格朗日乘数法求得。
可以用拉格朗日乘数法求得。
可以用拉格朗日乘数法求得。
我们来看看代价函数中参数C对超平面的影响,如下图所示(图片来源:NG machine learning课):

当我们把C设置成不太大的时候会产生上图中黑色的超平面,而当我们把C设置的过大时,则是上图中粉色的超平面,显然粉色的超平面有点倾向过拟合了,其泛化能力显然很差。因此参数C的选择要折中考虑margin和过拟合。
三、SVM最大间隔中的数学原理(mathematics behind large margin classification)
在上一节其实已经介绍了如何通过数学求解最大间隔,在这一节中更加形象的用图解的方式介绍下具体数学原理。首先先来介绍一下向量内积,这个大家都知道,这里就简单的说下。假设有两个二维向量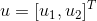 和
和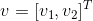 ,其内积为
,其内积为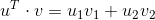 ,当然其内积也可以通过几何这样计算:
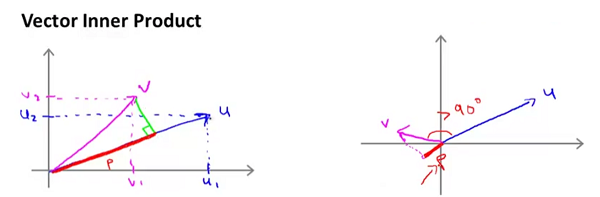
,当然其内积也可以通过几何这样计算: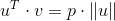 ,其中P是有符号的,如下图中左图p是正的,右图则为负的。
,其中P是有符号的,如下图中左图p是正的,右图则为负的。
和,其内积为,当然其内积也可以通过几何这样计算:,其中P是有符号的,如下图中左图p是正的,右图则为负的。
因此,对于SVM代价函数中的优化目标: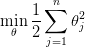

