







 本文详细介绍了如何使用Python对LIDC-IDRI肺结节数据集进行肺癌良恶性分类,包括模型加载、数据集划分、性能评估(准确率、精确度、召回率、F1值及ROC曲线)、决策收益分析和混淆矩阵的生成。
本文详细介绍了如何使用Python对LIDC-IDRI肺结节数据集进行肺癌良恶性分类,包括模型加载、数据集划分、性能评估(准确率、精确度、召回率、F1值及ROC曲线)、决策收益分析和混淆矩阵的生成。
基于LIDC-IDRI肺结节肺癌数据集的人工智能深度学习分类良性和恶性肺癌(Python 全代码)全流程解析(三)
第一部分传送门
第二部分传送门
1 模型的读取和数据集的划分
在搭建深度学习模型并完成模型的训练后,开始进行模型的性能的评估。首先将处理好的数据读入,而后随机的按照7:3的比例随机的切分为训练集和测试集。本部分使用测试集进行模型的分类性能评估。
#读取预处理数据
labels,data_x,data_y,data_z = load_data(label_path,data_path)
# 划分训练集和测试集
train_data_x, test_data_x, train_data_y, test_data_y, train_data_z, test_data_z, train_labels, test_labels = train_test_split(data_x, data_y, data_z, labels, test_size=0.3, random_state=42)
而后读取保存好的深度学习模型
model_file = os.path.join(result_path, 'model_44.h5')
H = load_model(model_file)
2 准确率,精确度(precision)、召回率(recall)、F1值(F1-score)评估
对测试集的真实标签(y_true)和模型预测得到的二元分类结果(y_pred)进行评估,通过输出分类报告(classification_report)来得到模型的性能指标。
#
predictions = H.predict([test_data_y, train_data_z, test_data_z])
