







1.Why为什么要进行数据预处理
坊间传言,工业界大部分机器学习、数据挖掘业务80%在倒腾数据,20%在研究算法。
- 数据质量不高,再好的模型也没用
- 数据没问题,但因为一些形式的问题,一些模型也会不work,比如说LR、SVM、DNN都对数据预处理有很高的要求,处理的好与不好最终结果差距很大。当然就笔者的经验而言,貌似基于树的模型貌似对这块不是很敏感。
上面的话可能有点泛泛而谈,下面的例子可能会给读者更深的体会
(1)将淘宝上商品标题分词,然后使用TFIDF作为特征值。其实,我们可以通过对TFIDF值进行一个log转换作为特征值,往往效果会更好。(原因:淘宝商品的标题分词已经比较具体了,词与词的TFIDF值差距比较大)
(2)下面是sklearn里面Preprocessing模块的一段话,从原理上更加深入地解释了数据预处理的重要性。
For instance, many elements used in the objective function of a learning algorithm (such as the RBF kernel of Support Vector Machines or the l1 and l2 regularizers of linear models) assume that all features are centered around zero and have variance in the same order. If a feature has a variance that is orders of magnitude larger that others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected.
2.How如何数据预处理
在实际的业务场景下,预处理方法可能不尽相同,这里就sklearn里面Preprocessing模块一些常用的数据预处理方法进行介绍。
(1)归一化
(1)MinMaxScaler,计算方式是特征值减去最小值除以最大值减去最小值
下面进行一个简单的演示
import numpy as np
from sklearn import preprocessing
X_train = np.array([[ 1, -1, 2],[ 2, 0, 0],[ 0, 1, -1]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_test = np.array([[ -3., -1., 4.]])
X_test_minmax = min_max_scaler.transform(X_test)ipython notebook上的输出结果
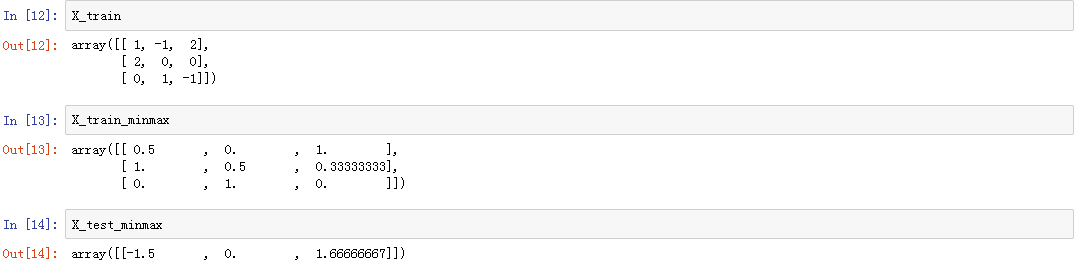
细心的你有没有发现X_test_minmax居然有大于1(小于0)的值。
此时,我们可以通过如下代码进行处理,下面介绍的一些归一化方法同样可以通过类似操作。
import numpy as np
from sklearn import preprocessing
X_train = np.array([[ 1, -1, 2],[ 2, 0, 0],[ 0, 1, -1]])
X_test = np.array([[ -3., -1., 4.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_all = np.vstack((X_train, X_test))
min_max_scaler.fit(X_all)
X_train_minmax = min_max_scaler.transform(X_train)
X_test_minmax = min_max_scaler.transform(X_test)
(2)StandardScaler,也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差
下面介绍两个函数
preprocessing.scale 标准正太分布,均值为0,方差为1
preprocessing.StandardScaler Z-score计算方式
用法与上面的MinMaxScaler一样,这里不赘述。
(3)normalize (可以是L1范式或者L2范式)

可以这样理解(存在一点精度损失)

(2)类别特征编码
如下图
第一列特征只有两种取值,第二列特征有三种取值,第三列特征有四种取值。
所以,对于数据[0,1,3],我们可以
用1,0表示0,
用0,1,0表示1
用0,0,01表示3

(3)生成多项式特征
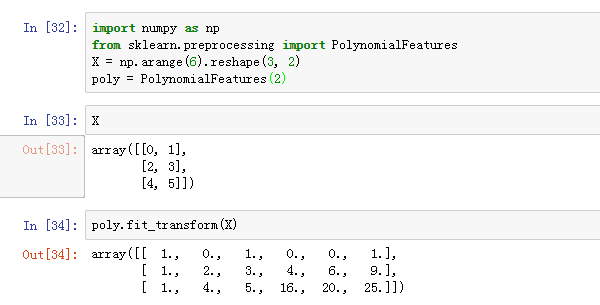
The features of X have been transformed from (X_1, X_2) to (1, X_1, X_2, X_1^2, X_1X_2, X_2^2).
(4)自定义预处理模式
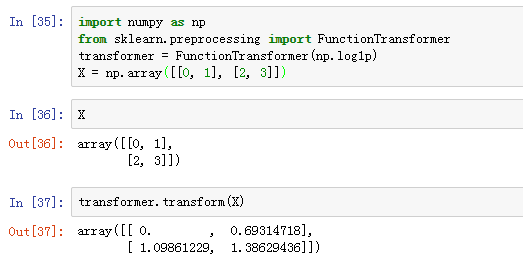
更多详细内容可以参考 http://scikit-learn.org/stable/modules/preprocessing.html#preprocessing

















 7038
7038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