因为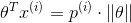 ,
,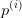 是
是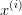 在
在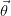 上的投影,因此的约束条件可以表示为:
上的投影,因此的约束条件可以表示为:
,是在上的投影,因此的约束条件可以表示为:
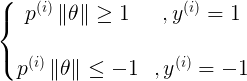
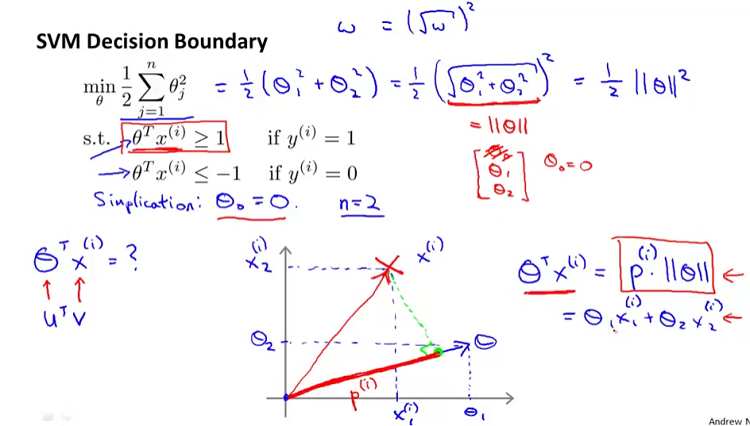
下面我们通过图来看看为何SVM会选择具有最大间隔的超平面(决策边界),先来看下图中的决策边界(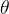 是超平面的法向量,因此与超平面是垂直的):
是超平面的法向量,因此与超平面是垂直的):
是超平面的法向量,因此与超平面是垂直的):
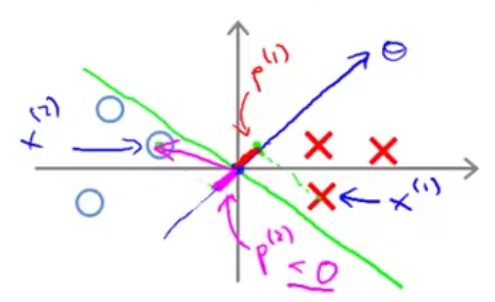
如上图中绿色的决策边界,可以看到样本点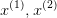 在上的投影
在上的投影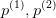 非常的小,这就意味着约束条件
非常的小,这就意味着约束条件 中的 会非常的大,这显然与我们的优化目标不符。
中的 会非常的大,这显然与我们的优化目标不符。
在上的投影非常的小,这就意味着约束条件中的 会非常的大,这显然与我们的优化目标不符。
我们再来看一个比较好的决策边界:
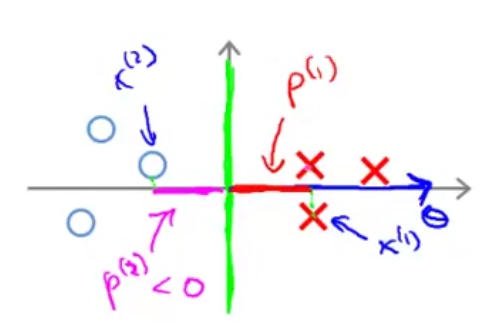
这个图中绿色的决策边界,可以看到样本点在 上的投影 是最大的,因此对于约束条件中的 会相对较小,这正是我们希望看到的。
在 上的投影 是最大的,因此对于约束条件中的 会相对较小,这正是我们希望看到的。
以上就从数学角度解释了SVM为什么会选择具有最大间隔的超平面。
四、核函数(kernels)
关于核函数最常用的核函数一般有线性核函数(linear kernels)和高斯核函数(Gaussian kernels),高斯核函数又叫径向基函数(Radical Basis Function,RBF) 。
假如给出一个如下图所示的非线性决策边界:
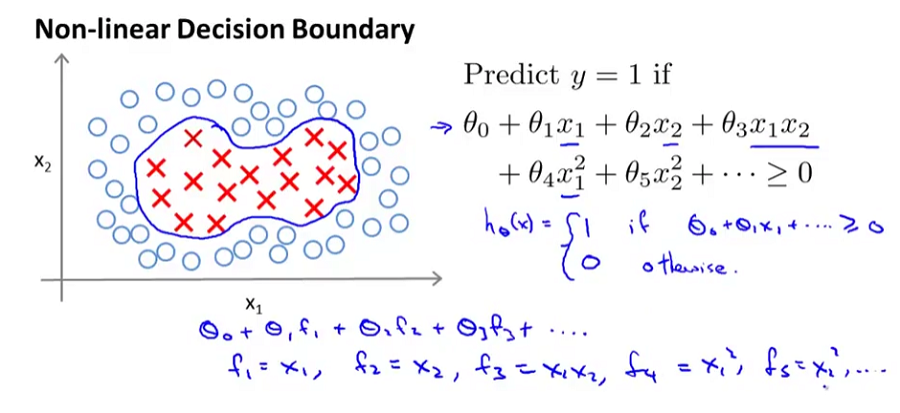
我们可以构造一个如上图中所写的多项式特征变量,来区分正负样本。这种多项式还可以写成上图中的: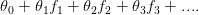 ,其中
,其中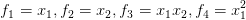 ,除了这种表达,还能不能有更好的其他选择去表示特征
,除了这种表达,还能不能有更好的其他选择去表示特征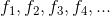 。这就要引入核函数(kernels),核函数是一种更好的表达。我们可以通过计算原始向量与landmark之间的相似度来表示特征,如下图所示:
。这就要引入核函数(kernels),核函数是一种更好的表达。我们可以通过计算原始向量与landmark之间的相似度来表示特征,如下图所示:
,其中,除了这种表达,还能不能有更好的其他选择去表示特征。这就要引入核函数(kernels),核函数是一种更好的表达。我们可以通过计算原始向量与landmark之间的相似度来表示特征,如下图所示:

当然还可以用其他的函数来计算相似度,只不过这个例子中使用的高斯核函数。我们来看上图中计算的公式,其中:
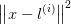 表示欧式距离取平方。
因此,我们能够发现:
表示欧式距离取平方。
因此,我们能够发现:
的公式,其中:
表示欧式距离取平方。
因此,我们能够发现:
- 当
时,
。
- 当
距离
很远时,
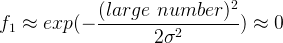
因此给定一个样本 上图中landmark(标记点)会定义出新的特征变量 。
上图中landmark(标记点)会定义出新的特征变量 。
上图中landmark(标记点)会定义出新的特征变量 。
下面我们来看看根据计算出的特征怎样去分类样本。如下图所示:
怎样去分类样本。如下图所示:

假设当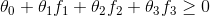 时,我们预测样本类别为“1”,假设我们已经求得
时,我们预测样本类别为“1”,假设我们已经求得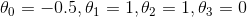 。那么对于图中给定的样本x,我们可以计算出
。那么对于图中给定的样本x,我们可以计算出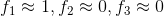 ,那么代入上式可得
,那么代入上式可得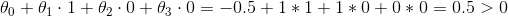 :,因此预测样本x的类别“1”。因此如果计算大量的样本,就能得出一个非线性的决策边界,如图所示:
:,因此预测样本x的类别“1”。因此如果计算大量的样本,就能得出一个非线性的决策边界,如图所示:
时,我们预测样本类别为“1”,假设我们已经求得。那么对于图中给定的样本x,我们可以计算出,那么代入上式可得:,因此预测样本x的类别“1”。因此如果计算大量的样本,就能得出一个非线性的决策边界,如图所示:

那么现在有一个问题就是,我们是怎样选择得到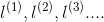 的,下面来介绍是如何得到的。
的,下面来介绍是如何得到的。
的,下面来介绍是如何得到的。
在刚开始,我们只需把训练集中的样本一一对应成即可,即给定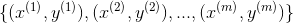 ,令
,令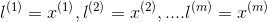 如下图所示:
如下图所示:
即可,即给定,令如下图所示:
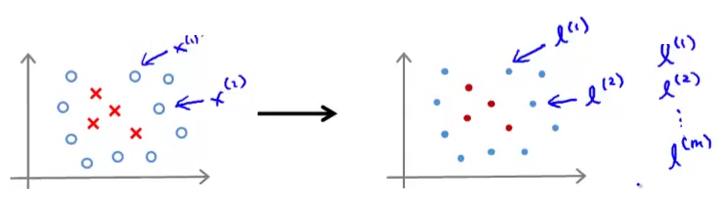
因此,若给定一个训练样本 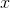 ,能够得到如下特征
,能够得到如下特征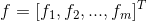 :
:
,能够得到如下特征:
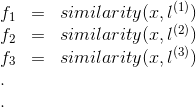
其中。
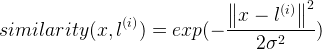
因此,带核函数的SVM(SVM with kernels)的代价函数变为:

关于SVM的核函数(kernels)就介绍到这,下面来看看SVM中参数的选择问题(主要是参数 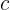 和
和 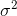 该如何选择):
该如何选择):
和 该如何选择):

来看下ng对参数选择的总结:

五、实践中使用SVM
在实际使用SVM的时候,不建议大家自己实现SVM,因为SVM是一个特定的优化问题。目前已经有非常成熟并且高度优化的软件包,如国立台湾大学林智仁教授开发的liblinear(http://www.csie.ntu.edu.tw/~cjlin/liblinear/)和LibSVM(http://www.csie.ntu.edu.tw/~cjlin/libsvm/),非常出名。但是我们依然需要做的是以下两点:

一般来说,当特征维度很高,而样本较少时选择线性核函数。当特征数量较少,样本数量较多时,选择高斯核函数。note:在使用高斯核函数之前要进行特征缩放(如果特征值之间差距过大)。
还有一些其他的核函数如下表所示:(实际上,只要一个对称函数所对应的核矩阵满足半正定的,就能作为核函数使用)

最后,我们来比较下逻辑回归和SVM,看看何种情况下该使用逻辑回归,何种情况下使用SVM。详见下图(直接盗用NG的图)

以上就是关于SVM的全部知识,大家共同学习。

















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