# 将概率值转换为0和1
predictions_binary = np.argmax(predictions, axis=1)
##test
y_true = test_labels[:,1]
y_pred = predictions_binary
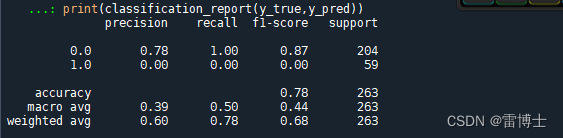
print(classification_report(y_true,y_pred))
训练的结果如下,精确度大概为0.78左右,然而模型存在一定程度的偏移,需要调参。
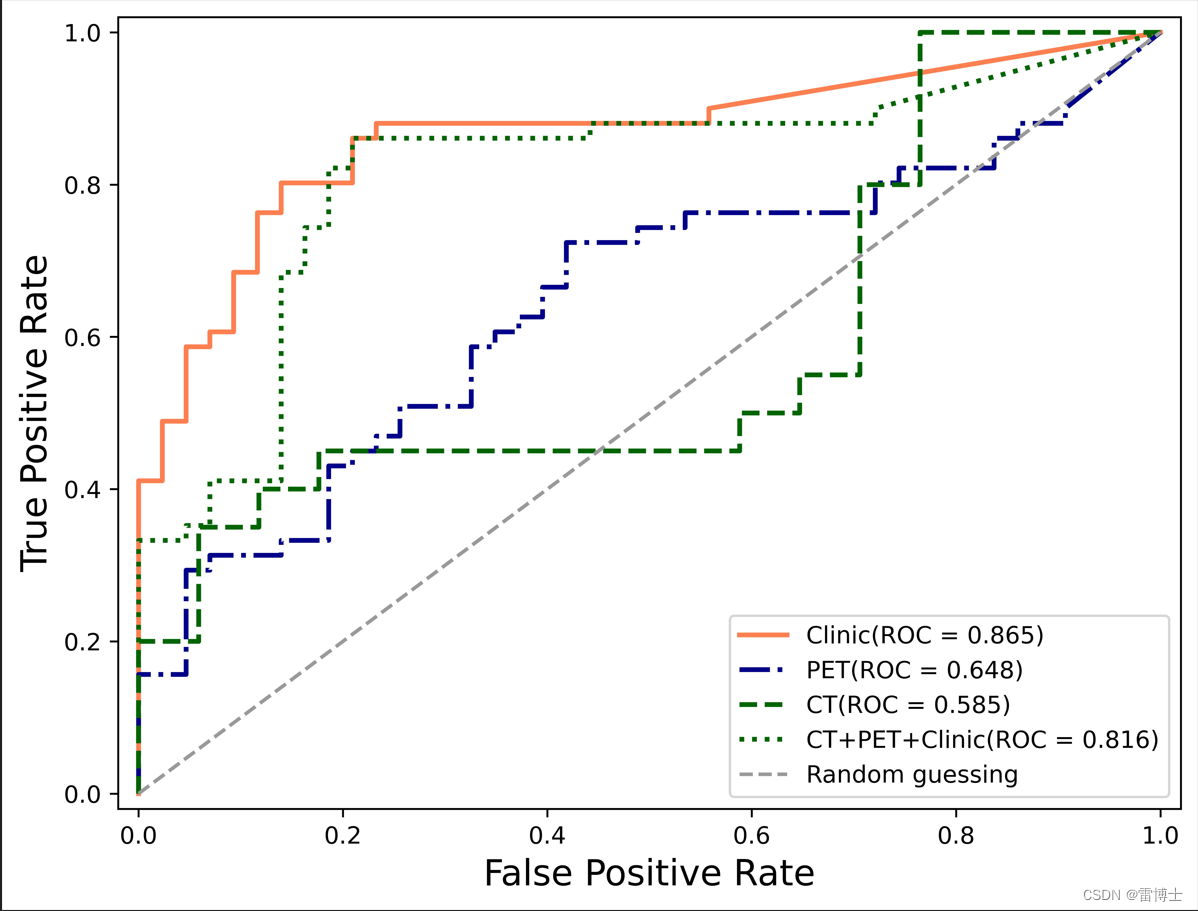
3 ROC曲线评估
要绘制ROC曲线,首先需要计算真正率(True Positive Rate,也称召回率)和假正率(False Positive Rate)。在代码中,可以通过使用模型的预测概率值和真实标签来计算这些指标。
def evaluate_model(y_test, y_pred):
"""
评估分类器模型的性能,并打印相关指标。
Parameters:
- X_test: 测试集的特征矩阵
- y_test: 测试集的目标变量
"""
# 准确率
acc = accuracy_score(y_test, y_pred)
print(f'准确率:{acc:.4f}')
# 分类报告
print('\n分类报告:')
report = classification_report(y_test, y_pred)
print(report)
# 混淆矩阵
print('混淆矩阵:')
cm = confusion_matrix(y_test, y_pred)
print(cm)
# ROC 曲线和 AUC
if len(set(y_test)) == 2: # 二分类才绘制 ROC 曲线和计算 AUC
auc = roc_auc_score(y_test,y_pred)
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制 ROC 曲线
fpr, tpr, _ = roc_curve(y_test,y_pred)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {auc:.4f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC 曲线')
plt.legend(loc='lower right')
plt.show()
获得的ROC示意图曲线如图:
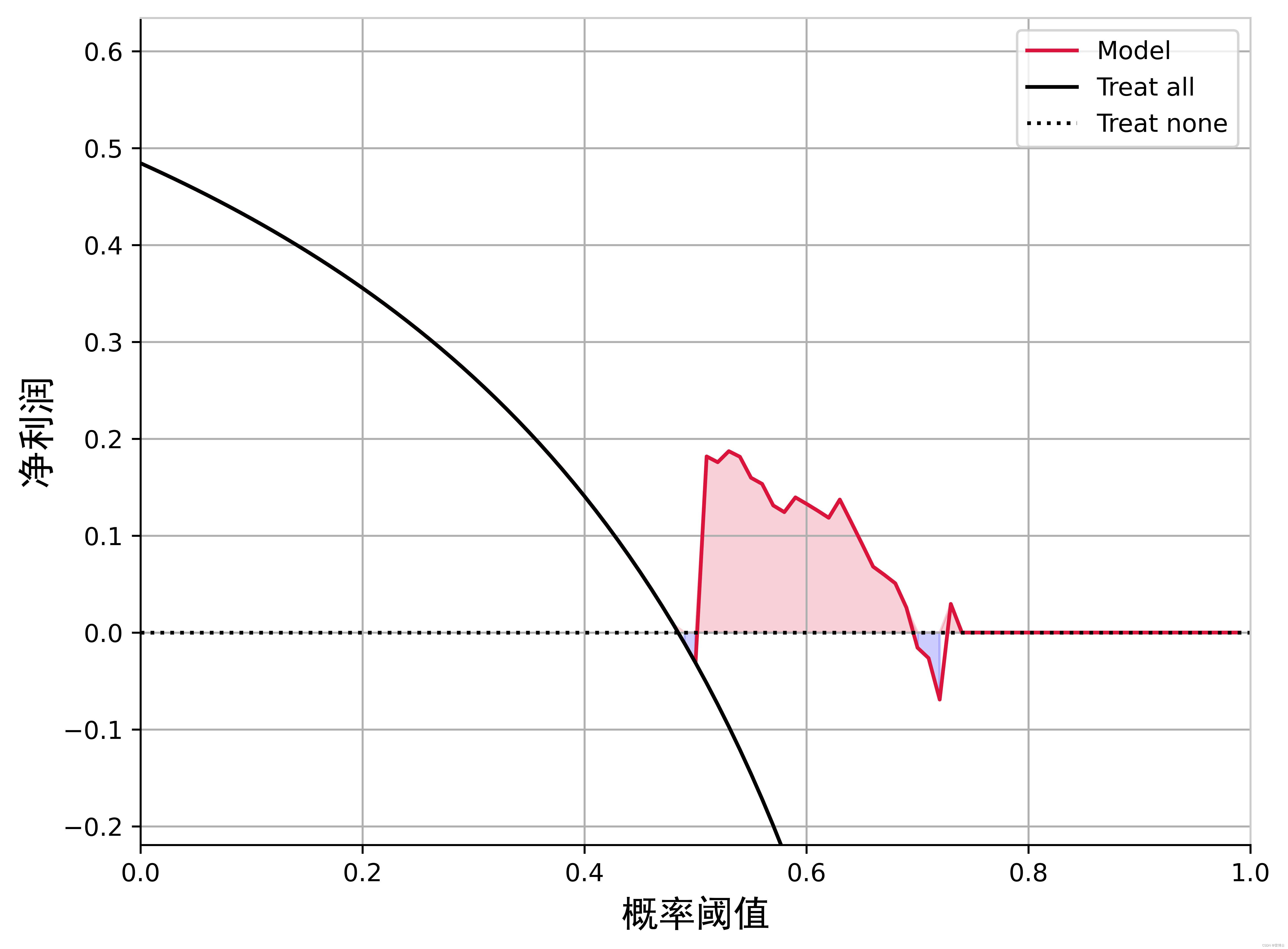
4 决策收益分析曲线,混淆矩阵
混淆矩阵(Confusion Matrix)是一种用于评估分类模型性能的表格,它将模型预测的结果与实际的类别标签进行比较,从而展现模型的分类准确性。混淆矩阵是一个二维矩阵,通常是一个正方形矩阵,其行代表了真实的类别,列代表了模型预测的类别。
def plt_confusion_matrix(cm,save_path = False):
# 混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False,
xticklabels=['Predicted 0', 'Predicted 1'],
yticklabels=['Actual 0', 'Actual 1'])
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
# 保存图片
if save_path:
plt.savefig(save_path, dpi=800, bbox_inches='tight')
plt.show()
运行的结果示意图如图

如图
收益分析曲线(Profit Curve)是一种用于评估分类模型性能的可视化工具,它将模型的预测结果与实际的成本和收益联系起来,从而帮助决策者在不同阈值下进行决策。
笑话一则开心一下喽
什么是代沟?就是换上新衣服,在老妈面前走了一圈说:妈,有范吗?老妈看了我一眼说:有,在锅里,自己盛去。
深度学习,医学图像处理,机器学习,需要帮助的联系我(有偿哦)
















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









